The IDEAS Productivity project, in partnership with the DOE Computing Facilities of the ALCF, OLCF, and NERSC and the DOE Exascale Computing Project (ECP) has resumed the webinar series on Best Practices for HPC Software Developers, which we began in 2016.
As part of this series, we offer one-hour webinars on topics in scientific software development and high-performance computing, approximately once a month. The July webinar is titled Mining Development Data to Understand and Improve Software Engineering Processes in HPC Projects, and will be presented by Boyana Norris (University of Oregon). The webinar will take place on Wednesday, July 7, 2021 at 1:00 pm ET.
Abstract:
The webinar will explore the role of software-related data mining tools in supporting productive development of high-performance scientific software. The webinar will discuss a variety of existing and emerging tools for analyzing code, git, emails, issues, test results, and dependencies, with the long-term goal of improving the understanding of development processes and enhancing developer productivity. The webinar will include specific analysis examples by applying a subset of those tools to ECP projects.
Argonne Training Program on Extreme-Scale Computing
Call for 2021 Applications EXTENDED
The Argonne Training Program on Extreme-Scale Computing (ATPESC) provides intensive, two-week training on the key skills, approaches, and tools to design, implement, and execute computational science and engineering applications on current high-end computing systems and the leadership-class computing systems of the future.
The core of the program will focus on programming methodologies that are effective across a variety of supercomputers and that are expected to be applicable to exascale systems. Additional topics to be covered include computer architectures, mathematical models and numerical algorithms, approaches to building community codes for HPC systems, and methodologies and tools relevant for Big Data applications.
Doctoral students, postdocs, and computational scientists interested in attending ATPESC can review eligibility and application details on the application instructions web page.
The event will be held in the Chicago area. If an in-person meeting is not possible, it will be held as a virtual event.
Note: There are no fees to participate. Domestic airfare, meals, and lodging are provided.
IMPORTANT DATES – ATPESC 2021
- March 5, 2021 (midnight, Anywhere on Earth) – Extended deadline to submit applications
- April 26, 2021 – Notification of acceptance
- May 3, 2021 – Account application deadline
For more information see https://extremecomputingtraining.anl.gov or contact [email protected]
The IDEAS Productivity project, in partnership with the DOE Computing Facilities of the ALCF, OLCF, and NERSC and the DOE Exascale Computing Project (ECP) has resumed the webinar series on Best Practices for HPC Software Developers, which we began in 2016.
As part of this series, we offer one-hour webinars on topics in scientific software development and high-performance computing, approximately once a month. The August webinar is titled Software Engineering Challenges and Best Practices for Multi-Institutional Scientific Software Development, and will be presented by Keith Beattie (Lawrence Berkeley National Laboratory). The webinar will take place on Wednesday, August 4, 2021 at 1:00 pm ET.
Abstract:
Scientific software is increasingly becoming the backbone of obtaining and validating scientific results. This is no longer just the case for traditionally computationally intensive areas but is now true across a wide variety of scientific disciplines. This circumstance elevates how scientific software is developed, independent of the field, to a new level of importance. Further, the multi-institutional nature of many science projects presents unique challenges to how scientific software can be effectively developed and maintained over the long term. In this webinar we present the challenges faced in leading the development of scientific software across a distributed, multi-institutional team of contributors, and we describe a set of best-practices we have found to be effective in producing impactful and trustworthy scientific software.
1st Variorum Lecture Series August 2021
The Variorum team will provide its first Variorum Lecture Series, where attendees will learn everything necessary to start using Variorum on various platforms to write portable power management code. The team will provide support through GitHub and Variorum mailing list during and after the lecture series. This Variorum Lecture Series will consist of two modules, each of 1.5 hours each. We will hold two sessions to accommodate different time zones as well as attendee schedules.
-
Module 1: August 6, 8:30am-10:00am PT / 11:30am-1:00pm ET, targeting US/European attendees, and August 20, 4:00pm-5:30pm PT / 7:00pm-8:30pm ET, targeting US/Asian attendees.
Module 2: August 13, 8:30am-10:00am PT / 11:30am-1:00pm ET, targeting US/European attendees, and August 27, 4:00pm-5:30pm PT / 7:00pm-8:30pm ET, targeting US/Asian attendees.
What is Variorum?
