Special—ECP Leadership Discusses Project Highlights, Challenges, and the Expected Impact of Exascale Computing

Transcript

Mike Bernhardt, Oak Ridge National Laboratory, ECP communications manager
Bernhardt: Welcome to this special episode of Let’s Talk Exascale. For this special update, I’m your host, Mike Bernhardt. I’ll be joined today by members of the leadership team of the US Department of Energy’s Exascale Computing Project. Today we’ll cover the state of the project and we’ll hear from the leaders of Application Development, Software Technology, and Hardware and Integration. But before we get into those interviews, let’s go over to our producer, Scott Gibson, for a brief project overview. Scott . . .
Gibson: All right. Thanks, Mike. If you have just started following the US Exascale Computing Project—we refer to it as ECP—ECP is a seven-year project developed to deliver on some key mission objectives, some that we will discuss in this program. Most notably, a portfolio of twenty-four specific, targeted applications, along with seventy software products being prepared for exascale as part of the nation’s first exascale software stack. ECP is integrating those elements with specific hardware technologies for exascale system instantiations. The integration is being done in very close collaboration with DOE’s high-performance computing facilities that will house the country’s forthcoming exascale platforms. That’s what’s unique about these projects.
In summary, the mission outcome of the ECP is the accelerated delivery of a capable and sustainable exascale computing ecosystem. This ecosystem is necessary to enable breakthrough solutions to the nation’s most critical challenges in scientific discovery, energy assurance, economic competitiveness, and national security.
Bernhardt: More information on the Exascale Computing Project can be found online at exascaleproject.org. So, with that very brief project introduction, let’s move on to our first two guests. Doug Kothe from Oak Ridge National Laboratory, the project director, and Lori Diachin from Lawrence Livermore National Laboratory, the project’s deputy director.
So Doug and Lori, thanks for joining us today for this special update.
Kothe: Good to be here, Mike. Thanks.
Diachin: Thanks, Mike.
Bernhardt: You bet. Doug, why don’t you get us started. Perhaps we could kick off this episode with just a few noteworthy highlights that you’d like to share with our followers. I know there’s been some staff changes this year. Could you bring everyone up to speed on those?

Doug Kothe, Oak Ridge National Laboratory, ECP director
Kothe: Yeah, sure, Mike. And we’re really fortunate to have a great leadership team. It’s, gosh, over thirty people, and our project office as well are on their game, believe me, in terms of project management. But since we have last talked, Lois Curfman McInnes from Argonne has moved in to help Mike Heroux [Sandia]. She’s from Argonne, to help Mike Heroux run the overall ST, Software Technology, effort. Lois has had a stellar career. Among her many accomplishments, she was recognized with the DOE Ernest Orlando Lawrence Award in 2011. We’re just really fortunate to have her leadership. She takes over for Jonathan Carter, who is now an associate lab director at Lawrence Berkeley. Lois previously ran the Math Libraries area, and so that vacated position is now being led by Sherry Li at Lawrence Berkeley—she’s doing a great job as well. And also in the Application Development area, the Earth and Space Sciences area is now led by Dan Martin at Lawrence Berkeley. Well, actually, the one I forgot to mention is Katy Antypas from Lawrence Berkeley, who is leading our Hardware and Integration focus area, which is very, very important as we move into this deployment phase. She and Susan Coghlan from Argonne, the HI deputy director, are doing a great job and really moving aggressively forward. Katie takes over for Terri Quinn, who returned full time back to deploying El Capitan at Lawrence Livermore. Terri was with us for the first five years. Did a fantastic job. Really bringing the Hardware and Integration focus area up to where it is now. So we have had some changeovers. Not surprising. And, fortunately, we have some really great people who were just ready, willing, and able to step in and have been doing so since we’ve last talked.
Bernhardt: So Doug, the project completed a significant milestone in February with the CD-2/3 review. Could you talk just a bit about that? And what was the review? Why was it such an important milestone? And, of course, how did everything go?
Kothe: Good question. So ECP is a unique project in that we’re formally considered what’s called a line-item construction project and follow some fairly rigorous project management guidelines and constraints. And they’re known as Department of Energy 413. That said, as part of the 413 process, these large projects—and ECP is one of them—go through five gates, critical decisions 0 through 4. Zero meaning at the beginning of the project, there was a mission need made, the requirements were set, and 4 meaning the successful completion. So along the way you have 1, 2, and 3. We had a review last December to essentially get approval for critical decision /3, which essentially means that we have locked in our baseline, our schedule, and our cost commitments to between now and the end of the project when we have to deliver on quantitative key performance parameters, or KPPs. It is, I think, by all measures, the most critical review in the life of a project. We really are getting commitment for a formal baseline, and so in our case we’re committing to a certain cost range. We’re committing to quantified key performance parameters. So the leadership team and all the eighty-two projects had to work hard to lay out a four-year, fiscal year 2020 through 2023 plan, fairly detailed plan in terms of milestones, deliverables, how we are going to measure progress, etc. And we were reviewed very deeply and broadly, I think by the best and the brightest in terms of DOE federal officials who really know good project management as well as our colleagues and peers out there. So we’re really fortunate. The review went very well. We received a couple of very positive recommendations moving forward. And we’re really now focusing on execution, and it’s a very exciting time for us. We’re really over halfway, and think we see a good path forward for successful completion.
Bernhardt: That’s outstanding, Doug. Lori, let me swing over to a question for you. Now, you’re right at around your second anniversary as the deputy project director for the ECP. As I recall, you were new to the 413 project environment when you joined ECP, so what’s that been like in terms of assimilating into an environment that, well, many people in HPC will never get to experience?

