By Rob Farber, contributing writer
The Message Passing Interface (MPI) is recognized as the ubiquitous communications framework for scalable distributed high-performance computing (HPC) programming. Created in 1994,[1] MPI is arguably the core building block of distributed HPC computing. According to an Exascale Computing Project (ECP) estimate, more than 90% of the ECP codes use MPI—either directly or indirectly.[2] In a chicken-and-egg analogy, where MPI goes so goes HPC and vice versa.
David Bernholdt, principal investigator of the ECP OMPI-X project and distinguished R&D staff at ORNL observed, “Programmers who wish to use MPI in a threaded, heterogenous environment need to understand how the updates to the MPI standard address multithreading performance bottlenecks in MPI libraries prior to the MPI 4.0 standard. Due to the efforts of many, including the OMPI-X team, programmers can now use many of these performance enhancements in the latest release of Open MPI.”
Programmers who wish to use MPI in a threaded, heterogenous environment need to understand how the updates to the MPI standard address multithreading performance bottlenecks in MPI libraries prior to the MPI 4.0 standard. Due to the efforts of many, including the OMPI-X team, programmers can now use many of these performance enhancements in the latest release of Open MPI. — David Bernholdt
The scientific computing community’s increasing need for HPC has driven continued growth in hardware scale and heterogeneity. These innovations have placed unforeseen demands on the legacy MPI communications standard and library implementations. Many novel approaches have been integrated into the MPI 4.0 specification to adapt the venerable MPI standard and library implementations (e.g., Open MPI v5.0.x) so they can run more efficiently in modern, heavily threaded, and GPU-accelerated computational environments. Eliminating lock inefficiencies in parallel codes, supporting heterogeneity, and reducing resource utilization have been key focal points as modern HPC clusters can now run thousands to millions of concurrent threads of execution—a degree of parallelism that was simply not possible in 1994.

Figure 1. David Bernholdt.
The rise of these architectures has in turn increased the importance of hybrid programming models in which node-level programming models such as OpenMP are coupled with MPI. This is commonly referred to as MPI+X. These changes are not just theoretical, and this is why the OMPI-X team has been advocating, driving, and developing updates to the open-source Open MPI library. This has been a community effort that encompasses significant work by many individuals, discussions in the MPI Forum, and feedback from the various organizations that comprise the MPI standards committee.
In leading the ECP OMPI-X project, Bernholdt has been both participant and advocate in correcting many of the issues that limit MPI performance in heavily threaded, heterogenous computing environments and incorporating these updates into the Open MPI library.
Technical Introduction
Bernholdt explained the driving focus behind the OMPI-X efforts, “We recognize that MPI serves a very broad community. The current leadership-class systems are only a portion of that community, but these systems are important because they act as a proving ground. For this reason, we pay attention to ensure that the forthcoming MPI specification serves the needs of the high-end systems as well as the needs of the entire community.”
We recognize that MPI serves a very broad community. The current leadership-class systems are only a portion of that community, but these systems are important because they act as a proving ground. For this reason, we pay attention to ensure that the forthcoming MPI specification serves the needs of the high-end systems as well as the needs of the entire community. — David Bernholdt
He continued by noting that when the OMPI-X project started, the HPC community had only an approximate vision of what an exascale system would look like. For this reason, the team picked concepts that were important and useful. They then advocated and eventually facilitated the adoption of these concepts by the standards committee—a time-consuming and laborious process that incorporated feedback from many projects and the MPI Forum. As part of the OMPI-X effort, the team also worked to implement desirable contributions in the new standard.
These innovations appear in the MPI 4.0 standard and the Open MPI 5.0.x library software releases. The updates are extensive and are the subject of numerous publications in the literature:
- Partitioned communications support increased flexibility and the overlap of communication and computation. Partitioned communication is applicable to highly threaded CPU-side MPI codes but has significant utility for GPU-side MPI kernel calls with low expected overheads. This includes the addition of performance-oriented partitioned point-to-point communication primitives and autotuning collective operations.
- Sessions (and PMIx) introduces a concept of isolation into MPI by relaxing the requirements for global initialization, which currently produces a global communicator. Each MPI Session creates its own isolated MPI environment, potentially with different settings, optimization opportunities, and communication data structures.[3] Sessions enable dynamic resource allocation that leverages the Process Management Interface for Exascale (PMIx). PMIx communicates with other layers of the software stack and can be used by job schedulers such as SLURM. It also permits better interactions with file systems and dynamic process groups for managing asynchronous group construction and destruction. The “PMIx: A Tutorial” slide deck in the PMIx GitHub repository provides a quick overview of the features and benefits of PMIx.
- Standardization of error management within MPI. The MPI 4.0 standard allows for asynchronous operations, which required updating the MPI error notification mechanism.
- Resilience related research considers fault-tolerance constructs as possible additions to MPI, including User Level Failure Mitigation (ULFM) and Reinit. The ULFM proposal as developed by the MPI Forum’s Fault Tolerance Working Group supports the continued operation of MPI programs after node failures have impacted application execution. See the paper and research hub for more information. Reinit++ is a redesign of the Reinit[4],[5] approach and variants[6],[7] that leverages checkpoint-restart.
- Usual performance/scalability improvements as reflected in benchmarks using the Open MPI library.
Multithreaded Implications for MPI: Performance, Portability, Scalability, and Robustness
User-level threading to exploit the performance capabilities of modern hardware has motivated the extensive analysis performed by the OMPI-X team and other investigators. Topics include the best threading models (e.g., Pthreads or Qthreads) as well as autotuning. The OMPI-X team has also dedicated efforts to improving testing and the all-important continuous integration (CI) to ensure correct operation on many HPC platforms.
As a communications framework, MPI is by definition memory bandwidth limited on the node. In “Give MPI Threading a Fair Chance: A Study of Multithreaded MPI Designs,” Patinyasakdikul, Eberius, Bosilca, and Hjelm noted that over the past decade, theoretical node-level compute power has increased 19×, while bandwidth available to applications has seen an increase of only 3×, thereby resulting in a net decrease for byte per floating-point operation per second (FLOP/s) of 6×. The increased rate of computation must be sustained by a matching increase in memory bandwidth, but “physical constraints set hard limits on the latency and bandwidth of data transfers.” The current solution to overcome these limitations has been to increase the number of memory hierarchies with orders of magnitude variation in cost and performance between them.
Patinyasakdikul et al. consider various design and implementation requirements to support multiple threads, including resource allocation, thread-safe resource considerations, Try-Lock semantics, concurrent sends, concurrent progress, and concurrent matching in the Open MPI framework. They also note a significant boost in multithreaded performance and the viability of MPI in the MPI+threads (or MPI+X) programming paradigm.
