By Rob Farber, contributing writer
The Extreme-Scale Scientific Software Stack (E4S) is the delivery vehicle for hardened and robust Exascale Computing Project (ECP) reusable libraries and tools.[1] With it, users can install images or containerized deployments both on premises or in the cloud. E4S also provides a rich set of outreach, strategy, and testing resources built around its deployment capabilities that include testing, a documentation portal, and a strategy group (Figure 1).

Figure 1. Current E4S features.
E4S is a hugely beneficial project that provides easy access to over 100 high-performance computing (HPC), AI, and high-performance data analytics (HPDA) supported packages and commercial tools—all of which are ready for bare-metal and containerized deployment (including on commercial cloud providers) for a variety of CPU types and heterogenous HPC architectures, including systems running GPUs from AMD, NVIDIA, and Intel.
To simplify life for users, the E4S dashboard provides a single portal view of facility deployments, build issues, and current and resolved trouble ticket reporting for all systems. Quarterly releases ensure that E4S keeps pace with emerging technologies and quickly addresses bugs, and E4S 23.02 was released on February 28, 2023.
Continuous integration (CI) is critical to ensuring run-time correctness and performance portability.[2] Again, E4S makes this easy for the user through an extensive behind-the-scenes effort. The URL https://stats.e4s.io/ shows that over 3 million CI jobs have been run to date. This resource-intensive CI effort is a collaboration between E4S/UO, the Spack team, Kitware, and Amazon Web Services (AWS), who are providing much of the cloud cycles and infrastructure.
E4S is a dynamic project working to make deployments easier for users. For example, the E4S team is developing a new tool called e4s-alc, which permits an à la carte selection of Spack and system packages to build custom compact container images. Not only does this tool save time, but the compact containers can also significantly reduce resource consumption during run time.
Information about the wealth of the E4S-supported HPC resources has been disseminated to the US Department of Energy (DOE) and the global HPC community through tutorials and outreach efforts. As Project Leader and Director of Software Technology for the ECP, Dr. Mike Heroux, noted, “E4S is open and inclusive. Projects can join and become first-class citizens simply by showing that the software can be built and satisfy the core community policies. We are still building the community, and we invite any interested members of the scientific and HPC communities to join us as partners to provide excellent software both effectively and efficiently.”[3]
E4S is open and inclusive. Projects can join and become first-class citizens simply by showing that the software can be built and satisfy the core community policies. We are still building the community, and we invite any interested members of the scientific and HPC communities to join us as partners to provide excellent software both effectively and efficiently. — Mike Heroux
James Willenbring, PI for the Software Ecosystem and Delivery Software Development Kit (SDK) and senior member of R&D technical staff in the Center for Computing Research at Sandia National Laboratories explained further, “The E4S Community Policies can be thought of as membership criteria. The policies are not designed to be an exhaustive set of software quality measurements, but rather they touch on key areas of software development that position products for successful participation in the E4S software ecosystem as well as for continuous process and quality improvement.”
The E4S Community Policies can be thought of as membership criteria. The policies are not designed to be an exhaustive set of software quality measurements, but rather they touch on key areas of software development that position products for successful participation in the E4S software ecosystem as well as for continuous process and quality improvement. — James Willenbring
E4S provides a very broad range of delivery methods, including container images, build manifests, and turn-key, from-source builds of popular HPC software packages developed as SDKs. This broad effort includes programming models and run times (MPICH, Kokkos, RAJA, OpenMPI), development tools (TAU, PAPI), math libraries (PETSc, Trilinos), data and visualization tools (Adios, HDF5, Paraview), and compilers (LLVM), all of which are available through the Spack package manager. The team is actively offering tutorials and community engagements and interactions at various locations and conferences.
Technical Introduction
In the past, the responsibility for building and deploying an HPC application was left to the developer or systems management team. Sameer Shende (Figure 2), research professor and director of the Performance Research Laboratory at the Oregon Advanced Computing Institute for Science and Society, noted, “The E4S project addresses the huge gap in HPC deployment incurred by the legacy patchwork build-and-deploy model, which compelled the need for a centralized project such as E4S.”
The E4S project addresses the huge gap in HPC deployment incurred by the legacy patchwork build-and-deploy model, which compelled the need for a centralized project such as E4S. — Sameer Shende

Figure 2. Sameer Shende.
A centralized, standardized build-and-deploy framework saves both time and money, makes the ECP software available to the world, addresses build and installation problems, including version lock-in and the need for reliable software upgrades, and overcomes barriers to expand user access to HPC datacenters and ECP scalable software.