Lori Diachin, Lawrence Livermore National Laboratory, ECP deputy director
Diachin: Yes, that is certainly true. I’ve been with ECP for just about two years now. I think my anniversary is actually this week. And one of the most challenging things for me to try and come up to speed on was working in the context of the 413 project orders. There are a number of constraints that are placed on ECP by that order, so it’s been a real challenge. And there have actually been a lot of very philosophical discussions around how we best manage a research, development, and deployment project in the context of rules that were originally set aside for, as Doug mentioned, line-item construction. And so, it’s been very interesting to think about how we can add value to the project in terms of formally managing our risk, formally laying out our plans and our baseline for the CD-2/3 review, and all of the other items that we need to do and the documents that we need to prepare for 413 compliance that make them also valuable in the context of a big research project. So it certainly has added a lot of complexity to the management of the ECP, but we do have a world-class project management team that keeps us basically all on track and keeps us going with respect to the 413 requirements that made it possible for us to really focus more on the technical work while they make sure we’re meeting the needs that we have for 413.
Bernhardt: OK. Doug, back to you. Could you give us some examples of progress against the project’s identified goals, the key performance parameters, maybe some examples from Application Development and Software Technology areas?
Kothe: Sure, Mike. And just to sort of reiterate the importance of key performance parameters, it’s our formal handshake with our Department of Energy sponsors on whether we succeed or not. That said, our KPPs don’t cover the breadth and depth of scope, and so we believe that success for ECP is, in the end, much broader than our KPPs. With that said, our KPPs really do keep us focused on critical outcomes. In particular, our twenty-four application projects are divided into two key performance parameters. I think eleven of our applications are on the hook for showing 50x performance relative to the start of the projects, circa 2016, in terms of science work rate. And each application has its own definition of a science work rate. For a Monte Carlo simulation example, it’s particles per second, really, to dictate the quality and the rate of doing science. In any case, of those eleven applications, they also have to show that they’re able to address or execute an exascale-class challenge problem. The point is, for these eleven apps, we’re seeing anywhere from 7x to 200x performance increase just on Summit, with the bar being 50 or more for those applications. That doesn’t mean the ones that are over 50 are done, because they’ve got to show that they can actually achieve that on an exascale system—not Summit, but the exascale system—and address their challenge problem. But we’re really very pleased with the progress and for those applications, for the most part, very much exceeding performance expectations.
Now, I would say, just to reiterate, each application has its own unique plan. It’s not just a computer science exercise. That’s hard enough, frankly. But it’s software restructure, redesign. It’s algorithm redesign or reformulation. It’s new and enhanced physical models. So it’s a pretty heavy lift for the applications. Another thirteen applications rounding out the twenty-four have a line of sight to just showing they can execute a challenge problem, and we believe we’re on track there as well. In this case, they’re not on the hook for 50x because they’re new, non-traditional applications. Maybe the software didn’t exist prior to ECP. And so, in the Application Development [AD] space, Andrew Siegel at Argonne and Erik Draeger at Livermore are leading this effort. We feel very, very good about it. We’re doing a good job, certainly, talking to you and Scott and working on our website and getting examples of successes along the way in terms of application reports, the podcasts, etc. And so I certainly encourage folks to plug in and listen in for more detailed examples.
In the Software Technology area, Mike Heroux and Lois are doing a great job and really figuring out not just what packages and products are needed to have our applications succeed but what’s useful on the facilities. Their portfolio is broken up into seventy distinct products—that number will likely grow. And each one of those products has a very specific integration metric to meet. By integration here, we’re really talking about deploying on specific facilities being critical for a certain application, contributing to a key open-source package, driving standards. There’s a number of integration metrics that we really have incentivized with our software performance parameter. Lori here has done a great job of really driving that effort forward. The point is, the Software Technology portfolio—seventy products that are now packaged into a half-dozen distinct software-development kits are being released as we speak through the Extreme-scale Scientific Software Stack, or E4S. So at E4S.io online, you can find our latest release, and I believe we’ve had three or four releases. So every six months or so we’re pushing out further releases. Even though we’re not done, we do think that the software stack will be long-lived beyond ECP. We’re pushing out releases early and often, so folks can give the software products a test run, test them out, let us know how the products are doing, how they’re helping them. In particular, we have over three-and-a-half years left, and that can influence our development as well. So we’re really pleased with regard to progress in software and in applications.
In conclusion, the Hardware and Integration focus area, led by Katie and Susan, really takes our apps and technology products across the finish line. We’ve not succeeded until we’ve deployed these products and they’re up and running, they’re tested, they’re production-hardened on the facilities. And so it’s not just building and delivering, but we’ve got to deploy the software products and the apps. They’re doing a great job in standing up technologies and tools and starting this testing and deployment already on the pre-exascale system, so this is a key kind of third pillar that’s required for success. So a lot of great progress has been made there as well.
Bernhardt: All right. Thanks, Doug. Lori, I’ve got another question for you. To sit back and look at this, the project has hundreds of activity streams flying around at any given time—milestone accomplishments, highlights, challenges to deal with, risk identification, risk mitigation. You know, the list just goes on. So many details to be balanced, some intricate points of connectivity among the researchers. As the deputy director, you have to be in the loop on the entire portfolio of ECP activities. How do you manage that level of communication and awareness across all these project activities?
Diachin: Yes, that is a challenge. The ECP, of course, spans nearly all the DOE laboratories and several universities and industry, and so it’s a very broad-based activity, with researchers spread around the country. So there’s a lot of communication infrastructure that has been put in place and has been absolutely critical to the project’s success. I think most notably for me, the things that have been critical are our Confluence site and our Jira site, the Atlassian tools we’re using for project management, where we capture a lot of the milestones, a lot of the issues that we’re tracking at any given time. It’s where we’ve developed things like the integration database, which is allowing us to track critical dependencies between our Application Development teams and our Software Technology teams. It’s where we track, for example, progress on continuous integration. And so that’s really a one-stop shop for a lot of detailed and useful information about the project that we can refer to. In addition to that, we have a number of team meetings with our senior leadership team, our extended leadership team, with our stakeholders at the facilities, with our sponsors in the DOE. And those communication mechanisms are, again, quite critical for making sure that the team as a whole is on track. In addition to that, we hold monthly PI calls, where we speak to the entire team and let them know what’s going on and discuss crosscutting issues. So there’s just a multitude of high-level and sophisticated project management tools that we’re employing to try and keep the ECP well informed, both among the leadership team and with the team members. And then also, the leadership team is very available, I think, to the PIs. The L3s work and interact weekly with their L4 project leads. The L2s interact all the time with their L3s. We’re interacting with the L2s. So, while it’s hierarchical, there’s a lot of communication up and down the chain that, I think, makes a project of this size successful.
Bernhardt: So Lori, what would you say are some of the highlights for you, personally, looking back on this past, say, eight or nine months?
Diachin: I think the highlights for me continue to be to work with this management team. Both at the L2 and the L3 level, I have a lot of interactions with those folks, and they’re just top-notch, world-class researchers who really care about the ECP and moving it forward and solving the problems as they arise for the L4 technical teams as they’re working. It’s just been a tremendous experience to work with a team of this caliber. So, for me, that’s first and foremost. The second, I would say, is starting to really see a lot of the crosscut activities that are enabled by the ECP. Because we are so large and bring so many researchers together, we’re able to do things within ECP that we couldn’t really have done without a project of this size. So the Extreme-scale Scientific Software Stack, the E4S, is one of those activities where we are developing and hardening software to be deployed on the facilities in ways that should make it much easier for application teams to take advantage of and leverage the software that’s produced by the Software Technology teams. In addition, I think we’re seeing some very impressive early results by the application teams on Summit. There’s a lot of new capabilities that have been developed as part of ECP on their way to get to their challenge problems, and that’s been very exciting to see those start to come to fruition. And you know it will only get better and better as we go along for the next three years or so.
And then, finally, another opportunity that we’ve had as part of the ECP—because we are so closely connected with the facilities and all the facilities in the DOE—we’ve been able to develop our continuous integration cycle, and we’ve been working toward that for the last couple of years. And it’s now starting to come to fruition where the infrastructure is in place that allows Software Technology teams to test their software at the facilities in very quick turnaround so that they can quickly find bugs and deploy very good, robust hardened software. And because of all this effort that we have—all these artifacts that are coming into a place because of the size of our team and the amount of resources we’re able to put into our exascale ecosystem—we’re seeing that we have a lot of influence in the international community. And that, I believe, will have a very long-lasting legacy for the ECP. The artifacts that we’re developing on the software side, the influence that we’re having, both within the US and internationally, and the workforce that we’re training to take advantage of and be able to effectively leverage accelerator-based architectures, is something that’s been very exciting for me over the last eight or nine months of the project.
Bernhardt: Fantastic. Doug, looking forward, what can we look for from the ECP for the remainder of this year and into 2021?
Kothe: Sure, Mike. Good question. So first of all, one of the recommendations from our review last December was to be more aggressive in outreach. Not that we’ve got everything figured out, but to get lessons learned out—what works, what doesn’t. So certainly with Let’s Talk Exascale with you and Scott, we want to do more and more podcasts, which I think have been very, very useful, but push out as many of our technical reports and milestone reports as we can, special journal issues, workshops, webinars—we’re going to be more aggressive there—and we do rely really heavily on the fact that what we’re developing is going to be used and useful for science and engineering within the DOE, certainly, but also our community writ large. The point is, continued interaction with our stakeholders, our DOE sponsors and stakeholders, are going to be very, very important. With regard to this year and next, it’s a real litmus test for us. We believe we’re on a good track in terms of being able to exploit accelerated node technology—not just NVIDIA, but AMD and Intel—and so far, we’re beginning to get our hands on early hardware, and the returns are good, meaning what we’ve learned on Summit and other NVIDIA-based platforms seems to be carrying over quite well. Not that this is easy, but we do believe this time next year we’ll have a fair amount of experience on early hardware, and in roughly a year from now, we’ll start seeing the actual hardware from exascale systems hit the floor and really begin to make sure that the R&D investments we’ve been making with regard to exploiting these technologies . . . we’ll see whether they’ll bear fruit or not. We’re very confident we’re heading in the right direction. But, boy, it’s an exciting time because the hardware is finally coming and we’re getting the chance to roll up our sleeves and test it. And so far, so good. But that’s going to be a big push for us in the coming year. So this time next year I think we’ll have a lot more to say about the investment and its return so far to date.
Bernhardt: OK. So Lori, thinking about ECP’s legacy, how does the project pass along the knowledge learned by this team to the broader community?
Diachin: I think there are several avenues that the ECP is using to pass along what we have learned to the broader community. There’s certainly all the work that we traditionally do in publishing our research, speaking at conferences—even though many of those speaking engagements are now virtual. We’re still getting the word out about the things that we’re learning by deploying software and applications on these systems and how others can best make use of them. Our teams also are very actively engaged in putting together tutorials at major conferences like the SC20 conference that’s coming up—we’ll have a number of tutorials related to ECP technologies that will allow the broader community to start using them to move them forward in their own work. And then, finally, of course, putting together all the tools in one place and all the documentation that we need for what the HPC community will need moving forward is yet another legacy for what the ECP will provide at the end of our project that will be useful for a broader spectrum of users in high-performance computing.
Bernhardt: Fantastic. So I have one more question. I’ll just throw it out there, and go at it if either of you want to. A recent presentation at the ISC conference in June was focused on emerging technologies. There was a mention of more than a hundred companies focusing on hardware for machine learning. That was pretty interesting. But overall for HPC, the message was around architectural design. Specifically, architectural design will become the differentiator in a world where there’s likely only two to three fabs driving process technologies. When I heard that and I saw it on a slide, it really got me thinking about how HPC is entering a new era not just for exascale, but a new era of innovation at an architectural level, with many new companies entering the market, as we saw names I hadn’t been familiar with such as SambaNova, Groq, and NextSilicon, just to mention a few that were highlighted at ISC.
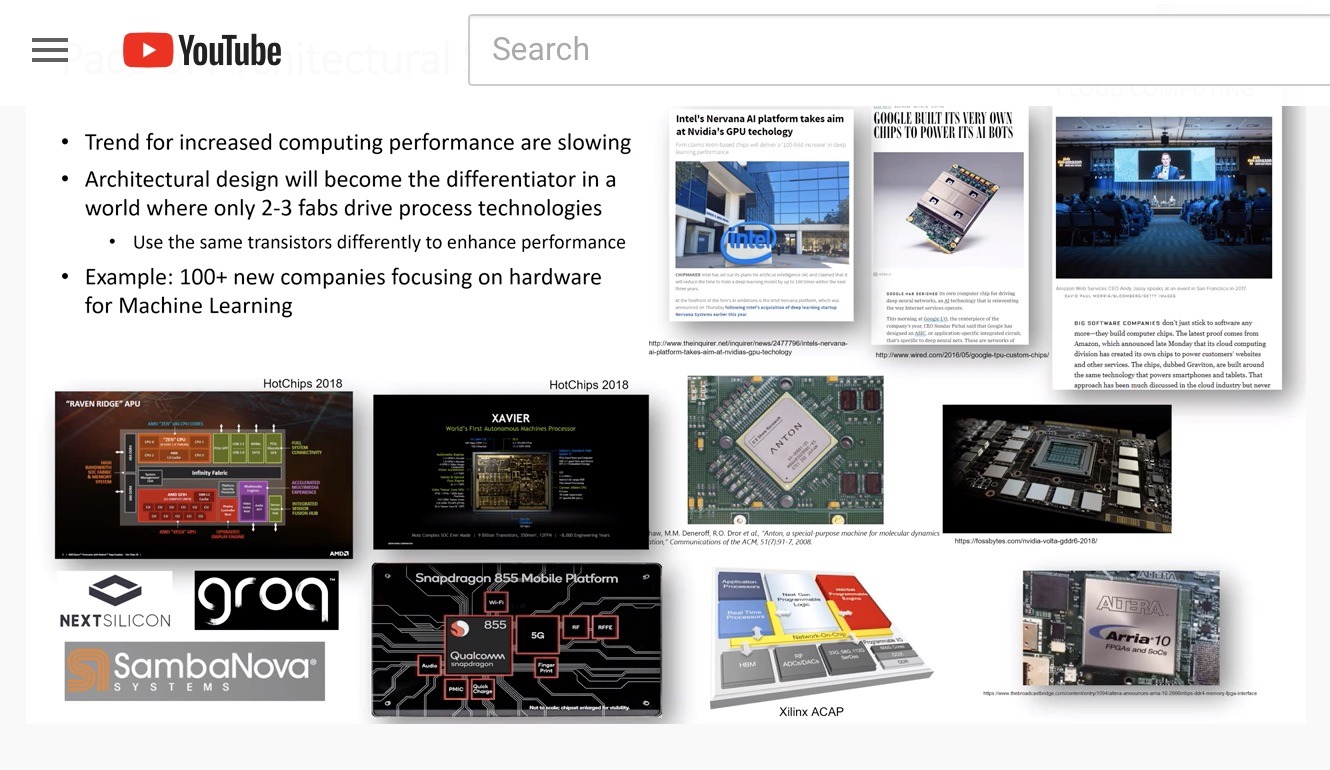
This slide on architectural design becoming the differentiator in high-performance computing was presented at ISC 2020 by Karen Bergman of Columbia University.
So what do you think will be the interesting trends to watch? Where do you see potential for advancements in HPC based on new architectural designs or other advancements?
Kothe: Mike, I’ll jump in. This is a real exciting time with so many different hardware vendors and hardware shops, essentially, out there. In ECP, we are spending a lot of time figuring out how, and I think we’ve been successful in exploiting the NVIDIA hardware. And I would call a lot of our activities hardware-driven algorithm design. In other words, how can we best use the MMA capabilities of, say, the Volta for traditional PDEs and not just machine learning and AI? I think our PathForward effort really did invest upstream with the six US HPC vendors to focus kind of on the opposite, which was really algorithm-driven hardware design. So, we’ve really seen in ECP’s lifetime, co-design going both ways. But I’ll just add that our co-design centers—when, in fact, we’re really doing co-design all across ECP—but what we call co-design centers focuses on computational motifs, and these are very common patterns of communication and computation in our applications. And so we’re beginning to develop a pretty good feeling and strong opinion for the kinds of hardware design that would really make those motifs scream, whether it’s particles, unstructured mesh, structured mesh, etc. So I think moving forward, we’re going to see more algorithm hardware design, and certainly the AI/machine learning is a big area. But I think we’re going to see hardware really more tuned and designed very proactively for things like our motifs. Post-ECP, there’s going to be, as Lori says, the talent and the expertise but also the software technology really well positioned to inform algorithm-specific hardware designs. So, I think what you noted, we’re going to see a lot more of. It’s going to be kind of the wild west moving forward, and that’s a pretty fun outlook.
Diachin: And let me add to that a little bit. While it’s a fun outlook on the hardware side to have the wild west coming our way, it’s a little more daunting on the software technology side. How do you design your software to achieve performance portability and isolate kernels in ways that allow you to take advantage of the different architectures that will be coming online? So we’re beginning to see this now, and in the ECP we’re certainly investing in that in the ECP through efforts like Kokkos and RAJA, but I think we’ll see even more of that as we go forward. Application scientists and software technology folks will need to invest additional effort to isolate those key kernels that they can then make performance portable across a wide range of architectures.
Bernhardt: Our thanks to Doug Kothe and Lori Diachin for joining us today. You’re listening to Let’s Talk Exascale.
Application Development
Bernhardt: Let’s move on to the ECP’s Application Development group. And for that conversation, we’re joined today by Andrew Siegel from Argonne National Laboratory and Erik Draeger from Lawrence Livermore National Laboratory. Andrew is, of course, the director of ECP’s Application Development, and Erik is the Application Development deputy director. Andrew and Erik—with an amazing team of application development experts that span the entire country—are managing a portfolio of twenty-four applications that are being prepared for exascale. So Andrew, why don’t you start us off. What would you like to share with the followers in terms of some of the highlights from the team for the first half of this year?
Siegel: Okay. Thanks, Mike. I think probably the most important thing that we’ve accomplished so far this year when you look across all twenty-four applications is the success that we’ve had importing the real fundamental components, or pillars, of computational physics to the multi-GPU systems which are on the path to the exascale computers. So when I say the pillars of computational physics, I mean success importing computational fluid dynamics, molecular dynamics, particle transport, reactive flows, various different approaches to quantum chemistry. So these different pillars of physics are present across many of the different applications. And moving them from CPUs to performing well on multi-GPU systems has been a really big step forward for the project.