Portability is a key focus. All updates to the MPI standard and their associated library implementations must be portable to support the needs of all HPC users.
In “Implementing Flexible Threading Support in Open MPI,” Evans et al. describe how to componentize the Open MPI threading model. This paper references several studies that reinforce the MPI performance speedups that can be achieved through threading models.[8]
Part of the reluctance to modularize threading library support in MPI implementations arises from concerns about the cost of thread synchronization. Synchronization primitives and related functions are in the critical path of important runtime functionality, and even minor slowdowns can be detrimental to performance.
Evans et al. noted that improvements in compilers and CPU branch prediction make reassessing the modularity of MPI threading worthwhile. They proposed the Open, Portable Access Layer (OPAL, shown in Figure 2), which has been implemented as part of the Open MPI Modular Component Architecture (MCA). The team demonstrated the flexibility of this approach with support for several MCA threading models: Pthreads, the well-known POSIX threads; Qthreads, a very lightweight threading API designed to support many lightweight threads and implemented in Sandia National Laboratory’s Qthread library; and Argobots, a lightweight runtime system that supports integrated computation and data movement with massive concurrency.
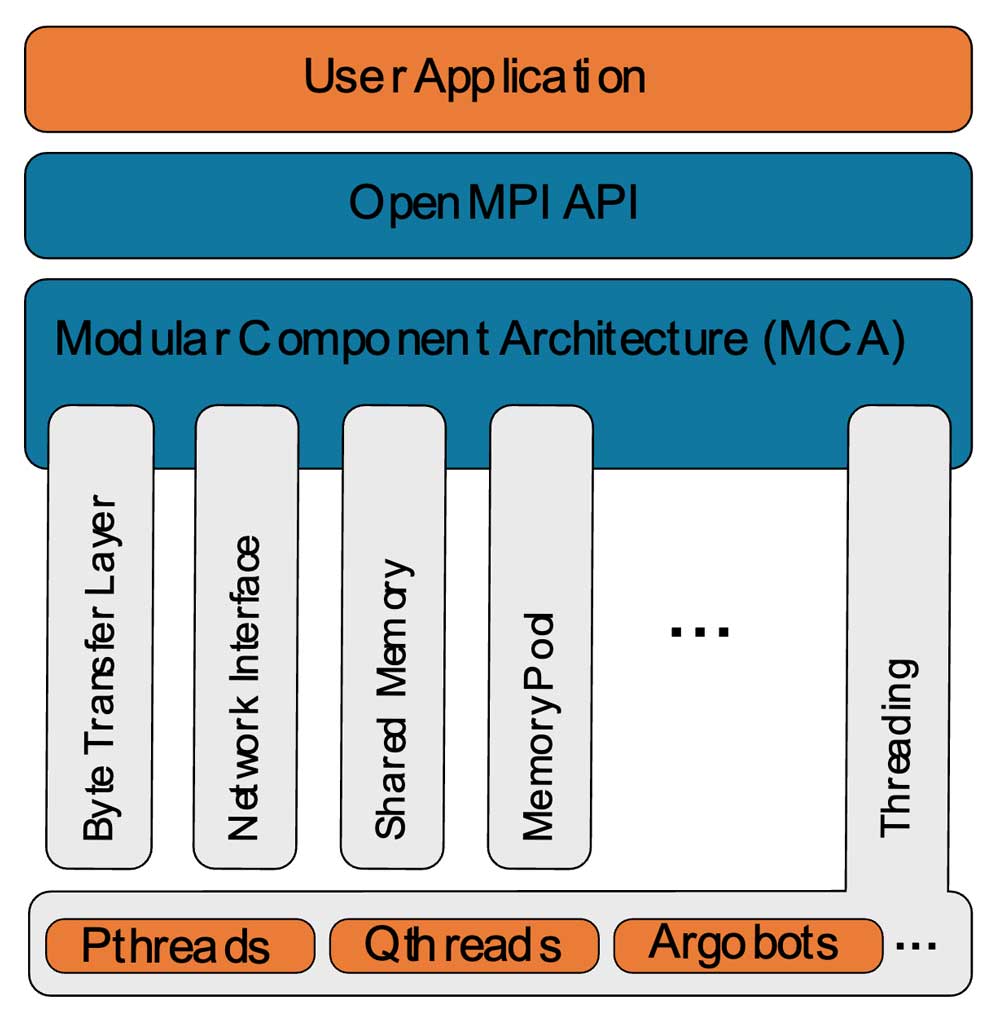
Figure 2. Visual representation of OPAL in the Open MPI MCA. The figure shows several MCA modules, including the newly added threading support.
Bernholdt noted that as a result of the collaboration on the interface with the Exascale MPI (MPICH) and Argo teams, both Qthreads and Argobots libraries can be used in both Open MPI and the popular MPICH MPI library.
The Hierarchical AutotuNed (HAN) collective communication framework in Open MPI leverages both threading and modularity in Open MPI to find optimal configurations in most cases.[9] HAN recognizes that as HPC systems become more heterogeneous, collective communication operations suffer in the face of a corresponding increase in the complexities of the hardware hierarchies. Collective operations are a type of communication primitive, defined in the MPI standard, that are used to exchange data among multiple processes. HAN is used to quickly adapt and tune these hierarchical collective communication primitives according to message size, type, and hierarchy of the destination computer architecture. HAN achieves high performance by
- exploiting the hardware capabilities;
- maximizing communications overlap, which improves efficiency by proactively moving data to reduce or eliminate idle time while the node is otherwise occupied with performing a computation for which it has data; and
- maintaining sufficient flexibility in the software framework so it can be adapted to support new hardware, network capabilities, and network topologies.
For more information, see “HAN: a Hierarchical AutotuNed Collective Communication Framework.”
As part of their work, the OMPI-X team and collaborators have been updating the MPI’s CI and error checking test suites to verify software correctness and compatibility with the latest MPI standard. CI is the path to the future for HPC, and its importance cannot be understated. Bernholdt explained, “The Open MPI project is a big project with many academic and vendor organizations participating. ECP OMP-X is a small part of it. While the Open MPI project has extensive CI and testing, we contributed testing on the high-end platforms. This is important when making new releases. Our team has been working behind the scenes to enhance the CI method (a bespoke effort complicated due to testing infrastructure) and in contributing to the test suite.”
