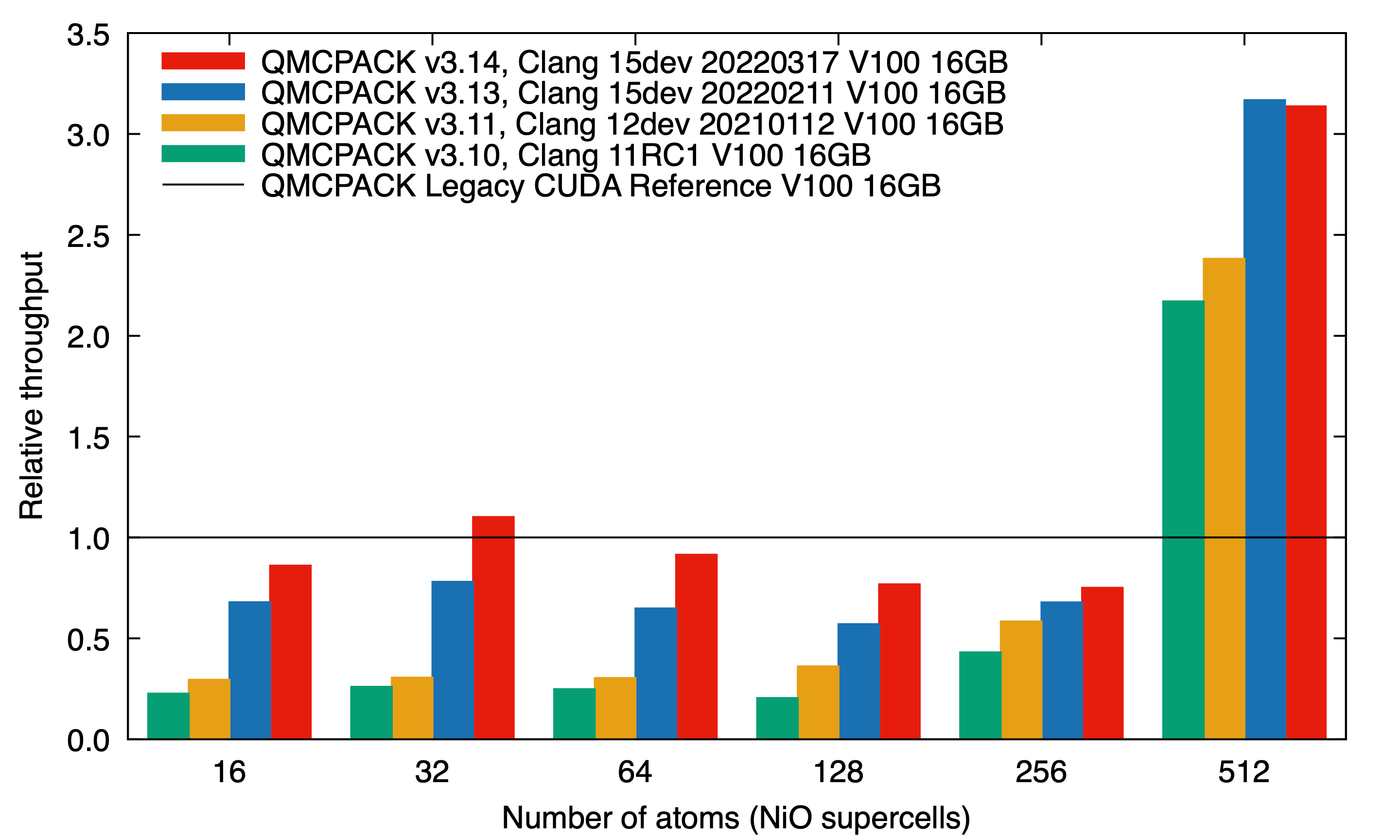
Figure 4. Performance of the new batched offload implementation in QMCPACK now rivals the legacy CUDA version. Shown is throughput relative to this version vs. number of atoms for a broad range of problems. The different datasets show the progression made with new QMCPACK versions and with improvements in LLVM’s OpenMP implementation.