Andrew Siegel, Argonne National Laboratory, ECP Application Development director
Now, we also think a lot in the project about performance, and the question is, what kind of performance have we seen on the largest intermediate system that lies between where we started and the exascale platforms? And that would be the Summit supercomputer at Oak Ridge National Laboratory, which is nominally a 200-petaflop machine. And so I think the next big thing to point out is how surprised we’ve been that a number of our applications have surpassed all expectations of performance on the systems. So I don’t want to make it sound too easy either. I think there’s been a big range. We’ve seen performance improvements from between a factor of, say, 6 or 7, all the way up to a factor of 100 in the challenge problems that have been target of these application domain projects. So performance on Summit has been mixed but has been very positive overall to this point. And that gives us, I think, a lot of optimism that we’re going to continue to improve performance on these exascale systems.
Probably the next thing are our early experiences on the AMD and Intel GPUs, which are going to be the backbone of the exascale systems. So we have early versions of these systems, very early stages of the hardware, and we’ve had a chance to get on these systems and play with the software environment, look at early issues, and performance, and make projections about what some of the biggest challenges will be going forward. And all of the experiences we’ve collected, best lessons or feedback to vendors, to what’s working and what isn’t, has really taken us much closer to realizing the goals of the project and given us a lot of optimism about how things will go once we actually get those systems.
I think probably the last thing is just some of the early successes in software integration. It’s been very hard traditionally in HPC to get domain experts to depend on software components that help ease the transition from moving their code from one system to another code system or improving their performance. And, of course, we’ve had a lot of different activities going on in ECP. But incorporating fundamental software components, finite element solvers, adaptive mesh refinement, and particle and mesh solvers into application projects in order to sort of lower the bar for the amount of work they need to do to get performance on these systems has been a pleasant surprise. So those are four things that come to mind immediately, Mike. I’m sure there are others, but those really jump out at me.
Draeger: And, Mike, if I may, I’d like to also exemplify a couple of specific application highlights just to sort of give a little bit more depth to what Andrew was talking about in terms of some of the recent successes we’ve had. One such example is the LatticeQCD project. This is our application targeting quantum chromodynamics to explore the fundamental properties of subatomic nuclear physics. This is a method that’s been around for quite a while, and it’s incredibly computationally expensive. It takes a lot of compute power to solve some of these model problems they want to explore. So it’s a natural fit for exascale computing. However, what they’ve discovered is that as they’ve gotten to larger and larger scales that in addition to the challenges of making their code work well on a big supercomputer—and, in particular, a GPU exascale supercomputer—they also have underlying mathematical barriers that they’re bumping into. And this is what’s known in our community as critical slowing down, whereas the problem gets higher and higher resolution, with finer and finer scales for their solvers, they have a disproportionate increase of cost in solving these problems as they get to the larger scales. And so not only do they have to solve the compute problem of how to make this very complicated method run well on a big, complicated supercomputer, they also now have a math problem they have to figure out, which is how to change their algorithms to address this issue that’s not at all a compute problem but very much a fundamental algorithm problem. And they recently had a big advance in this, where they’ve been able to prototype a new multigrid method that gets around this critical slowing down issue, and they actually just submitted this [Multigrid for Chiral Lattice Fermions: Domain Wall] for publication. We think this is a really exciting advance and really shows that this is not a straightforward porting problem. This is really a computational science problem at all levels. And so we’re very excited to see our teams address these types of issues, because it really shows that we’re thinking long-term about how to advance computing in a fundamental way.
Another highlight I’d like to mention is the E3SM-MMF, our climate project. It has also demonstrated a recent success on the Summit supercomputer that we’re very excited about. As you know, climate modeling is an incredibly complex multi-physics method. It’s very challenging. And these methods have been developed over decades. So, you’re dealing with codes that were written well before we knew GPUs were going to become as ubiquitous as they are. Yet you can’t just simply scrap them and start over. You have to work with this code that you have and find a way to make it run well on a totally different type of hardware than it was developed for. It’s a Fortran code, which, as many of our listeners will know, adds challenges in terms of how one ports to a GPU, but they’re using some of the best methods of the time in terms of OpenACC and OpenMP to address that. However, they recently found that rewriting a key component in C++ they were able to leverage the Kokkos abstraction layer to get portability and performance on the Summit GPUs with a reasonable amount of effort that maintains their CPU performance. So this is really important for them because these are large community codes, and they can’t take them offline. But because of this work, they were able to hit a milestone where they simulate a year in their Earth system model at high resolution—less than 3 kilometers—in less than a day on a supercomputer. And that’s an advance of over a hundred fold from where they started. So this is actually a big jump forward in the capabilities of high-resolution climate modeling, and they believe this is going to allow them to do cloud-resolving climate simulations over decades, which will remove a major piece of prediction uncertainty in the current climate models. So, we like to see these sorts of successes. We anticipate they’re going to continue, but, again, this is really a sign that as we go on, we’re seeing big advances already.