The Open MPI project is a big project with many academic and vendor organizations participating. ECP OMP-X is a small part of it. While the Open MPI project has extensive CI and testing, we contributed testing on the high-end platforms. This is important when making new releases. Our team has been working behind the scenes to enhance the CI method (a bespoke effort complicated due to testing infrastructure) and in contributing to the test suite. — David Bernholdt
Key Updates (Sessions and the PMIx Standard, Partitioned Communications, and Resilience)
Application programmers must familiarize themselves with the updates to the MPI 4.0 (and forthcoming 4.1) standard. These updates can significantly improve MPI performance in multithreaded and heterogenous (e.g., GPU-accelerated) computing environments.
One can view any HPC cluster as a collection of computational nodes connected by a communications fabric. MPI was developed to tie the computational nodes together so they can be used by a single application to solve a single computational problem. In this way, MPI facilitates computing in a distributed environment.
The original abstraction of a single MPI_COMM_WORLD communicator worked well until the advent of heavily threaded heterogenous computing. The added parallelism of these new HPC architectures opened new performance vistas that were hampered by the single global communications abstraction and thread locking issues, even with the ability to partition the global communicator. MPI resource allocation also proved problematic in heavily threaded applications; hence the introduction of the PMIx standard, which communicates resource allocation to other layers of the software stack.
Programmers use these new capabilities to exploit the parallelism in the new HPC systems by assigning different processing cores and GPU accelerators and to overlap communications and computation and concurrently process different computational tasks. Along with faster time-to-solution, these updates result in better application scaling for more computational nodes and improvements in resilience.
Three key features (MPI Sessions, partitioned communications, and resilience), along with links to relevant papers for further reading, are described below. As always, the documentation for each specific library is the best resource when writing code.
MPI Sessions
MPI Sessions address several limitations of MPI’s prior specification:[10]
- MPI cannot be initialized within an MPI process from different application components without a priori knowledge or coordination;
- MPI cannot be initialized more than once; and,
- MPI cannot be reinitialized after MPI finalization.
MPI Sessions were created to facilitate dynamic resource allocation and utilization. Although some forms of dynamicity existed in MPI prior to MPI Sessions, it was limited by a requirement for global synchronization.[11] Sessions also provides more flexible ways for an application’s individual components to express the capabilities they require from MPI at a finer granularity than was previously possible.
More specifically, an application first obtains an MPI Session handle by calling the MPI_Session_init() function. This function allows the consumer software to specify the thread support level for MPI objects associated with this MPI Session as well as the default MPI error handler to use for initialization of the session and associated MPI objects. The MPI implementation guarantees that the MPI_Session_init() method is thread safe.
This implements a powerful, asynchronous, and thread-safe abstraction in which each MPI Session identifies a stream of MPI function calls and can manage a sequence of MPI operations. Furthermore, MPI Sessions includes a restriction that sessions are isolated from each other. This means that each stream of instructions/operations associated through the MPI Session with a particular execution thread or software component can operate independently from each other.
Together, these characteristics of the abstraction solve the problems associated with multithreaded initialization[12] and enable the succinct expression of fork-join parallel regions in a manner similar to that of OpenMP threads but applied to MPI processes. From the application programmer’s perspective, MPI Sessions can support both ensemble applications and task parallel execution models.
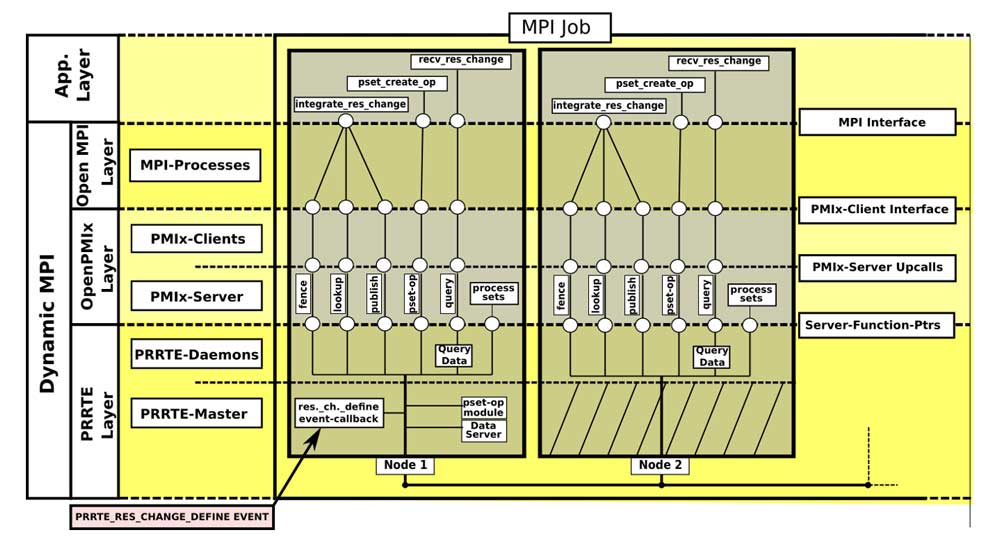
Figure 3. Overview of the prototype implementation of MPI Sessions and PMIx in Open MPI. This example shows two nodes running a (dynamic) MPI job. The figure differentiates between four layers (see labels on the left), which are each accessible from the layer above via the interfaces indicated on the right side. The interior of the nodes delineates the required interactions of the dynamicity extensions to MPI with PRRTE using PMIx.[13]
- “MPI Sessions: Evaluation of an Implementation in Open MPI.” This paper also includes performance results.
- “Towards Dynamic Resource Management with MPI Sessions and PMIx”
- “MPI Sessions: Leveraging Runtime Infrastructure to Increase Scalability of Applications at Exascale”
Partitioned Communications
Partitioned communication is a technique introduced in MPI 4.0 to perform point-to-point communications efficiently with high levels of concurrency in threaded environments. Previous work on partitioned communication focused on prototype libraries[14],[15] and demonstrated performance that was used as a basis for the interface.
According to Dosanjh et al. in “Implementation and Evaluation of MPI 4.0 Partitioned Communication Libraries,” network interface cards (NICs) that leverage the CPU for communication message processing could become a bottleneck with the move to manycore architectures.[16] It was not until recent studies and purpose-built benchmarks were developed that the magnitude of the overhead of processing such large volumes of messages became clear.[17] Resource allocation is a key issue, which was addressed by keeping the MPI-level message volume identical to the single-threaded MPI model, as discussed by Grant et al. in “Finepoints: Partitioned Multithreaded MPI Communication.” These concepts eventually evolved into MPI partitioned point-to-point communication, which was formally approved by the MPI Forum in June 2021.