Mandated by Complexity
The increasing complexity and sophistication of HPC applications have made the previous legacy patchwork approach cost prohibitive. Consider the complexity of the dependency graphs for three representative HPC applications, as shown in Figure 3. The build and deployment process for such complex dependency trees can be inhibitive for individual groups.
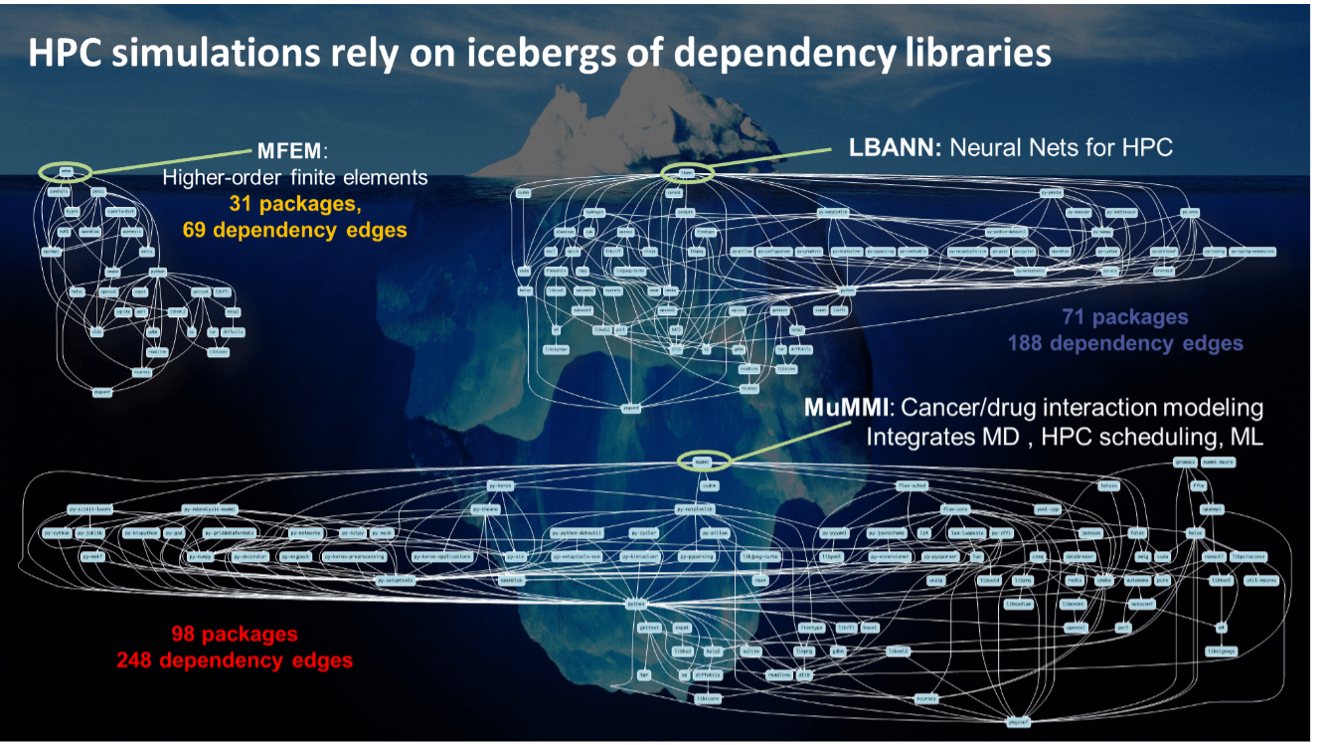
Figure 3. Complex dependency graphs of representative HPC applications.
Centralization Solves the Complex Dependency Problem
E4S project solved this cost and complex dependency problem in a very cost-effective manner by centralizing the build and deployment process with the Spack package manager. E4S contains roughly 100 ECP products, but using Spack enables E4S to leverage 500 additional dependency packages that are maintained by the Spack community. All 600 packages are in Spack and maintained by E4S, the developers of the packages, and the Spack community. Using Spack enables E4S to deploy all of these packages — including the ECP products.
Todd Gamblin (Distinguished member of technical staff in the Livermore Computing division at Lawrence Livermore National Laboratory and creator of Spack) noted, “Our collaboration with the E4S team helps to ensure that recipes for ECP products are maintained in Spack, and that Spack has robust support for the complexities of the DOE software ecosystem. Using E4S as a reference stack in CI helps to ensure that AMD, NVIDIA, and Intel GPU support is regularly tested and that Spack’s dependency analysis can handle extremely large graphs.”