Variorum is a production-grade, open-source, vendor-neutral software infrastructure for exposing low-level control and monitoring of a system’s underlying hardware features. It can easily be ported to different hardware devices, as well as different generations within a particular device. This allows users to manage power, performance and thermal information seamlessly across hardware from different vendors. More specifically, Variorum’s flexible design supports a set of features that may exist on one generation of hardware, but not on another. Variorum can also be included as part of the system software stack for power management: such as runtime systems, resource managers, and other profiling tools. At present, Variorum supports 5 platforms (IBM, Intel, AMD, ARM and NVIDIA) and a total of ten microarchitectures across these platforms.
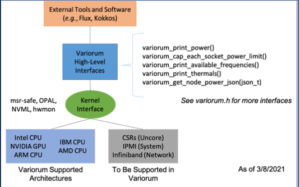
Contents of the Lectures
Module 1: Introduction to Variorum
- Challenges in Power Management and The HPC Power Stack
- Understanding Power Management Knobs on Intel, IBM, NVIDIA, ARM, and AMD platforms
- Variorum Library
- Build, dependencies, and setup
- Monitoring user applications non-intrusively
- Vendor-neutral Variorum API across diverse architectures
- Using Variorum for finer-grained monitoring, power capping, and management
Module 2: Integrating Variorum with System Software and Tools
- The HPC Power Stack revisited: need for power management at various levels
- GEOPM: job-level power management
- Kokkos and Caliper: application and workflow power management
- SLURM (Research Extensions): system-level power management
- Upcoming Features in Variorum
- The HPC Power Stack Roadmap
How to Attend
- The lecture series is available to everyone, and participants are welcome to attend any/all sessions.
- No-cost registration is necessary, meeting link and password will be sent to registrants. See “Tickets” above.
- Presenters will show in-depth demos during the lecture series. Presenters can provide support during and after the lecture series with setup and usage on supported architectures.
Presenters
- Stephanie Brink, Tapasya Patki, Aniruddha Marathe and Barry Rountree (Lawrence Livermore National Laboratory)
Module 1
Module 2
Due to the great interest that this training attracted, we are unable to accommodate additional participants and registration is now closed.
The training class will be virtual and will use computational resources available at NERSC for the exercises. The tentative agenda for the training is given below. The training is targeted at a deeper understanding of CMake. It seeks to assist ECP developers in learning how to resolve issues outside of their control, in addition to writing a build system generator capable of seamlessly configuring for multiple unique architectures with a variety of compilers.Tentative Agenda
Session #1: Monday, August 23, 12pm – 4pm ET
— Kitware Background
— CMake Background
- What it is
- Why it exists
- Why you should use it
— Introduction to CMake
— Resources for learning CMake
- How to install CMake
- How to run CMake on existing projects
- CMake workflow
- Exercise: run cmake-gui, ccmake and cmake
— Commands and Variables
- CMake basic syntax
- CMake commands
- CMake variables
- Configuring header files
- Requiring a CMake version
- Language levels ( c++11/14/17/20 )
- Exercise: configure a file and C++11 controls
- Flow control
- Variable scope
- Functions/macros
- CMake cache variables
- Compiler options
- Build configurations (debug vs. release)
- CMake presets
— Libraries
- Different types of libraries: shared/static/object/module
- Linking & specifying dependencies
- Exercise: adding a library
- Usage requirements / modern CMake
- Exercise: usage requirements
— Speeding up your Builds
Session #2: Tuesday, August 24, 12pm – 4pm ET
— Install rules
— Testing with CMake
- CTest features
- Multi core tests
- Test resource allocation
- Exercise: installing and testing
— System Introspection
- Using find modules
- Using config modules
- Writing find modules
- Understanding find module search order
- Debugging find modules
- Include command
- Exercise: system introspection
— Build Artifact Controls
— Custom Commands
- Exercise: custom command and generated file
— CMake Scripting
— Using CPack to create installers
- Exercise: building an installer
— Reporting build/test results to CDash
- Feature overview
- Coverage
- Static analysis
- Dynamic analysis
- Exercise: submitting results to a dashboard
Session #3: Wednesday, August 25, 12pm – 4pm ET
— Mixing Library Types
— Symbol Visibility
— Library Visibility
- Exercise: mixing static and shared
— Generator Expressions
- Exercise: using generator expressions
— Importing & Exporting Targets
- Exercise: export configuration
— CMake’s Policy System
— MPI Support
— CUDA Support
— Cross Compilation
— External Project & Fetch Content
— Fortran Support
— Noteworthy changes from recent CMake releases
Session #4: Thursday, August 26, 12pm – 4pm ET
— Office hours / Q&A session
Slides and recordings will be available after the classes.