Partitioned communications in the MPI 4.0 standard address issues in highly threaded, CPU-side MPI codes and should have significant utility for GPU-side MPI kernel calls that have low expected overheads.[18] Current proposals are underway for MPI 4.1 to further optimize a GPU-side implementation of an MPI_Pready call on the GPU to trigger data movement, but users and library developers should not wait. Providing immediate access to partitioned communication is a critical aspect of application readiness for next-generation supercomputers.[19]
Although the libraries described by Dosanjh et al. in “Implementation and Evaluation of MPI 4.0 Partitioned Communication Libraries” are not GPU based, they enable developers to begin coding today and to conduct performance analyses for their codes. According to the paper, “The process of converting a CPU-side partitioned communication exchange to a GPU-side one is relatively straightforward.”[20] “MPI Partitioned Communication” provides a good overview.
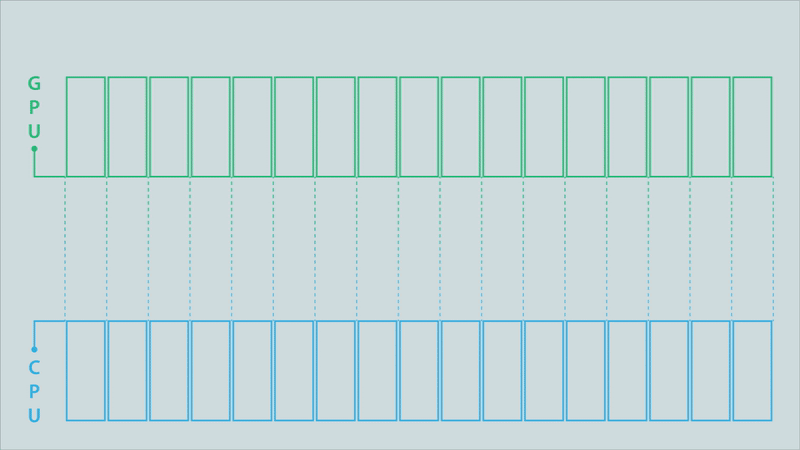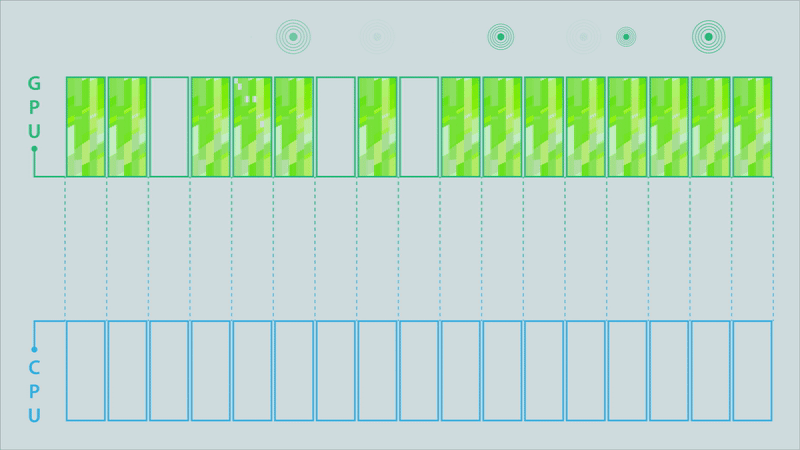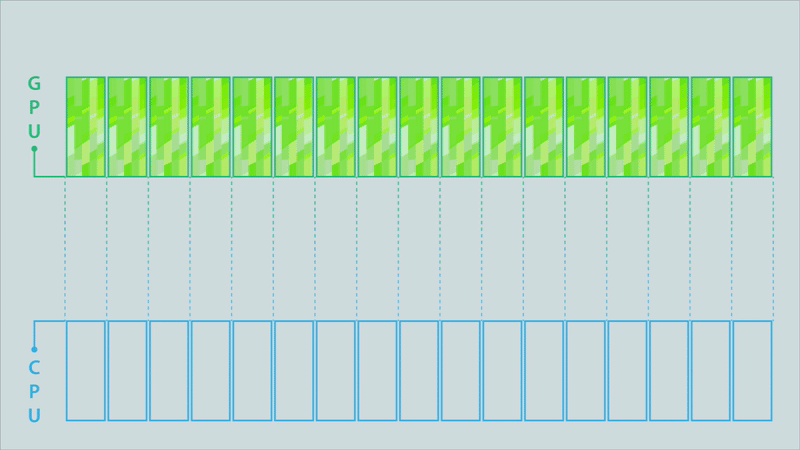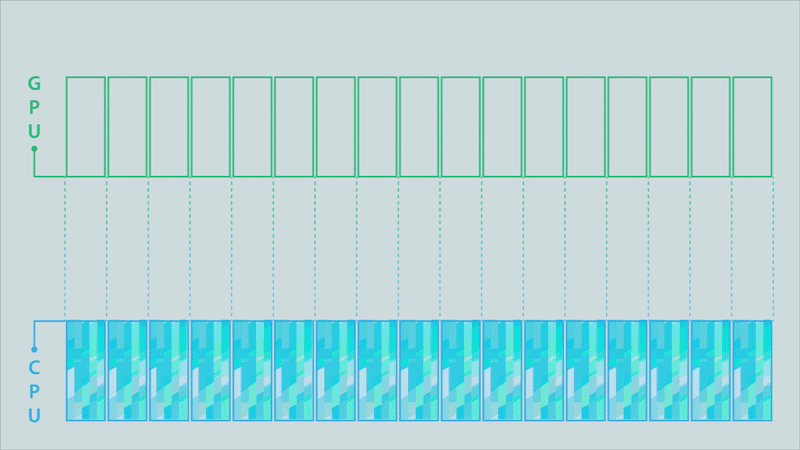
Figure 4a. Classic model (click for animation).