Our collaboration with the E4S team helps to ensure that recipes for ECP products are maintained in Spack, and that Spack has robust support for the complexities of the DOE software ecosystem. Using E4S as a reference stack in CI helps to ensure that AMD, NVIDIA, and Intel GPU support is regularly tested and that Spack’s dependency analysis can handle extremely large graphs. — Todd Gamblin
The E4S team’s work combined with these many community efforts enables the entire stack to work effectively across many platforms. Shende noted, “With a consistent software stack, we can build complex software packages.” This includes two noteworthy projects that are important for the ECP: (1) NALU-wind is an incompressible flow solver for wind turbine and wind farm simulations used in the ExaWind project, and (2) ExaSGD is important for maintaining the integrity of the US power grid. Shende added, “The complexity of hardware is increasing, and we need software products that can be easily built and deployed on many types of large, heterogenous, distributed supercomputers—many of which utilize accelerators. E4S makes this possible.”
With a consistent software stack, we can build complex software packages. The complexity of hardware is increasing, and we need software products that can be easily built and deployed on many types of large, heterogenous, distributed supercomputers—many of which utilize accelerators. E4S makes this possible.
— Sameer Shende
Centralization Addresses Concerns about Updates
Centralizing and standardizing the build process ensures that facilities and users have easy access to the latest package releases across numerous platforms. This eliminates a huge duplication of time and human effort each time an application has to be built to run on a different hardware configuration or updated to utilize the latest software packages. As Shende explained, “A big benefit is fresh software. The interplay between the packages acts as a single software stack. This is a huge benefit. Consider the variation between CPU environments, GPU environments, languages (e.g., C, C++, Fortran), and MPI version. This creates a combinatorial build problem. Spack, its domain -specific language (DSL), and the concretizer address this issue. E4S is a curated distribution on top of Spack.”
A big benefit is fresh software. The interplay between the packages acts as a single software stack. This is a huge benefit. Consider the variation between CPU environments, GPU environments, languages (e.g., C, C++, Fortran), and MPI version. This creates a combinatorial build problem. Spack, its DSL, and the concretizer address this issue. E4S is a curated distribution on top of Spack. — Sameer Shende
CI is Essential
CI is a key part of the E4S effort. The ability to build on many different platforms is not enough by itself because the software must also be evaluated to ensure it runs correctly on each platform. Ensuring run-time correctness and performance is the reason why CI is the path to a robust and portable HPC future. CI ensures that software packages run correctly on all supported platforms, thus eliminating a costly source of software bugs. Even better, E4S users can simply download and run prebuilt executables from the build cache. In the past, users frequently accepted running software packages that were known to be buggy—a practice known as version lock-in—out of fear of making changes that might introduce new bugs (or performance regressions), which they would then have to identify and troubleshoot in their production workflows.
Not only does CI prevent version lock-in, but it also prevents vendor lock-in. For example, users can confidently run their software stack at datacenters that use CPUs and GPUs from a variety of vendors because the software has already been tested (by leveraging CI) on a variety of hardware. This same fear of finding performance and correctness bugs in new software releases also raised concerns that made users very conservative in transitioning their workflows to a new datacenter that could be running different hardware. With CI, the stable of DOE supercomputers opens up to users because CI provides a safety net of performance portability and correctness guarantees. Users can use the E4S dashboard as part of their process to request time at an HPC datacenter (or in the cloud) to ensure all their run-time requirements will be met.
The E4S CI Infrastructure
The CI infrastructure at the University of Oregon on the Frank cluster and on AWS are used to perform nightly builds and conduct test runs. Shende noted, “For every pull request on Spack, a CI run is scheduled. We use a CI infrastructure at the University of Oregon and on AWS to perform nightly builds and test runs. These are very capable systems. This ensures scientists have access to the latest, freshest software. In conjunction with Kitware, Spack, E4S, and AWS, we maintain the CI infrastructure to support this computationally demanding work.”
Shende added that “While the number of packages in Spack is increasing linearly, the combinatorics of testing the interdependence across all supported environments, machines, and build configurations is increasing exponentially. This verification burden falls to the CI infrastructure, which ultimately must run on the available CI test hardware. It is important that CI be recognized and funded to continue gaining the advantage of E4S. We are hoping that there will be a software sustainability effort from [the Advanced Scientific Computing Research program] and other organizations to continue to fund this work and reap the benefits for all HPC users once ECP ends. The alternative is to present users with untested software.”