Bernhardt: So maybe you guys could help break this down. We, the HPC community, we’ve been around porting applications to generational advances of supercomputers for decades. What is the big deal here? Is it the hardware? Is it the complexity of the software integration? Why is the effort to prepare twenty-four exascale applications such a massive effort?
Siegel: Well, yes, exactly, the simple answer, Mike, is hardware. But it’s also more practically how you program the hardware, in particular to get good performance, because we don’t need to just port in ECP, we need to port with a very high threshold of performance improvement that needs to be demonstrated. So, as you know, traditionally in HPC, getting better performance of the next generation of hardware meant scaling up many MPI processes—usually of conventional or something like conventional CPUs—and that trajectory of performance improvement kind of fizzled out.
And we took the approach in this country to explore GPUs. And GPUs are different. Like all hardware, they perform well in a natural way with certain computational patterns, and they don’t perform as well with others. Right? Obviously, they like extreme amounts of parallelism, particularly when there’s a lot of instruction-level parallelism present. The code has to be really resonant on the accelerators, especially as we move toward the exascale era, and you cannot have a lot of back-and-forth between the host and the device, because 97 percent of the floating-point performance of the system resides on the GPUs. And you have to amortize the expensive cost of data.
So we think about GPU-resident algorithms, and then just a lot of things that were sort of the case with CPUs. But now they’re more so with GPUs. We favor higher arithmetic intensity. We’re in an environment now where we have high floating-point-operations-to-bytes-of-RAM ratio. Right? So we’re trying to utilize all of these extra flops in an environment where the aggregate RAM was not growing very much. And that can be a difficult challenge for applications. There’s always the opportunity to make use of more-specialized operations like these tensor cores, which are generally targeting machine learning but now are being exploited for things like linear algebra. And that can be very, very difficult. And it’s really difficult to know how to quantify how well you’re doing at any point on these new systems. It’s a very difficult process to diagnose performance and to understand how far you are from doing as well as you could, to say what the next steps are. And the application codes that we’re dealing with, you have to understand, they’re very complex. They have different levels of verification and validation that we’ve built up over decades. Many support large user communities who expect to be able to use the codes continuously throughout the process of their moving to these very different systems.
And then to sort of build off of what Erik said, what is required, given everything I just said, is often major restructuring in the presence of supporting large user communities. So it can be things like porting, which you might think of as straightforward, although it isn’t straightforward. But it can involve things like laying out data in different ways and reordering loops, breaking loops up, and so forth. But then it extends, like Erik was suggesting, to looking at new ways of discretizing differential equations or integrated differential equations, and new ways to express these discretizations. So we might look more toward communication-avoiding algorithms or algorithms that, as I mentioned, have higher arithmetic intensity. Going to high-order methods has become very popular because they’re a more natural fit for this class of hardware. And then to see the moves to sort of new fundamental approaches to modeling. So it can be what haven’t you modeled historically that you’re going to tackle next? And that might be chosen, in part, based off of what looks good on this hardware. So there’s just a lot of moving parts.
I think the biggest thing to realize is that we are solving new problems in ECP. We’re not just solving larger versions of old problems. We’re solving older problems faster, because when you look at the trajectory of the deployment of the exascale systems, it is going to extend over sort of a generation of computational science. So if you’re in a particular domain field—fusion or if you’re studying nuclear reactors, for example—you’re going to look at the new opportunities that the hardware provides. You’re going to ask, what can you do that is new and exciting? Not, how can I get this answer faster? That could be part of it, certainly. Or not, how could I refine this grid more? But, how can I model neutrino transport or electron subcycling that I’ve never been able to model? All sorts of opportunities. There are a lot of moving parts.
And when you put the new hardware together with the difficulty of programming the hardware in the presence of user communities, and the presence of just all of the complexity of doing these science problems, this is what you get. It’s not easy. It’s extremely challenging.