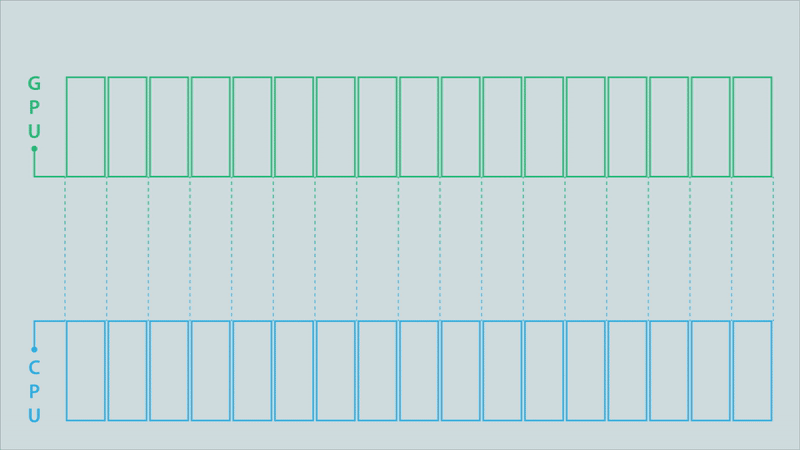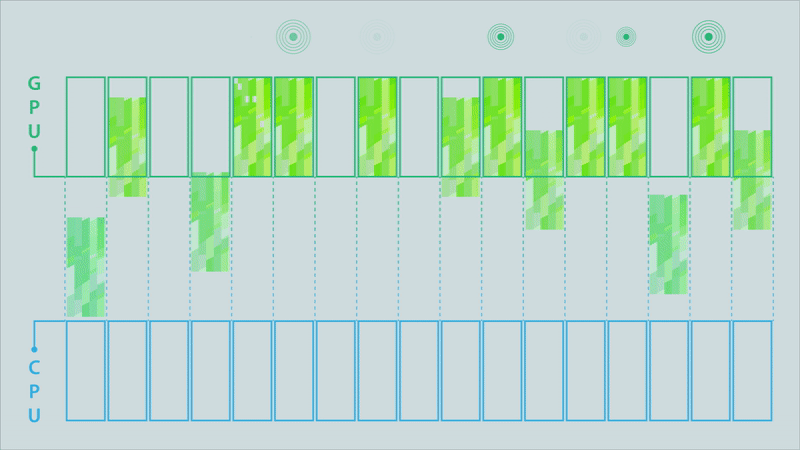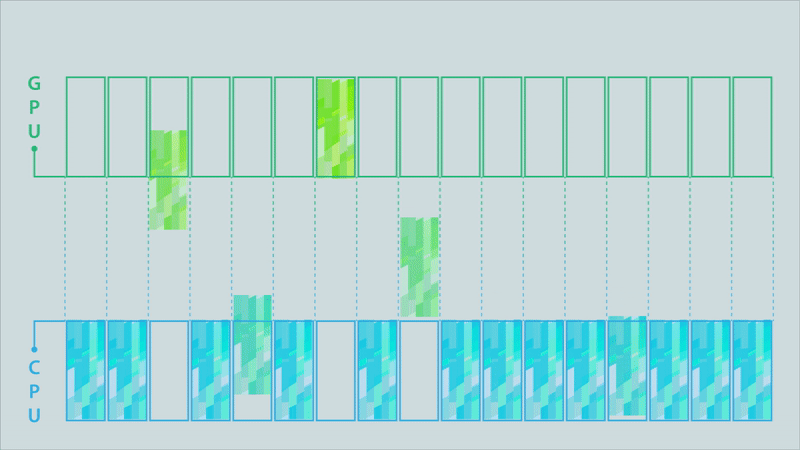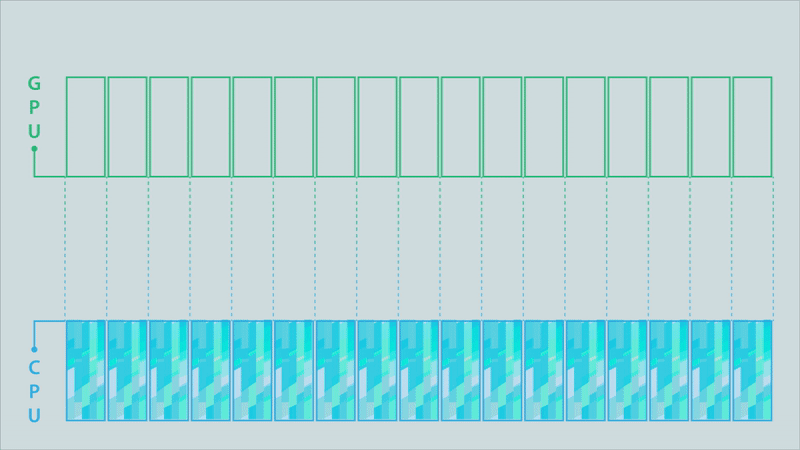
Figure 4b. Partitioned model (click for animation).
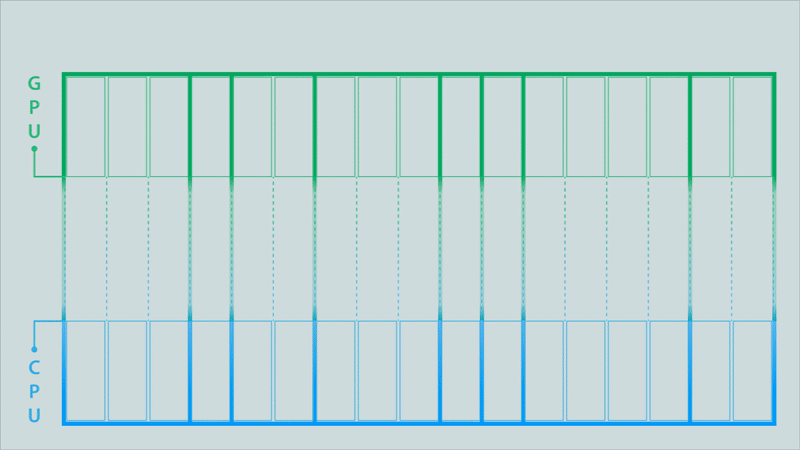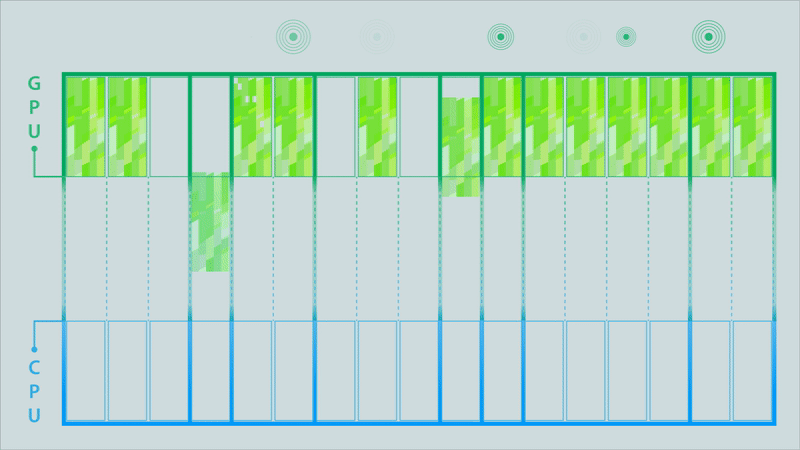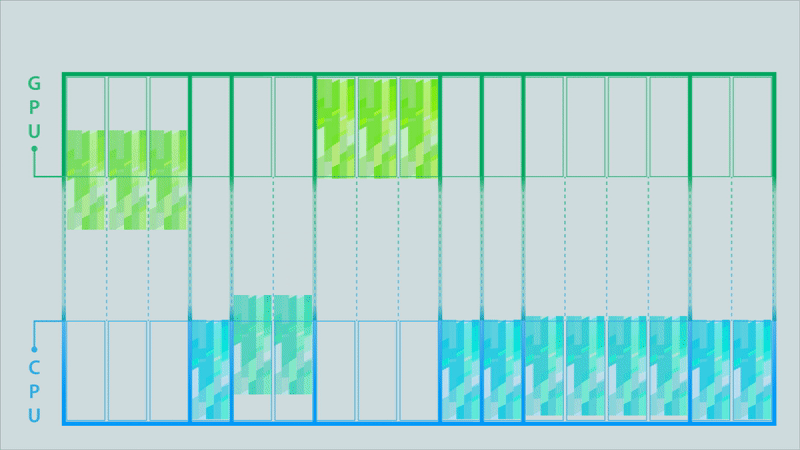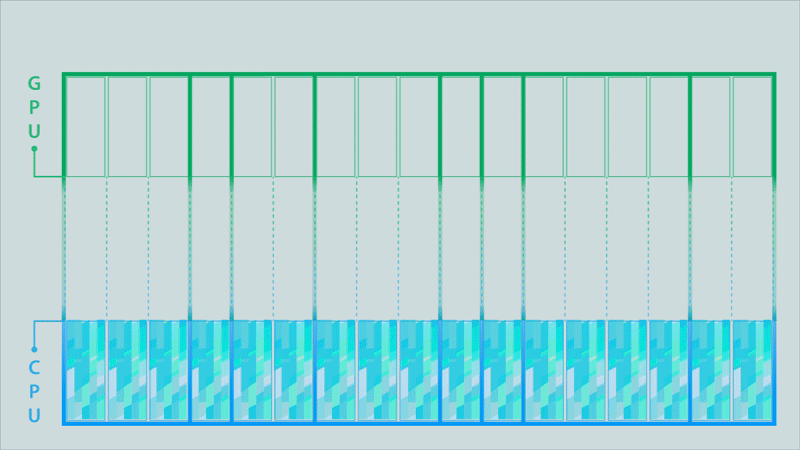
Figure 4c. After the MPI library optimizes the partitioned MPI communications (click for animation).
The animations in Figure 4 illustrate the difference between the classic model, a partitioned model, and an optimized partitioned model for a computation conducted on a GPU, the results of which must then be moved to a different process running on a CPU.
The data buffer holding the results is depicted as being split into 17 partitions. Signals above each partition are triggered when its contents are complete. In the classic MPI communication model (top image), the entire buffer must be available before it can be sent to the CPU. This changes when using partitioned communications because the MPI library can start moving individual partitions as soon as the signal indicates they are ready (middle image). Computation of results can then be overlapped with the communication (to their destination) of the results. The MPI library can also be used to optimize the data transfers (bottom image). In this example, some of the partitions are bundled together to enable more efficient data movement.
For more information (including performance results as noted), see the following papers:
- “Design of a Portable Implementation of Partitioned Point-to-Point Communication Primitives.” This paper includes performance results for the miniFE ECP mini-app.
- “Implementation and Evaluation of MPI 4.0 Partitioned Communication Libraries”
Resilience
Traditionally, failures in MPI-based applications have been addressed through checkpoint and restart, in which each application process periodically saves its state to stable storage within checkpoint files. Should a failure be detected, all computational nodes running the entire application are restarted from one of the previous error-free checkpoints. This guarantees that errors from the failure do not introduce nonphysical artifacts into the application (e.g., in a physical simulation).
Research indicates that in large parallel systems, failures frequently have a limited impact, and they affect only a subset of the cores or computational nodes used by the application. Under these circumstances, a complete cancellation of the MPI application followed by a full restart yields unnecessary overheads and stresses the parallel file system.[21]
