A team collaborating across national laboratories, universities, and industry has developed a new approach to runtime programming that enables scalable execution of implicitly parallel programs on large-scale machines using distributed dynamic dependence analysis for efficient, on-the-fly computation of dependences. Dynamic control replication distributes dependence analysis by executing multiple copies of an implicitly parallel program while ensuring the copies collectively behave as a single execution. The researchers also presented an asymptotically scalable algorithm for implementing dynamic control replication that maintains the sequential semantics of implicitly parallel programs. Their work was published in the proceedings of PPoPP ‘21, the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming.
Implicitly parallel programming models, in which apparently sequential programs are automatically parallelized, are becoming increasingly popular as programmers, who often to have limited experience writing explicitly parallel code, attempt to solve computationally difficult problems using massively parallel and distributed machines. This is particularly true for data-centric computing needs across an ever-growing number of marketplaces. Because the number of tasks to be analyzed is generally proportional to the size of the target machine, dependence analysis is expensive at scale, and its apparently sequential nature can make it difficult to parallelize. Implementing their method in Legion runtime, the team showed that dynamic control replication delivers the same programmer productivity as other implicitly parallel programming models, up to 15× better performance, and scalability to hundreds of nodes while supporting arbitrary control flow, data usage, and task execution on any node. These findings are competitive with explicitly parallel programming systems and prove the method’s usefulness with high-performance computing applications including machine learning and deep learning.
This work, which enables users unaccustomed to programming for massive parallelism to tackle computationally difficult programs, represents an important component of a successful, capable exascale computing ecosystem for nontraditional HPC users. The team’s approach also allows data-centric workloads to run significantly faster and outperforms industry standards. Projects such as CANDLE, which applies deep learning techniques to cancer research challenges, are expected to benefit. Follow-on work will provide new optimizations for machine learning workloads using additional forms of parallelism unique for a given network and system architecture, optimization of operators within deep neural networks, and interfaces to productivity-focused programming using languages such as Python and R.
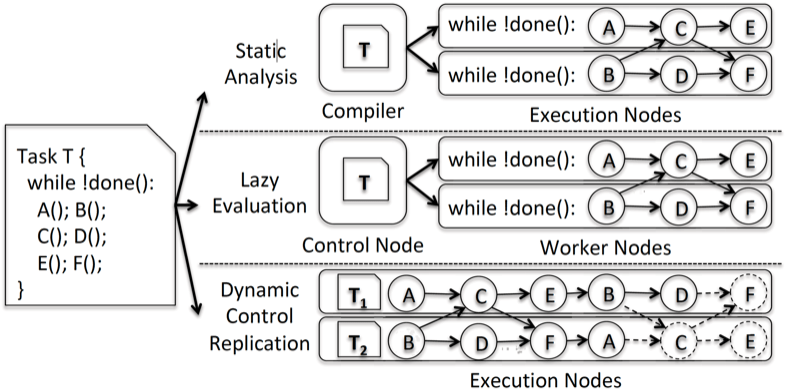
Approaches to implicit parallelism. Static analysis and lazy evaluation centralize analysis and distribute partitioned programs to workers for execution. Dynamic control replication executes a replicated program, dynamically assigns tasks to shards (partitions) of data, and performs an on-the-fly distributed dependence analysis.
Bauer, Michael, Wonchan Lee, Elliott Slaughter, Zhihao Jia, Mario Di Renzo, Manolis Papadakis, Galen Shipman, Patrick McCormick, Michael Garland, and Alex Aiken. “Scaling Implicit Parallelism via Dynamic Control Replication.” 2021. PPoPP ‘21: Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (February).
https://doi.org/10.1145/3437801.3441587