We use a CI infrastructure at the University of Oregon and on AWS to perform nightly builds and test runs. These are very capable systems. This ensures scientists have access to the latest, freshest software. In conjunction with Kitware, Spack, E4S, and AWS, we maintain the CI infrastructure to support this computationally demanding work. While the number of packages in Spack is increasing linearly, the combinatorics of testing the interdependence across all supported environments, machines, and build configurations is increasing exponentially. This verification burden falls to the CI infrastructure, which ultimately must run on the available CI test hardware. It is important that CI be recognized and funded to continue gaining the advantage of E4S. We are hoping that there will be a software sustainability effort from [the Advanced Scientific Computing Research program] and other organizations to continue to fund this work and reap the benefits for all HPC users once ECP ends. The alternative is to present users with untested software. — Sameer Shende
Shende continued, “Funding is key and is separate from the funding for leadership-class systems. This does make CI an explicit cost center rather than hiding the cost indirectly in per-application wastage. Frank is supported by our lab. AWS has an ongoing relationship with the Spack community to provide a generous number of cloud credits. Currently, there is no separate funding for procurement and updates. Consider the cost of the alternative legacy model in which individual projects would need to individually build, identify errors, and contact the developers. This can result in significant loss of leadership-class run time and human resources.”
Consider the cost of the alternative legacy model in which individual projects would need to individually build, identify errors, and contact the developers. This can result in significant loss of leadership-class run time and human resources. — Sameer Shende
Not every CI run has to build all the packages. There are also cross-application builds to ensure cross-package interoperability. One example is https://gitlab.e4s.io/uo-public/trilinos. Users can see the jobs running by viewing https://gitlab.e4s.io/uo-public. If an error is found, then the package developers are automatically notified. This enables community software development. Shende noted, “The timings show performance regressions as well.”
Containers and the Cloud
Containers are an excellent way to bundle an application workflow to ensure all associated library and support executables are available and of the correct version.[4] [5] Shende noted, “Containers make the software immediately available to a large user base. This is important for data analytics and custom application jobs as well as large HPC application workflows. Every day, users run many of these high-throughput containers via the open science grid.” See https://osg-htc.org for more information.
Looking to agencies outside of the ECP, including the National Nuclear Security Administration, NOAA, and the National Science Foundation (NSF), Shende noted, “We have now created custom images for non-government projects such as Waggle.” Waggle is an open-source platform for developing and deploying novel AI algorithms and new sensors into distributed sensor networks. Waggle and edge computing have important societal implications as Shende noted, “E4S is helping develop capabilities for HPC and AI at the edge to track forest fires and earthquakes in harsh remote rural areas and much more. E4S containers are now available to those users.” HPC in the cloud is another beneficiary of E4S software. Cloud platforms, for example can be used are using E4S project to build semiconductor chips (see https://xyce.sandia.gov). The E4S Docker container snapshots are now available.
Containers make the software immediately available to a large user base. This is important for data analytics and custom application jobs as well as large HPC application workflows. Every day, users run many of these high-throughput containers via the open science grid. E4S is helping develop capabilities for HPC and AI to the edge to track forest fires and earthquakes in harsh remote rural areas and much more. E4S containers are now available to those users. — Sameer Shende
E4S is Now a Top-Level Component in the DOE HPC Community
As discussed at the recent ECP Annual Meeting, E4S is now a top-level component in the DOE HPC community, and similar interest from users and contributors are happening with other US agencies such as the NSF, US industry, and international collaborators. The team has given tutorials in Australia, the UK, and Finland, which reflects international interest.
Along with broadening interest, the E4S portfolio is also expanding. New domains now include lower-level operating system components as well as AI and ML applications. Overall software quality and delivery are also improving. The team is providing both better quality and faster delivery of leading-edge capabilities, both of which will help product teams save time and money.