Erik Draeger, Lawrence Livermore National Laboratory, ECP Application Development deputy director
Draeger: And just to add to what Andrew said, one big difference from the decades before that you mentioned is, not only are we having to rethink how we do computing to make use of accelerators and GPUs in a way that’s very different than how we did for the last several decades . . . But unlike the previous decades where code would run on a CPU regardless of the model or the manufacturer, pretty much out of the box—and then you could optimize to get slightly better performance—we are now facing a diversity of GPU manufacturers with, in most cases, very different native programming models.
So codes are faced with the choice of, do I target a single manufacturer like NVIDIA and write my code to work very well for those GPUs but risk it not working on the next machine that comes down the pike if they chose a different manufacturer for that GPU. Because, as we all know, you often have to make a trade-off between portability and performance. And so, these decisions are having to be made now with not a lot of information. And, as Andrew mentioned, many of the applications—and this includes the national security applications in ECP of which Livermore contributes—are faced with an issue where they can’t afford to be offline for years at a time while they radically rearchitect their codes, risking losing all the validation and verification information they’ve spent decades building. So the analogy that’s made is, essentially, these are people in an airplane in the air trying to build it without it crashing. So it’s a very challenging and difficult effort, and what we’re seeing is a lot of innovation in how people learn how to rearchitect codes to be more hardware agnostic and able to take advantage of these heterogeneous machines in a new way. And so, we’re excited by this because we think this will really help the broad community. But it’s a very difficult problem. It’s one of a kind.
Bernhardt: So we’re basically entering a whole new era in many ways. Here’s something I wonder about. While you guys have built a very respectable team of experts to work on these applications, in reality this is new for everyone. Scaling to exascale is unchartered territory. How do you prepare, train, work with the teams to help everyone advance their skills and learn from this collective experience?
Siegel: The first thing to realize, Mike, is that the domain experts cannot do it alone, and I think this is something that has become more and more of a case over the past fifteen, twenty years. But the current transition from CPUs to GPUs really magnifies it. So if you look at the teams—we mentioned twenty-four application projects—if you look at the composition of those teams themselves, there’s great diversity of expertise. You have applied mathematicians, software engineers, people with expertise in sort of the hardware algorithmic interface. And then they’re typically led by domain experts. And each of them sees the same problem in kind of a different way. They might see it as a verification problem. They might see it as, how well does it exercise the hardware? They might see it as, how accurate will my scientific result be? It’s the blending of these people and the ability to have the different perspectives all contribute to improvement of the same product that sort of determines our success.
And then, in addition, when we layer on top of that the fact that these systems are being deployed at the facilities—ALCF [Argonne Leadership Computing Facility], OLCF [Oak Ridge Leadership Computing Facility], and then at NERSC [National Energy Research Scientific Computing Center], which have a long history of fantastic application engineers who have a sort of breadth of experience supporting complex algorithms—to innovative hardware. And they understand the hardware deeply. They understand the computational patterns that perform well on the hardware. Of course, they don’t often see all the way up to the science or application level, but working together with the domain scientists, the progress can be tremendous. So it’s really important for us to leverage the relationships with the expertise that’s resident in the facilities. And we have a formal program to do that in ECP. Then there are the vendors themselves.
So we have in order centers of excellence with our vendors partners. They have dedicated people who are helping to design the programming models for these systems, who understand the hardware very deeply, who understand how to instrument these systems, understand performance. And, now, they’re almost embedded, just like these facilities engineers are, into these development teams. So it’s remarkable the number of people required to pull it off, but also the diversity of expertise that we have in order to be able to do it. That’s the most fundamental ingredient of our success, I would say, compared to twenty-five years ago when a single domain expert might try to build a code in Fortran, write it themselves, and analyze it themselves.
I think the last component maybe is what I alluded to earlier—the use of libraries, the use of components that other people have built. This is sort of a mixed bag in computational science, because in some ways you want not only to control everything yourself as the domain expert, but you also don’t want to depend on something that could be ephemeral, might not have funding in the future. People that you don’t know well. So there’s always been a little bit of suspicion of depending on libraries in order to lower the bar to getting performance on systems. But that culture’s really changing.
In ECP, as we’re sort of one big project that’s in a lot of ways tightly integrated, we see this as a great opportunity to help lower those barriers. So we’ve seen a lot of the burden removed from the domain experts to do all the low-level programming by collaboration with other components of ECP and with the open-source community at large using mathematical solvers, I/O infrastructure, programming models that, like Erik said, insulate you somewhat from the hardware, though I think that there’s a lot going on in ECP that’s different that has pushed the community forward. Of course, we also have really good regular ECP training that is publicly advertised and available to anybody that gets deeply into these different technical topics.
We have lots of sub-community meetings. We have an ECP-wide annual meeting, which is fantastic and which lasts a week. Always sharing experiences with group chats on Slack and so forth. And finally there’s the question of the pipeline. Do we have new people coming into the field? And we’ve done very well in that regard. I think if you take a very, very smart person with some background in hardware and numerical methods, and maybe some modeling and physics, and you kind of put them in the fire for six months, the field is still such that if you’re good and you’re dedicated, you can become productive very quickly even if it’s not part of a specific curriculum that you came from. I think we’re still doing really well in terms of a pipeline of really smart people, but it takes a lot of different people working together to pull this off. And ECP has been a unique opportunity in that regard.
Draeger: Yeah, and just to add to that a little bit. . . . ECP really represents a unique opportunity to get some of these economies of scale and reduce the duplication of effort as many different kinds of applications face very common challenges. And as Andrew mentioned, you know, we work very hard to give opportunities to teams, make sure they’re exposed to things they otherwise may not have been aware of in terms of libraries or programming models, or training. But that still is an ongoing challenge for us, and one that we think is actually really ramping up with the arrival of some of the early hardware systems that we have access to, because it’s really a balance between your wanting to make sure all teams have exposure to information that could help them without drowning them in just a tidal wave of information because there’s so much coming from all directions.
So, we’re really working hard to make sure that we can coordinate these early experiences between teams so that they can really benefit from what other roadblocks people are running into or ways they’ve found success on these early hardware platforms without making everyone have to know everything about everything. That’s really a management challenge, and it’s one that we’re continuing to work on. But it’s really important and it’s very gratifying when you see the team have success on very advanced and novel architectures, honestly.
Bernhardt: Awesome, guys. Thank you. All right. We’re about out of time, let me ask you for one quick sound bite of what you’d like to share with the ECP community. What are you looking forward to accomplishing over the rest of this calendar year?
Siegel: We’re probably most eager to get the next generation of early exascale hardware. There’s been a lot of work that is important in a sort of GPU-agnostic sense. So maybe it targeted NVIDIA, but there’s just a lot of code restructuring that, in theory, would help running on any multi-GPU-type system. Now the question is, how far along are we specifically for these exascale systems? And we have a very early peek into that, but we’ll get a much better look very soon as we get the next generation of pre-exascale hardware and start to really get a look at performance and ask ourselves if the really good numbers we’ve seen on Summit are going to continue to improve as we move toward Frontier and Aurora.
Draeger: I would just like to quote noted computational scientist Mike Tyson, who famously said, ‘Everyone has a plan until they get punched in the mouth.’ And this is what the rest of the year is going to be for us, actually seeing the rubber hit the road as these new types of GPUs come online and codes actually see if their plans are going to work on them. I’m very excited to see what comes out of this, and we’re going to be getting a lot more information in the coming months.
Bernhardt: Fantastic. Our thanks to Andrew Siegel and Erik Draeger.
Software Technology
Reusable software components are foundational to computing in general, but in HPC, and soon, in exascale, reusable components such as those in E4S are absolutely paramount to bridging the gap between applications and hardware, and at a level of complexity and sophistication beyond anything we’ve done previously. Our next guests own the Software Technology focus area for the ECP. We’re joined by Mike Heroux from Sandia National Laboratories and Lois Curfman McInnes from Argonne National Laboratory. Mike’s the director of ECP Software Technology, and Lois joins him as the team’s deputy director. Mike and Lois and the extended ECP Software Technology team are preparing fundamental capabilities for seventy software products as part of the nation’s first exascale software stack.

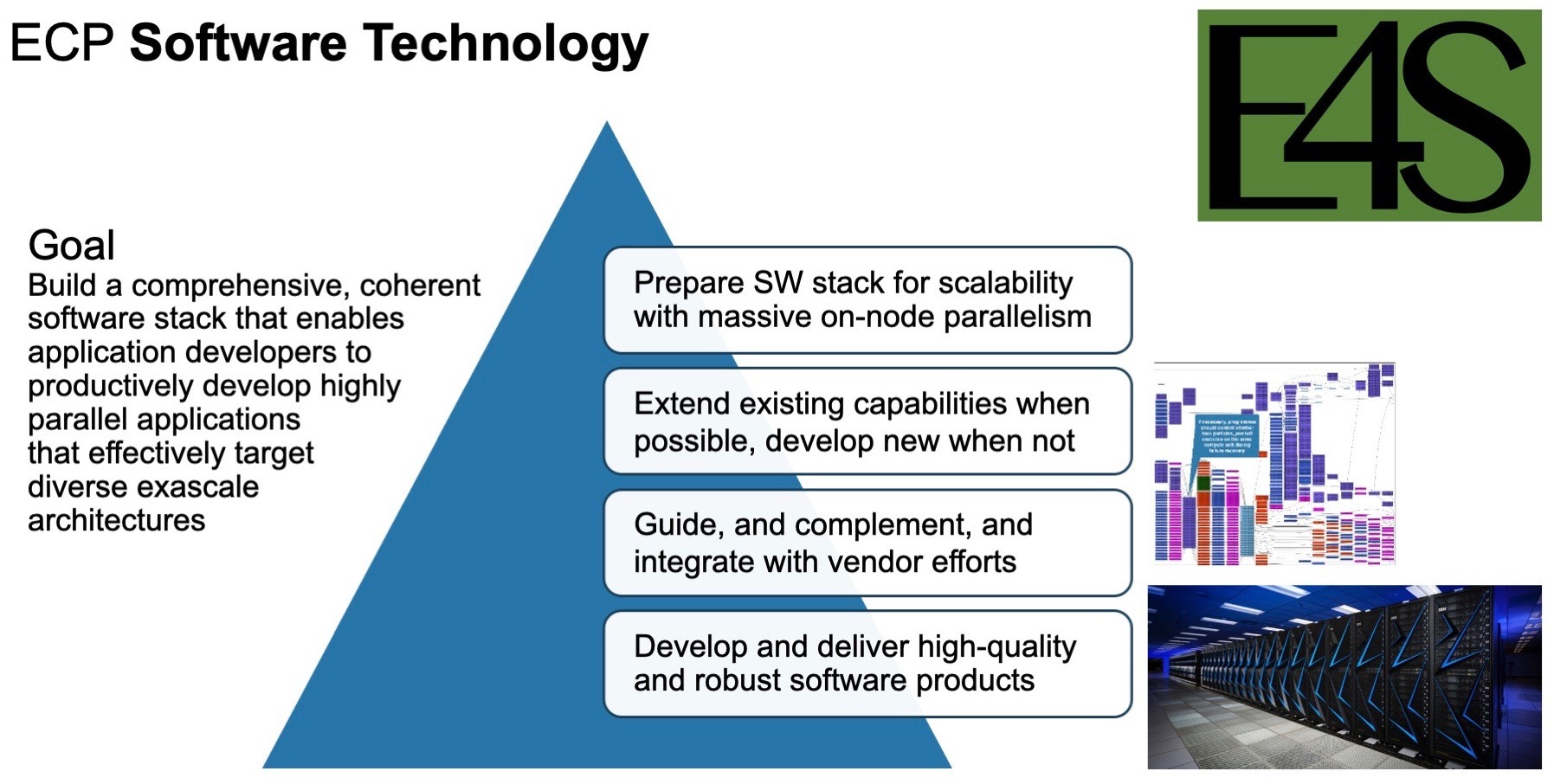

Mike, why don’t you kick things off for us. I’m guessing you know a little something about E4S. E4S, the Extreme-scale Scientific Software Stack. I think the first in-depth report we did on E4S was in conjunction with SC18.
Heroux: Yes, Mike. Thank you. Yes, we’re very excited about E4S, and as you said, it’s the Extreme-scale Scientific Software Stack. I think maybe I’ll point out first that in its name we didn’t call it the Exascale Scientific Software Stack, and that’s because we foresee E4S as being a new entity in this high-performance computing ecosystem.