Due to the great interest that this training attracted, we are unable to accommodate additional participants and registration is now closed.
The training class will be virtual and will use computational resources available at NERSC for the exercises. The tentative agenda for the training is given below. The training is targeted at a deeper understanding of CMake. It seeks to assist ECP developers in learning how to resolve issues outside of their control, in addition to writing a build system generator capable of seamlessly configuring for multiple unique architectures with a variety of compilers.Tentative Agenda
Session #1: Monday, August 23, 12pm – 4pm ET
— Kitware Background
— CMake Background
- What it is
- Why it exists
- Why you should use it
— Introduction to CMake
— Resources for learning CMake
- How to install CMake
- How to run CMake on existing projects
- CMake workflow
- Exercise: run cmake-gui, ccmake and cmake
— Commands and Variables
- CMake basic syntax
- CMake commands
- CMake variables
- Configuring header files
- Requiring a CMake version
- Language levels ( c++11/14/17/20 )
- Exercise: configure a file and C++11 controls
- Flow control
- Variable scope
- Functions/macros
- CMake cache variables
- Compiler options
- Build configurations (debug vs. release)
- CMake presets
— Libraries
- Different types of libraries: shared/static/object/module
- Linking & specifying dependencies
- Exercise: adding a library
- Usage requirements / modern CMake
- Exercise: usage requirements
— Speeding up your Builds
Session #2: Tuesday, August 24, 12pm – 4pm ET
— Install rules
— Testing with CMake
- CTest features
- Multi core tests
- Test resource allocation
- Exercise: installing and testing
— System Introspection
- Using find modules
- Using config modules
- Writing find modules
- Understanding find module search order
- Debugging find modules
- Include command
- Exercise: system introspection
— Build Artifact Controls
— Custom Commands
- Exercise: custom command and generated file
— CMake Scripting
— Using CPack to create installers
- Exercise: building an installer
— Reporting build/test results to CDash
- Feature overview
- Coverage
- Static analysis
- Dynamic analysis
- Exercise: submitting results to a dashboard
Session #3: Wednesday, August 25, 12pm – 4pm ET
— Mixing Library Types
— Symbol Visibility
— Library Visibility
- Exercise: mixing static and shared
— Generator Expressions
- Exercise: using generator expressions
— Importing & Exporting Targets
- Exercise: export configuration
— CMake’s Policy System
— MPI Support
— CUDA Support
— Cross Compilation
— External Project & Fetch Content
— Fortran Support
— Noteworthy changes from recent CMake releases
Session #4: Thursday, August 26, 12pm – 4pm ET
— Office hours / Q&A session
Slides and recordings will be available after the classes.
Due to the great interest that this training attracted, we are unable to accommodate additional participants and registration is now closed.
The training class will be virtual and will use computational resources available at NERSC for the exercises. The tentative agenda for the training is given below. The training is targeted at a deeper understanding of CMake. It seeks to assist ECP developers in learning how to resolve issues outside of their control, in addition to writing a build system generator capable of seamlessly configuring for multiple unique architectures with a variety of compilers.Tentative Agenda
Session #1: Monday, August 23, 12pm – 4pm ET
— Kitware Background
— CMake Background
- What it is
- Why it exists
- Why you should use it
— Introduction to CMake
— Resources for learning CMake
- How to install CMake
- How to run CMake on existing projects
- CMake workflow
- Exercise: run cmake-gui, ccmake and cmake
— Commands and Variables
- CMake basic syntax
- CMake commands
- CMake variables
- Configuring header files
- Requiring a CMake version
- Language levels ( c++11/14/17/20 )
- Exercise: configure a file and C++11 controls
- Flow control
- Variable scope
- Functions/macros
- CMake cache variables
- Compiler options
- Build configurations (debug vs. release)
- CMake presets
— Libraries
- Different types of libraries: shared/static/object/module
- Linking & specifying dependencies
- Exercise: adding a library
- Usage requirements / modern CMake
- Exercise: usage requirements
— Speeding up your Builds
Session #2: Tuesday, August 24, 12pm – 4pm ET
— Install rules
— Testing with CMake
- CTest features
- Multi core tests
- Test resource allocation
- Exercise: installing and testing
— System Introspection
- Using find modules
- Using config modules
- Writing find modules
- Understanding find module search order
- Debugging find modules
- Include command
- Exercise: system introspection
— Build Artifact Controls
— Custom Commands
- Exercise: custom command and generated file
— CMake Scripting
— Using CPack to create installers
- Exercise: building an installer
— Reporting build/test results to CDash
- Feature overview
- Coverage
- Static analysis
- Dynamic analysis
- Exercise: submitting results to a dashboard
Session #3: Wednesday, August 25, 12pm – 4pm ET
— Mixing Library Types
— Symbol Visibility
— Library Visibility
- Exercise: mixing static and shared
— Generator Expressions
- Exercise: using generator expressions
— Importing & Exporting Targets
- Exercise: export configuration
— CMake’s Policy System
— MPI Support
— CUDA Support
— Cross Compilation
— External Project & Fetch Content
— Fortran Support
— Noteworthy changes from recent CMake releases
Session #4: Thursday, August 26, 12pm – 4pm ET
— Office hours / Q&A session
Slides and recordings will be available after the classes.