Recent accomplishments include detailed documentation for containerized and bare-metal E4S installations plus the following additions:
- Updates to 106 HPC packages for x86_64, aarch64, and ppc64le architectures
- Updates for the NVIDIA Hopper architecture, including NVIDIA H100 GPUs with CUDA 12.0 and NVHPC 23.1
- Support for AI/ML frameworks (e.g., TensorFlow and PyTorch)
- Support for NVIDIA A100 and H100 GPUs in E4S 23.02
- Support for AMD MI100 and MI210/MI250X AMD GPUs along with AMD’s ROCm 4.3 software, also in E4S 23.02
- Support for the Julia software stack, including CUDA and MPI
- Electronic Design Automation (EDA) tools (e.g., Sandia National Laboratory’s Xyce parallel electronic simulation) in x86_64, ppc64le, and aarch64 containers and 50+ EDA tools (Xscheme, Xyce, OpenROAD, OpenFASOC, OpenLane, and others) on AWS (see https://e4s.io/eda)
The E4S-CL Tool
The team released the e4s-cl tool for launching containers to target MPI applications (Figure 4). MPI is critical to application performance in a distributed HPC computing environment.
Users can also utilize the e4s-cl tool to substitute the containerized MPI with the parent system’s MPI implementation. For example, if a datacenter or cloud management team has an MPI implementation optimized for their system’s underlying hardware, then the users can leverage that optimized MPI implementation in favor of the MPI included in the container.
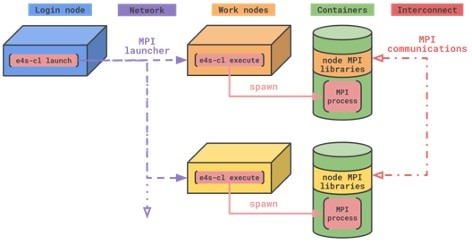
Figure 4: The e4s-cl tool for launching MPI applications. (Source: https://github.com/E4S-Project/e4s-cl)
Keeping Up with Demand
The team is actively working to keep up with demand for Spack-based deployment through ECP Application Development engagements and typical use-case build and deployment.
Shende highlighted this work with the ECP ExaWind project, including E4S cache deployment to eliminate the need for the user to build the software and containerization by using E4S base images. These container images contain Spack-based development builds of AMR-Wind, Nalu-Wind, Trilinos, and other elements of the ExaWind software stack. The build process for these containers has been integrated via the Spack Manager meta-build tool developed in-house by the ExaWind team. Container images are posted daily to the ecpe4s/exawind-snapshot DockerHub repository.
GitLab integration adds ExaWind snapshots, which are available at https://gitlab.e4s.io/uo-public/exawind-snapshot. The ExaWind CI also used a new Git hash feature for development builds. The feature enables users to specify recent Git commits and branches in Spack, which allows them to build versions of their code directly from the source repository. Using this feature, users can build versions that aren’t even in Spack yet, and they can use Spack for active code development. Other projects include ExaSGD (to help maintain the US power grid), in which a Spack-based build cache is being hosted on the Crusher test bed system. The build cache includes ROCm-enabled components (e.g., ExaGo, HIOP) to run ExaSGD on AMD hardware. Here is a demonstration video showing the installation of ExaGo in less than 5 minutes.
Summary
E4S is a framework for collaborative open-source product integration. It is an extensible, open architecture software ecosystem that accepts contributions from US and international teams.
In acting as a vehicle for delivering high-quality reusable software products and in collaboration with others, E4S provides a full collection of compatible software capabilities and a manifest of à la carte selectable software capabilities. For these reasons, E4S acts as a software conduit for DOE supercomputers and future leading-edge HPC software projects that target scalable, next-generation computing systems.
For additional recent information, see the following presentations:
- https://e4s.io/talks/E4S_Support_Feb23.pptx
- https://e4s.io/talks/E4S_23.02.pptx
- https://e4s.io/talks/E4S_ECPAM23.pptx
This research was supported by the Exascale Computing Project (17-SC-20-SC), a joint project of the US Department of Energy’s Office of Science and National Nuclear Security Administration, responsible for delivering a capable exascale ecosystem, including software, applications, and hardware technology, to support the nation’s exascale computing imperative.
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national laboratories and commercial organizations.
NOTE: To prevent confusion, duplicate references are kept throughout the review period. They will be replaced with ibid once publication is approved.
[1] https://www.exascaleproject.org/the-extreme-scale-scientific-software-stack-e4s-a-new-resource-for-computational-and-data-science-research/
[2] https://www.exascaleproject.org/continuous-integration-the-path-to-the-future-for-hpc/
[3] https://www.exascaleproject.org/the-extreme-scale-scientific-software-stack-e4s-a-new-resource-for-computational-and-data-science-research/
[4] https://containerjournal.com/topics/container-management/containers-hpc-mutually-beneficial/
[5] https://www.exascaleproject.org/highlight/advancing-operating-systems-and-on-node-runtime-hpc-ecosystem-performance-and-integration/