Mike Heroux, Sandia National Laboratories, ECP Software Technology director
For the first time, we’re able to bring smaller, independent project groups of teams together and pull them together into a portfolio of capabilities with some value added. For a reasonably modest cost, we can bring and coordinate these independent projects. You mentioned the seventy to which we contribute, and we expect that to expand as time goes on to provide improved look and feel, a common documentation portal that we’ve made tremendous progress on in the past few months, value added by getting groups of teams that provide similar capabilities together into so-called Software Development Kits—these are teams of people who provide, say, development tools such as performance tools, mathematical libraries, I/O libraries, and visualization libraries, together in just small groups. So the math library teams are together trying to come up with sets of policies and interactions across teams, common tutorial material, things like that. By providing this kind of light layer of capability on top of what the individual teams are providing, E4S is creating this aggregate entity in the ecosystem that is very valuable for HPC.

Bernhardt: Lois, do you have anything to add? What do you think of when you think of highlights around E4S?

Lois Curfman McInnes, Argonne National Laboratory, ECP Software Technology deputy director
McInnes: I would augment what Mike said to just emphasize that our various software teams are interacting in ways that really focus on how they can bring together their complementary capabilities in ways that serve the needs of the applications throughout the ECP community, yet retain the independence of the individual teams to do what makes sense for them. So as Mike introduced, the Software Development Kit groups are coming to terms with what are the essential elements that they need in order to be able to collaborate together as part our ecosystem in the broader HPC community ecosystem and what parts really can they do in whatever ways they want. Those discussions have been really insightful and powerful in helping us as a community advance what we’re doing so that we can bring together sets of software technologies that support various applications. As a specific example, one of the application projects in fusion energy sciences, whole device modeling, is using more than twenty—upwards to thirty or so—of these products, within ECP, and so it’s essential that our community identifies ways to help that happen seamlessly.
Bernhardt: OK. And I think this is probably connected in many ways. I’ll bring this one back to you, Lois. The Software Technology group has had a lot of success preparing and delivering virtual events, and it seems that these days virtual events are going to be the name of the game for quite some time. Could you give us some snapshots of what the group has been doing with these virtual events and how that impacts the overall team?
McInnes: Indeed. So the software technologies teams and researchers are collaborating among the ECP community and specifically partnering with the training element of ECP; that’s part of the Hardware and Integration area. That training element is led by Ashley Barker and Osni Marques. And through that element, many teams have already been presenting a variety of webinars and training events to teach about their software technologies, and now that we’re going to virtual, we’re seeing an increase, actually, in the number of people who are able to attend some of the deeper tutorial-type trainings. As a specific example, going on right now is an online training event for the Spack project. Spack is a very powerful tool that’s helping with software installation, and this online event has exceeded the attendance of prior events because it’s drawing from a worldwide audience. So I’d say the teams are using technologies such as Zoom, such as Slack, and other innovative ways to make the interactions and online training as rich and meaningful as we can when we’re distributed.
Bernhardt: Mike, as I look at the interaction of your group, which is quite widespread, it’s clear that to be successful, Software Technology efforts cannot operate in a vacuum. Can you speak a bit on the integration aspect? How does Software Technology interact with applications and hardware efforts? I mean, how extensive is the integration overall?
Heroux: All of our teams have some direct connection to a subset of the Application Development portfolio to the AD teams that you just heard about, and they directly interact with those teams—as specific instances of how application integration will occur, but also as a representation of the broader group of application teams within ECP and outside of ECP. And so they work shoulder to shoulder with these teams to produce capabilities that the specific team can use. For example, new features in MPI to take advantage of multiple, multi-teraflop compute devices that the GPUs represent, and being able to harness the compute capacity of those devices and still do communication across multiple devices. That’s a very challenging problem. And so the MPI team—both MPICH and OpenMPI teams—are working closely with application developers to realize the performance potential of the platforms for those specific applications, but then knowing that those features that they’re developing will also be made available to many, many other application teams, both directly from MPICH and OpenMPI source spaces but also through the vendors as the vendors adopt and take on these products that we’re developing and make them part of the vendor stack.
Bernhardt: Mike, could you add on to that with just a little bit in terms of, what surprises have come up during the course of putting all of this together? What challenges were maybe unanticipated that you guys have had to deal with?
Heroux: A few things. We’ve had some changes as the project has proceeded in target architecture. And so that has been a bit of a challenge. Always wanting to get more information about the target platform as it becomes available, finding out the details, getting user experiences. We’ve addressed those challenges by having coordinated planning and access protocols for our development teams and individual members. We’ve had really first-of-a-kind interactions with the facilities as an aggregate within Software Technology. Individual project teams have been, in the past, able to get access to platforms. But to be able to do that in a coordinated fashion has been very powerful for us, to be able to get early access to the systems that represent the architectures of the exascale platforms. And so those are some of the things that have been a challenge—and opportunities—for us.
Bernhardt: Lois, what’s your perspective? You’re dealing with so many different products and so many different issues and all these scattered teams. Where have you experienced some of the toughest challenges that you’ve had to address?
McInnes: That’s a great question. I will say that we as a community, I believe, are doing a very effective job at learning how to adapt as the complexities of our simulations and analysis are growing. And one specific way that that’s happening is through a complementary project called the IDEAS project that is working throughout the whole ECP community. It’s housed under the Hardware and Integration area. Members of the IDEAS project are trying to work as catalysts within the community to help all of us better understand what kinds of actions we can take within our individual software teams to help improve our ability to work together in a coordinated way. The IDEAS project members are catalysts for engaging the rest of the community in understanding how to improve the productivity and the sustainability of the software technologies and the staff for developing that. We’ve tried to understand what some of the biggest challenges are from our community in terms of collaborating through multidimensional teams. We’re bringing together individual teams who traditionally have had very strong successes in working in their particular area, but now we’re bringing them together in aggregate teams, or so-called teams of teams, to address new multi-scale, multi-physics simulations as well as analysis using these technologies. We’re working as a community toward learning about more sophisticated practices in revision control, more effective documentation—as Mike mentioned, for our Software Technology documentation portal—and other areas.
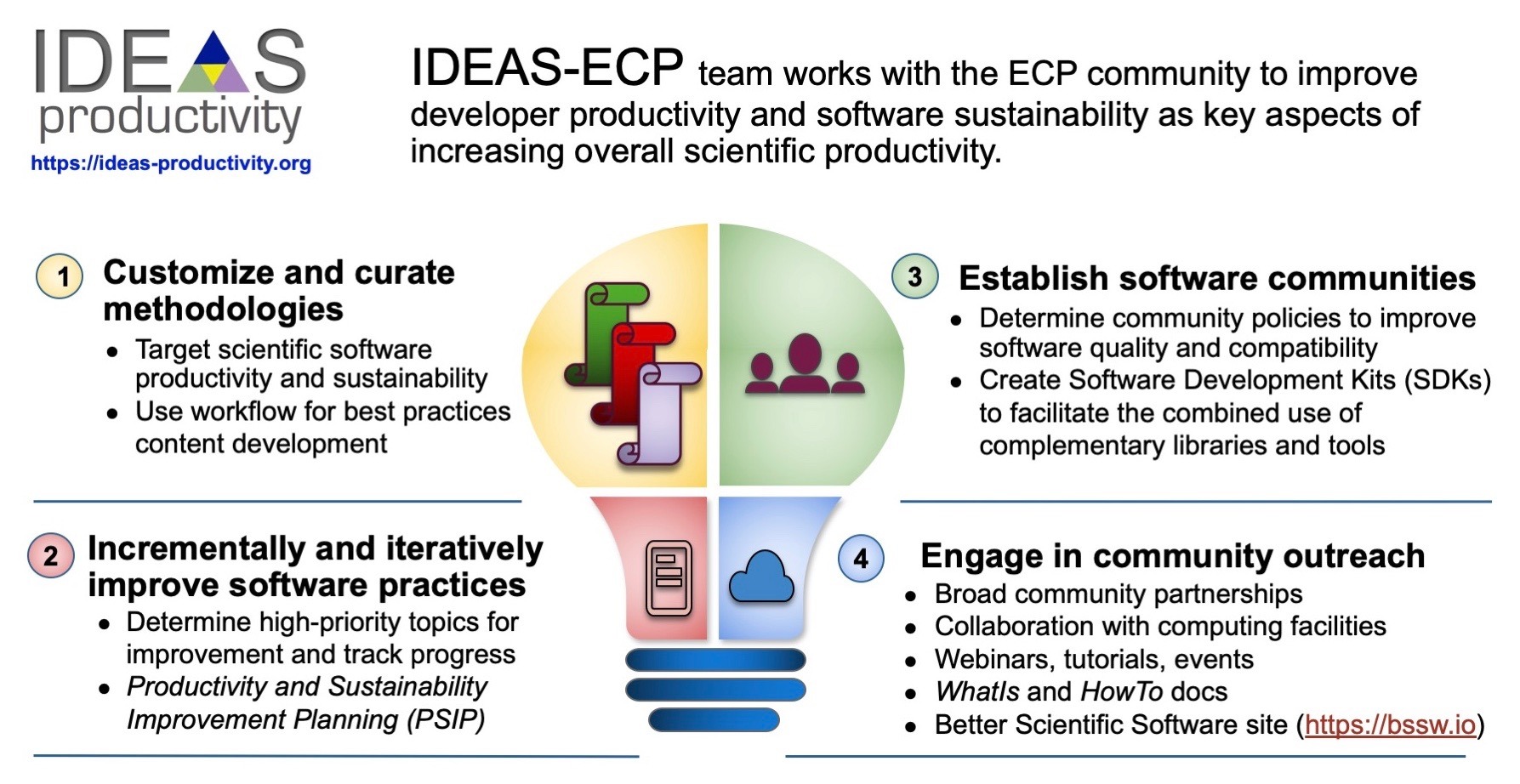