In “Resilience and fault tolerance in high-performance computing for numerical weather and climate prediction,” Benacchio et al. provide a good target taxonomy of resilience methods as they survey hardware and application-level and algorithm-level resilience approaches relevant to time-critical numerical weather and climate prediction.
More generally, there are currently two leading approaches to MPI resilience: ULFM and Reinit.
ULFM
UFLM proposes the inclusion of resilient capabilities in the MPI standard to repair the MPI communication capabilities should a failure be detected. These new functionalities provide the minimal features necessary to deliver resilience support without imposing a strict recovery model. Therefore, it does not include any specialized, non-portable mechanism to recover the application state at failed processes, thereby providing developers of applications or higher-level frameworks the flexibility to implement the optimal methodology after considering the properties of the target application or domain.
ULFM is the most active effort to integrate fault tolerance in the MPI standard.[22] Bernholdt noted, “[ULFM] is something that researchers have been working on for a long time. Some elements have been adopted in the MPI 4.0 standard, while others are still being discussed.”
ULFM is something that researchers have been working on for a long time. Some elements have been adopted in the MPI 4.0 standard, while others are still being discussed. – David Bernholdt
Applications exhibit a wide variety of pre- and post-failure behaviors that demand a diverse set of recovery strategies. Among their key differences are (1) how many processes are involved in managing a failure and its consequences, (2) what the expectations are in terms of restoring the mapping of processes and data onto the physical resources (i.e., the difference between malleable jobs that can adapt on the fly to a changing deployment topology and inflexible jobs for which the data distribution and process mapping must adhere to some predefined rules, e.g., a cartesian grid), and (3) how the data is to be restored after the process failure (e.g., from a checkpoint, by interpolating neighboring data, with additional iterations).
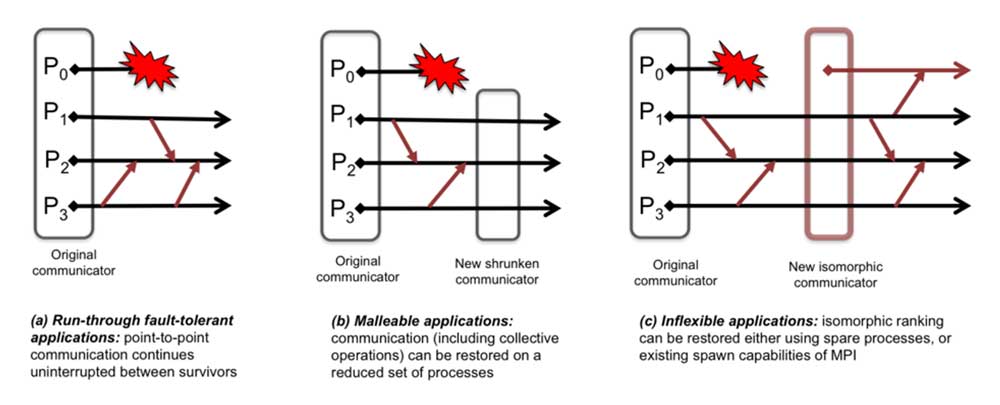
Figure 5. Run-through, malleable, and inflexible applications have different needs in terms of restoring communication capabilities. (Source)
The ULFM interface provides a generic method to restore MPI’s communication infrastructure and capabilities after a failure, but it does not provide a strategy for data restoration. That is up to the application programmer because each application is likely to exhibit an original combination of the three previously mentioned failure behaviors and potentially many other criteria.