Due to the great interest that this training attracted, we are unable to accommodate additional participants and registration is now closed.
The training class will be virtual and will use computational resources available at NERSC for the exercises. The tentative agenda for the training is given below. The training is targeted at a deeper understanding of CMake. It seeks to assist ECP developers in learning how to resolve issues outside of their control, in addition to writing a build system generator capable of seamlessly configuring for multiple unique architectures with a variety of compilers.Tentative Agenda
Session #1: Monday, August 23, 12pm – 4pm ET
— Kitware Background
— CMake Background
- What it is
- Why it exists
- Why you should use it
— Introduction to CMake
— Resources for learning CMake
- How to install CMake
- How to run CMake on existing projects
- CMake workflow
- Exercise: run cmake-gui, ccmake and cmake
— Commands and Variables
- CMake basic syntax
- CMake commands
- CMake variables
- Configuring header files
- Requiring a CMake version
- Language levels ( c++11/14/17/20 )
- Exercise: configure a file and C++11 controls
- Flow control
- Variable scope
- Functions/macros
- CMake cache variables
- Compiler options
- Build configurations (debug vs. release)
- CMake presets
— Libraries
- Different types of libraries: shared/static/object/module
- Linking & specifying dependencies
- Exercise: adding a library
- Usage requirements / modern CMake
- Exercise: usage requirements
— Speeding up your Builds
Session #2: Tuesday, August 24, 12pm – 4pm ET
— Install rules
— Testing with CMake
- CTest features
- Multi core tests
- Test resource allocation
- Exercise: installing and testing
— System Introspection
- Using find modules
- Using config modules
- Writing find modules
- Understanding find module search order
- Debugging find modules
- Include command
- Exercise: system introspection
— Build Artifact Controls
— Custom Commands
- Exercise: custom command and generated file
— CMake Scripting
— Using CPack to create installers
- Exercise: building an installer
— Reporting build/test results to CDash
- Feature overview
- Coverage
- Static analysis
- Dynamic analysis
- Exercise: submitting results to a dashboard
Session #3: Wednesday, August 25, 12pm – 4pm ET
— Mixing Library Types
— Symbol Visibility
— Library Visibility
- Exercise: mixing static and shared
— Generator Expressions
- Exercise: using generator expressions
— Importing & Exporting Targets
- Exercise: export configuration
— CMake’s Policy System
— MPI Support
— CUDA Support
— Cross Compilation
— External Project & Fetch Content
— Fortran Support
— Noteworthy changes from recent CMake releases
Session #4: Thursday, August 26, 12pm – 4pm ET
— Office hours / Q&A session
Slides and recordings will be available after the classes.
1st Variorum Lecture Series August 2021
The Variorum team will provide its first Variorum Lecture Series, where attendees will learn everything necessary to start using Variorum on various platforms to write portable power management code. The team will provide support through GitHub and Variorum mailing list during and after the lecture series. This Variorum Lecture Series will consist of two modules, each of 1.5 hours each. We will hold two sessions to accommodate different time zones as well as attendee schedules.