I’ll say that we’re also learning how to work more effectively as distributed teams, that the IDEAS project recently launched a new panel series—everyone’s welcome to attend—that is focusing on strategies for working remotely. This is building on our community’s already-deep experience on working in distributed ways. We’re naturally collaborating across institutions and across communities. And now we’re extending that, given the complexities of what we’re dealing with working in a more consistent remote environment but also yet continuing to expand our science.
Bernhardt: Wow, yeah. Things have really changed, haven’t they? And we’re just trying to keep up in some aspects of it. But looks like you guys are doing a phenomenal job, which leads me to, I think, a thought-provoking question. And I’ll just throw it out there and see who of you would like to respond to it. I’m curious. Where do you think the HPC software community is headed? What do today’s software developers need to do to be relevant a few years down the road?
Heroux: So I’ll take a stab at that. There are a couple of things. One is the Exascale Computing Project represents an effort to adapt to the fundamental changes in how high-performance computing occurs, in that we are moving to an execution model that is not just about doing distributed memory using MPI, the message passing interface. But also underneath each MPI process, there’s also a tremendous amount of concurrency. And so the execution model, how instructions get executed, is fundamentally changing, and ECP represents a huge investment dealing with these high levels of concurrency underneath each distributed memory process. And that’s really one of the value propositions that ECP is bringing forward and will continue past ECP as a need for the HPC community. And it gets even more complicated in that we anticipate not just six GPUs on each node as we have, say, with Summit today, that are all the same, but we’re going to have multiple devices of different types for different kinds of computational patterns. We’re going to have to learn to use those multiple devices on a node. So that’s the big challenge that we face. The technical challenge is dealing with that.
The other big challenge—and something that the software development community has to deal with—is, you write all this great software; how do you get it to your users? And that’s the integration piece, right? So we have to write good software using good algorithms that get the performance out of the platforms, but then you need to get that software to the users, and that’s what the Software Development Kits and the E4S is all about. Getting software out there so that people can find it, so you can deal with what some people call ‘the dependency hell,’ which is dealing with lots of different software products and the versioning of those, polishing that collection of software, and getting it out to the users along with the documentation, along with a quality expectation that our community policy is promoting. And so if you want to be a successful developer in the future, you’ve got to handle the execution model change to lots of concurrency and you have to get your software integrated into a body, a collection, a portfolio, that people will find and use.
Bernhardt: Excellent.
McInnes: I certainly agree with Mike’s comments and would echo that from my point of view, what I’ve seen is a change over the last twenty years in that now people are really more intentionally thinking about ecosystem perspectives. In the past, from my point of view, ecosystems have arisen naturally and organically, oftentimes based around the users of particular software technologies, but now, in addition to those organic, smaller ecosystems, we’re coming together in these broader ways to serve the next-generation needs of scientists. So that really emphasizes why it’s paramount to change our culture to acknowledge that software really is a fundamental means by which we collaborate. We, of course, collaborate also by talking with each other and writing papers about what we do. But software really is a way that we encapsulate the expertise of different teams who have different areas of work and then, together, we work to achieve next-generation science goals. So being very explicit about understanding that and rewarding the hard work that goes into designing good software, developing and testing good software and interacting with users, I think, is really exciting and a new area where we’re all heading toward in the future, so we can continue to have confidence in the software that we’re developing and in the investigations and new insights that come from it.
Bernhardt: Fantastic. Closing out on the topic of Software Technology, we’re in the fourth quarter of the government fiscal, we’re starting to look ahead at what we do over the next year. How would you summarize for the broader HPC community where you are in terms of software development in terms of the nation’s first exascale software stack?
Heroux: We’re getting access now to hardware that looks very similar to the exascale platforms—early, early access. And the software that sits on top of it, the vendor software. So we are engaging in the aspect of HPC, which makes it a bloody sport. We’re dealing with these early software and hardware combinations and getting our software to work on top of it and to perform well. So, that is where we are right now. We’re in a very good position to be prepared for the exascale systems. We have a lot of really good contributions to the software stack that we’re able to access. Our first results in terms of compiling and executing are very positive. These coming six months to a year, we’re doing real stuff on real software and real hardware.
McInnes: And I would say as a complement to that, we’re also communicating about our strategies and experiences for doing this. As I mentioned, the software technologies community is working with the IDEAS project and the rest of the ECP community on explicitly sharing our strategies and experiences, and one mode of outreach is a site called the Better Scientific Software site, where we encourage people throughout the international community—regardless of project and funding sources—to share their ideas, their experiences, and technologies that they find useful. I would invite people to consider contributing to that, take a look at resources, and share what has been effective for your work as well.

Bernhardt: Well, we’d like to thank Mike Heroux and Lois Curfman McInnes for this update on ECP Software Technology, part of a special Let’s Talk Exascale podcast. Our final segment brings us to the critical ECP area of Hardware and Integration.
Hardware and Integration
The Hardware and Integration function of the Exascale Computing Project has two primary areas of responsibility. First is the integration and deployment of applications and software at the DOE HPC facilities. Second is the development of key hardware innovations for exascale computing systems. But taking a deeper dive, a closer look at this, ECP’s Hardware and Integration focus area encompasses six strategic elements: hardware evaluation, application integration, software deployment at the facilities, an area we call facility resource utilization, the PathForward program, and, finally, training and productivity. Now, each of these elements requires very close collaboration with the DOE HPC facilities, the participating HPC vendors, and the ECP staff. Our next guest on the program is the director of the ECP’s Hardware and Integration team, Lawrence Berkeley National Laboratory’s Katie Antypas.
Thanks for joining us today, Katie.
Antypas: Yeah. Thanks, Mike. No problem.
Bernhardt: Hey, Katie, you’re coming up on—I think this is right—four months as the director of the Hardware and Integration focus area for the ECP. So as the newest member of the ECP leadership team, what surprises have you encountered or what challenges have you faced in taking on this new responsibility?
Antypas: Well, thanks. You know, you’re right, Mike, it’s a big and a complicated project. And one of the things that’s really helped me to onboard is that we have really incredibly talented team members, especially in the HI area. Our level-three leads for all of our technical areas are just completely on top of their areas, and I think it’s been a lot easier for me to get onboarded than I had expected. So that’s been really great.