In “Integrating process, control-flow, and data resiliency layers using a hybrid Fenix/Kokkos approach,” Whitlock et al. describe the design, implementation, and verification of a resilience layer that uses a comprehensive system of runtimes . Whitlock et al. leverage the Fenix fault tolerance library, which is a process resilience library that prioritizes integration into preexisting resilience systems and updates the Kokkos resilience and the VeloC checkpoint-restart use pattern to support application-level integration of resilience runtimes.
Reinit, Reinit++, and Frame
The following are proposals currently under discussion in the MPI Forum. Although prototypes have been implemented in Open MPI, they are not yet part of the standard.
Reinit supports global-restart recovery, which is similar to standard application checkpoint/restart. Reinit is open-source and can be downloaded from GitHub.
Reinit requires the programmer to encapsulate the application’s operation in a resilient_main function that serves as the rollback point for survivor processes when a failure occurs. According to the literature, the existing implementation of Reinit is difficult to deploy[23] because it requires modifications to the job scheduler.[24],[25]
Two approaches have been published in the literature to address the deployment issue.
Reinit++ is a new design and implementation of the Reinit approach for global-restart recovery that avoids application redeployment. Reinit++ has been implemented in Open MPI v4.0.0 to ease the deployment burden and was designed to be compatible with any job scheduler that works with the Open MPI runtime.[26]
To simplify deployment, Reinit++ works with three frameworks that are internal to the Open MPI software architecture: (1) Open MPI’s MPI layer (OMPI), which implements the interface of the MPI specification used by the application developers; (2) the Open RunTime Environment (ORTE), which implements runtime functions for application deployment, execution monitoring, and fault detection; and (3) OPAL, which implements abstractions of OS interfaces, such as signal handling and process creation.
Reinit++ extends OMPI with the MPI_Reinit function. This function extends the ORTE to propagate fault notifications from daemons to the root and to implement the MPI recovery mechanism when a fault is detected. Also, Reinit++ extends OPAL to implement low-level process signaling for notifying survivor process to roll back.
FRAME
The Fault toleRAnt Mpi with chEckpoint-restart (FRAME) solution, which is described by Parasyris et al. in “Co-Designing Multi-Level Checkpoint Restart for MPI Applications,” combines multilevel, asynchronous checkpointing and online MPI recovery techniques, thus inheriting their optimizations and claiming that no additional overhead is introduced while it accelerates recovery by co-designing a checkpoint retrieval optimization for application recovery.
FRAME takes a different approach from previous efforts that recover MPI online without tearing down and redeploying MPI execution to save overhead. These methods assume application-level checkpointing, although they are oblivious to its operation.[27]
Parasyris et al. note that state-of-the-art application recovery is based on multilevel, asynchronous checkpointing techniques in which checkpoints are stored on a hierarchy of storage devices. Although asynchronous checkpoint storing and copying minimizes the disruption to application execution, retrieving checkpoints scales poorly and can be a bottleneck depending on the severity and frequency of failures.
For more information, see the following papers:
- “Resilience and fault tolerance in high-performance computing for numerical weather and climate prediction.” This report surveys hardware and application-level and algorithm-level resilience approaches relevant to time-critical numerical weather and climate prediction.
- “Fault Tolerance of MPI Applications in Exascale Systems: The ULFM Solution.” This paper provides an overview of ULFM and compares it with methods (e.g., Reinit).
- “Integrating process, control-flow, and data resiliency layers using a hybrid Fenix/Kokkos approach.” This paper considers an ECP-relevant use case using Kokkos.
- “Co-Designing Multi-Level Checkpoint Restart for MPI Applications”
- “Reinit++: Evaluating the Performance of Global-Restart Recovery Methods for MPI Fault Tolerance”
MPI 4.0 Standards Compliance and Implementations
Bernholdt noted, “The impact of the OMPI-X work on the MPI standard itself is important. It has to be right, which is why making such changes is very people intensive and entails extensive discussions with stakeholders and the MPI Forum and can take years to happen.”
The impact of the OMPI-X work on the MPI standard itself is important. It has to be right, which is why making such changes is very people intensive and entails extensive discussions with stakeholders and the MPI Forum and can take years to happen. — David Bernholdt
MPI 4.0–compliant software is now available for use. The current MPICH is MPI 4.0 compliant (see the README). The status of Open MPI v5.0.x series can be found on the Open MPI website. The current state of Open MPI conformance can be viewed in Section 3.5.1.
Performance and Scalability Enhancements
In terms of performance on the latest ECP hardware, Bernholdt said, “Overall, we are seeing performance comparable to the Cray MPICH effort on Crusher. We are excited for the future of Open MPI on the nation’s exascale supercomputers. Note that this is a work in progress as Open MPI implements all the features.”
The team is working to optimize Open MPI performance on the HPE Cray Slingshot interconnect, which is used in exascale systems such as Frontier and the upcoming El-Capitan.[28] HPE Cray’s Slingshot-11 is a high-performance, Ethernet-based network that supports adaptive routing, congestion control, and isolated workloads.[29]
Slingshot support is supplied via libfabric, also known as the Open Fabrics Interface (OFI), which defines a communication API for high-performance parallel and distributed applications. For this reason, Open MPI works at the libfabric level to ensure good integration. This includes expanded support for shared memory by combining NIC support with shared memory to intelligently choose between the two at the libfabric level.
Bernholdt noted, “Open MPI uses a strategy that’s focused on the OFI level to support Slingshot-11 (the team has implemented a new OFI provider called LinkX, which in effect multiplexes multiple OFI providers for SS-11), the CXI provider for the Cassini NIC, and a shared memory provider for on-node communication.”