-
Module 1: August 6, 8:30am-10:00am PT / 11:30am-1:00pm ET, targeting US/European attendees, and August 20, 4:00pm-5:30pm PT / 7:00pm-8:30pm ET, targeting US/Asian attendees.
Module 2: August 13, 8:30am-10:00am PT / 11:30am-1:00pm ET, targeting US/European attendees, and August 27, 4:00pm-5:30pm PT / 7:00pm-8:30pm ET, targeting US/Asian attendees.
What is Variorum?
Variorum is a production-grade, open-source, vendor-neutral software infrastructure for exposing low-level control and monitoring of a system’s underlying hardware features. It can easily be ported to different hardware devices, as well as different generations within a particular device. This allows users to manage power, performance and thermal information seamlessly across hardware from different vendors. More specifically, Variorum’s flexible design supports a set of features that may exist on one generation of hardware, but not on another. Variorum can also be included as part of the system software stack for power management: such as runtime systems, resource managers, and other profiling tools. At present, Variorum supports 5 platforms (IBM, Intel, AMD, ARM and NVIDIA) and a total of ten microarchitectures across these platforms.
Contents of the Lectures
Module 1: Introduction to Variorum
- Challenges in Power Management and The HPC Power Stack
- Understanding Power Management Knobs on Intel, IBM, NVIDIA, ARM, and AMD platforms
- Variorum Library
- Build, dependencies, and setup
- Monitoring user applications non-intrusively
- Vendor-neutral Variorum API across diverse architectures
- Using Variorum for finer-grained monitoring, power capping, and management
Module 2: Integrating Variorum with System Software and Tools
- The HPC Power Stack revisited: need for power management at various levels
- GEOPM: job-level power management
- Kokkos and Caliper: application and workflow power management
- SLURM (Research Extensions): system-level power management
- Upcoming Features in Variorum
- The HPC Power Stack Roadmap
How to Attend
- The lecture series is available to everyone, and participants are welcome to attend any/all sessions.
- No-cost registration is necessary, meeting link and password will be sent to registrants. See “Tickets” above.
- Presenters will show in-depth demos during the lecture series. Presenters can provide support during and after the lecture series with setup and usage on supported architectures.
Presenters
- Stephanie Brink, Tapasya Patki, Aniruddha Marathe and Barry Rountree (Lawrence Livermore National Laboratory)
Module 1
Module 2
Abstract:
Extreme-Scale Scientific Software Stack (E4S) is a collection of open-source software packages for running scientific application typically run on HPC systems. E4S is a collection of spack packages that is built collectively with a fixed version of spack on a quarterly basis. So far, we have deployed E4S on Cori and Summit, and in the coming months we will have E4S deployed on Perlmutter, Spock, and Aurora. As part of the facility deployment, we need a mechanism to test the software stack and increase test coverage that properly tests the software at the facility.
E4S Testsuite is a validation testsuite for E4S products, which is a collection of shell scripts, makefiles, source code that runs tests on a facility deployed spack stack. Spack recently added support to run standalone tests for spack packages via spack test command which allows one to specify tests in their spack packages that can be run post-deployment.
Buildtest is a HPC testing framework designed to help facilities develop and run tests to validate their system and software stack. In buildtest, tests are written in YAML template called buildspecs which are processed by buildtest into shell-scripts. Buildtest has support for job submission to Slurm, LSF, PBS and Cobalt scheduler. Buildtest supports a rich YAML structure for writing buildspecs that is validated by a JSON Schema. Furthermore, buildtest provides numerous commands to query test results, inspect a particular test, validate buildspecs and find buildspecs through its buildspec cache. In v0.10.0, buildtest added support for spack schema to allow one to write buildspecs that can leverage spack to install specs, manage spack environments, and run spack test.
The presentation will provide a brief overview of buildtest commands and how to write tests in buildspecs, followed by a demo. The presentation will include an overview of Cori testsuite, which is a repository that contains sanity test for the Cori system including E4S tests using E4S tests. Gitlab is used to help automate execution of tests which are pushed to CDASH for post-processing. The presentation will end with a summary of E4S tests that are run on Cori, as well as current challenges.
References:
- Buildtest Documentation
- Schema Documentation
- Getting Started
- Writing Buildspecs
- Summary of buildtest
- E4S Testsuite
- Slack Channel
- E4S at NERSC
- E4S at OLCF
Presenter: Shahzeb Mohammed Siddiqui (NERSC)