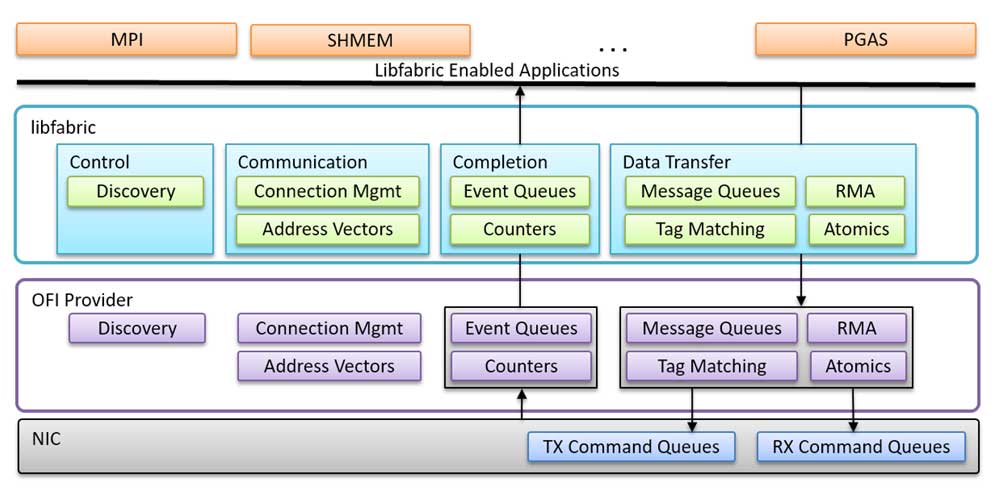
Figure 6. Libfabric provides a low-level library interface and enables expanded support for shmem.
Enhanced Scalability and Quality Assurance and Testing
The latest MPI 4.0 standard made many changes that reduce or eliminate many scaling and performance limitations of previous MPI standards and library implementations. Recognizing that programmers will not take advantage ofleverage these new features if the implementations are buggy, the OMPI-X team has focused on quality assurance and software test suites. Bernholdt summarized this by saying, “With a focus on testing, we have your back for performance portability and MPI 4.0 standards compliance to the exascale.”
With a focus on testing, we have your back for performance portability and MPI 4.0 standards compliance to the exascale. — David Bernholdt
MPI Implementations and MPI 4.0 Specification Compatibility
The MPI Forum is an excellent resource for those curious about MPI and its specifications, and the University of Southern California has an excellent write up about various MPI implementations (e.g., Open MPI, MPICH, MVAPICH2, and Intel MPI).[30] Notably, both Open MPI and MPICH have MPI 4.0 compatibility.
Summary
Programmers must pay attention to the latest updates to the MPI 4.0 standard because the new enhancements can significantly improve performance in threaded and heterogenous computing environments. Several software implementations are now available, including MPICH release 4.0 and the Open MPI v5.0.x series. Owing to the efforts of many, including the OMPI-X team, programmers can now use many of these performance enhancements in the latest release of Open MPI.
These updates strive to eliminate lock inefficiencies in parallel codes, support CPU+GPU heterogeneity, and reduce resource utilization in runtimes that utilize 100,000+ concurrent threads of execution. Heterogenous CPU+GPU architectures have increased the importance of hybrid programming models in which node-level programming models (e.g., OpenMP) are coupled with MPI in what is commonly referred to as MPI+X. Enhancements extend down to the low-level libfabric API to enable portability and the ability to more efficiently choose to communicate over a NIC or via shmem. Optimization efforts are in progress for modern communications fabrics, including the HPE Cray Slingshot fabric. Overall performance portability and robustness is enabled by additions to the MPI test suite and the CI efforts.
This research was supported by the Exascale Computing Project (17-SC-20-SC), a joint project of the U.S. Department of Energy’s Office of Science and National Nuclear Security Administration, responsible for delivering a capable exascale ecosystem, including software, applications, and hardware technology, to support the nation’s exascale computing imperative.
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national laboratories and commercial organizations.
[1] https://dl.acm.org/doi/fullHtml/10.1145/3458744.3474046
[2] D. E. Bernholdt, S. Boehm, G. Bosilca, M. G. Venkata, R. E. Grant, T. Naughton, H. P. Pritchard, M. Schulz, and G. R. Vallee, “Ecp milestone report a survey of mpi usage in the us exascale computing project wbs 2.3. 1.11 open mpi for exascale (ompi-x)(formerly wbs 1.3. 1.13), milestone stpm13-1/st-pr-13-1000.”
[3] https://www.osti.gov/servlets/purl/1373234
[4] https://www.osti.gov/biblio/1186781
[5] https://journals.sagepub.com/doi/abs/10.1177/1094342015623623
[6] https://onlinelibrary.wiley.com/doi/abs/10.1002/cpe.4863
[7] https://ieeexplore.ieee.org/document/7013060
[8] See the introduction in https://www.osti.gov/servlets/purl/1826433
[9] https://netlib.org/utk/people/JackDongarra/PAPERS/han-ieee-cluster-2020.pdf
[10] https://dl.acm.org/doi/abs/10.1145/3555819.3555856
[11] ibid
[12] https://dl.acm.org/doi/10.1145/2966884.2966915
[13] https://dl.acm.org/doi/abs/10.1145/3555819.3555856
[14] R. Grant, A. Skjellum, and P. V. Bangalore, “Lightweight threading with MPI using persistent communications semantics,” Tech. rep., Sandia National 755 Lab.(SNL-NM), Albuquerque, NM (United States) (2015).
[15] J. Dinan, R. E. Grant, P. Balaji, D. Goodell, D. Miller, M. Snir, and R. Thakur, “Enabling communication concurrency through flexible MPI endpoints,” Int. Jour. of High Performance Computing Applications 28 (4) (2014) 390–405.
[16] G. Gunow, J. R. Tramm, et al. “SimpleMOC – a performance abstraction for 3D MOC.”
In ANS MC2015. American Nuclear Society, American Nuclear Society, 2015.
[17] M. A. Heroux, D. W. Doerfler, et al. “Improving performance via mini-applications.”
Sandia National Laboratories, Tech. Rep. SAND2009-5574, 3, 2009
[18] https://www.sciencedirect.com/science/article/abs/pii/S0167819121000752
[19] https://par.nsf.gov/servlets/purl/10296871
[20] https://www.sciencedirect.com/science/article/abs/pii/S0167819121000752
[21] https://www.sciencedirect.com/science/article/abs/pii/S0167739X1930860X
[22] https://doi.org/10.1016/j.future.2020.01.026
[23] https://onlinelibrary.wiley.com/doi/10.1002/cpe.4863
[24] https://ieeexplore.ieee.org/document/9499495
[25] https://arxiv.org/abs/2102.06896
[26] ibid
[27] See note 24.
[28] https://www.openfabrics.org/wp-content/uploads/2022-workshop/2022-workshop-presentations/102_DKPanda.pdf
[29] http://nowlab.cse.ohio-state.edu/static/media/talks/slide/kawthar-slingshot-osu-booth-sc22.pdf
[30] https://www.carc.usc.edu/user-information/user-guides/software-and-programming/mpi