Katie Antypas, Lawrence Berkeley National Laboratory, ECP Hardware and Integration director
One of the challenges is that ECP, by nature, is a really large and distributed project, and, certainly, in my past at Lawrence Berkeley National Lab, I’ve managed large projects before, and I’ve, of course, had external collaborators but never really managed a project at this scale and in such a distributed fashion. It makes things more challenging and necessarily so because ECP isn’t a project one institution can handle alone. But just getting used to sort of the day-to-day challenges of needing to schedule folks at all the different labs, and it can be hard to have those informal conversations where you run into a colleague in the hallway and say, hey, come into my office and let’s chat about this or that. You know, that takes a little more planning in the Exascale Computing Project, but, overall, I’ve been really impressed with the team, and I’m really excited to take the project to the next stage.
Bernhardt: Katie, I want to go back to something that you just mentioned, and that’s the complexity and the scope of this project overall. The Hardware and Integration focus area at ECP, the way I’d see it from the outside, it’s somewhat unique and it’s rather dynamic as your team works closely with all the DOE HPC facilities that are going to house the country’s forthcoming exascale platforms. When I look at the scope of this, the technical details; the logistics—including the facility updates, the delivery schedules; dealing with testing platforms and training programs; all the planning, the adjusting, and coordination in real time as changes take place, to say it’s quite a challenge is an understatement. And it’s an area that continues to evolve, so could you speak to the level of integration that’s required and tell us more about the HI group and how it interacts with the Application Development and Software Technology teams?
Antypas: Sure. You know, I think one of the reasons I was so excited to join this project at this particular stage was that—and I hope it’s not too presumptuous to say—it’s nearly all about integration. All the work that we have done thus far on the Exascale Computing Project has been preparing us for this stage, and this stage is where we’re starting to see early hardware that’s being shipped to the facilities. And our application teams and our software development teams, software technology teams, you know, they’re just starting now to get those products, those applications and software, onto these early test systems. And so it does—you’re right—take an extraordinary amount of coordination with the facilities. There’s what seemingly would be simple things. You’ve got to get people on. You’ve got to get them accounts. But that’s not simple when you have so many scientists and teams that are distributed around the country. And then you really have to train them up and teach them how to use these particular architectures, because these are first of a kind, right? These are architectures that aren’t out there right now. So these teams need to be trained and prepared, and that takes a lot of effort as well.
And then another area that I’m really excited about is Software Deployment. All the HPC systems I’ve worked on in the past, we’ve deployed software in kind of a very similar way, and I’ll be honest, I don’t think much has changed in the way that we deploy software on HPC architectures in the, let’s say, almost twenty years I’ve been working on HPC. And then with the Exascale Computing Project, we really have an opportunity to change the way that we deploy software, and so instead of deploying one package at a time with software modules, we’re talking about deploying a set of software as a package tested together, prepared for these architectures as a set. And I think that we have a real opportunity to change the way that we deploy software on these exascale platforms.
Bernhardt: Katie, that brings up a good point, the description of the areas under your management there as far as the Hardware and Integration function. Could you say a few words about each of the six strategic elements of HI? Just kind of give our listeners a snapshot of each of these areas?
Antypas: One thing that I probably should have known before I started this role, but the area is Hardware and Integration, right? It’s not hardware integration. And I think that is something that people might get a little confused about when they hear about this particular area that we call HI.
Let me start with the elements in this area, Hardware and Integration, that are actually about hardware, and then we have four other elements that are really more about integration and software.

The first area is called PathForward, and PathForward is a really strategic area that’s led by Bronis de Supinski from Lawrence Livermore National Laboratory. And the PathForward effort provides really critical early hardware for early vendor R&D for exascale technologies. The goal of the PathForward effort was really to prepare US industry for exascale system procurements and to assure that the US market was really competitive. And I think that we can see from the offerings that we’ve seen for the two exascale systems, that PathForward really has had an influence. It’s been successful in influencing the vendor markets to focus on some of the specific DOE use cases and workloads. So that is one element.
The next element I think we can talk about is Hardware Evaluation, and Hardware Evaluation is led by Scott Pakin from Los Alamos National Laboratory. This particular element supports laboratory staff in providing really independent analysis of some of the PathForward deliverables. They focus on using kind of a variety of analysis tools and approaches to evaluate these different technologies and collaborate with vendors.
Now, these two elements I just spoke about, PathForward and Hardware Evaluation, are actually ramping down in 2021. They’re coming to an end, and naturally so. PathForward was about influencing vendors for procurements, and Hardware Evaluation was looking at evaluating that hardware. So now that we know the exascale architectures, those systems have been procured, and we have contracts signed for them, these elements are naturally coming to an end and ramping down in the project as other areas are ramping up.
So one of the areas that is really picking up right now is called Application Integration, and this is led by Judy Hill from Oak Ridge National Laboratory. Application Integration really ensures that the ECP application teams really can take advantage of the exascale architectures that the facilities are deploying. The Application Integration staff are embedded with the facilities teams, and each of the facilities—whether it’s the OLCF, ALCF, or NERSC—has a set of experts that help prepare application teams for new systems that they bring onboard to their facility. And so you can think the Application Development area is developing new science capabilities and algorithms, and then the Application Integration staff are really helping to target these applications and optimize them for these exascale architectures.
Software Deployment at the Facilities is the next element I’d like to talk about, and this is led by Ryan Adamson from Oak Ridge National Laboratory. As I mentioned earlier, this is, I think, a really exciting area of the Exascale Computing Project. And so what Ryan’s team is responsible for is the deployment of the ECP software to the facilities and making sure that the software is also tested in an automated and structured way. And, again, this is something that’s very different than how we have deployed software on HPC systems in the past, and so I think this area has a real opportunity to have an impact and change the way we deploy managed software on these systems.
The next area I’d like to talk about is called Facility Resource Utilization, and this is led by Haritha Siddabathuni Som from Argonne National Laboratory. And, you know, it’s a smaller element within Hardware and Integration but really important. And the purpose of the facility resource utilization area is to have a mechanism to be able to allocate time, allocate computing resources, on the current production pre-exascale systems. So the application teams and the software teams, they need to be testing their software and their applications, and Facility Resource Utilization is the mechanism we use to collaborate with the facilities and provide these allocations.
And the last element that I’d like to talk about is Training and Productivity, and this is led by Ashley Barker from Oak Ridge National Laboratory, and is a really extremely, extremely important area in ECP. I think I mentioned it a little bit earlier, but there are so many scientists and software developers that are participating in ECP that it’s really a massive effort to train all the staff, to train all of the scientists on how to take full advantage of the exascale hardware and software. And so, ECP has a really robust training program, and it’s going to become even more important as these new early-access systems and test systems are deployed.
Bernhardt: Wow, so Katie, thanks for that overview. You know, when you combine the many functions and responsibilities of the Hardware and Integration focus area of ECP along with everything that’s happening with applications and software and look back on the history of the HPC community, and it was quite common for many years—as you started to point out there—HPC systems have often come to market and they’ve had very little ecosystem. And there might have been a few applications that had been somewhat tested. Software was kind of shaky in many cases. This is a monumental effort. To use a phrase that was made popular and attributed to JFK, “A rising tide lifts all boats.” We’re bringing everything that we need for that ecosystem, raising the tide for all these items at one time to be able to deliver this entire ecosystem for exascale. So, Hardware and Integration really comes into play at this point in time in the lifecycle of this project, so thank you for that update.
Katie, you served for a few years as the project director of the NERSC-9 Perlmutter system that will be deployed at NERSC later this calendar year, right? So what role do you see the pre-exascale NERSC Perlmutter system playing in the ECP project?
Antypas: Yeah, thanks, Mike. I served as the NERSC-9 Perlmutter project director for a couple of years, and now the project is led by Jay Srinivasan, who’s also leading our Shasta testing efforts in the ECP now. I think Perlmutter has a really important role to play in the Exascale Computing Project because the Perlmutter system will be deployed later this year at the end of calendar year 2020. And it’s going to include a number of technologies that will also be in the later exascale systems. One in particular is the Shasta software stack. And so, if we’re able to demonstrate the Shasta software stack at scale and debug it and harden it on Perlmutter before the two exascale systems come in, I think that will be a real service to the community and really an opportunity to test the deployment of ECP software in a production environment. In addition, we are going to be able to test our software deployment area on the Perlmutter system before the pre-exascale systems as well. So how does that automated testing work? How do the end users use that software? What kind of new tests need to be integrated? So, I think Perlmutter will be a great platform for that as well.
Bernhardt: Awesome. Thank you. Katie, to kind of wrap up our little discussion here, what are your goals for the HI function, for Hardware and Integration looking out over this calendar year and maybe into 2021?
Antypas: You know, I think our key goals in Hardware and Integration are really driven by the early hardware coming online. And so, our goals are really attached to those deployments, so we want to get the scientists and application developers onto those early-access systems so they can get experience and exposure on them. Our training programs will start targeting these new architectures specifically. We’re going to be testing the deployment of software onto these early-access system and test systems. And so, you know, I think 2020 and 2021 are really exciting years because this is the time where the early hardware is coming on the floor. We’ve had a few deployments recently, and we’re going to have the opportunity to really get ready for those huge exascale systems that are coming online.
Bernhardt: All right. We’ve been talking with Lawrence Berkeley National Laboratory’s Katy Antypas, director of the Hardware and Integration effort for the US Department of Energy’s Exascale Computing Project. That does it for this special update. We hope you enjoyed this program, and we invite you to reach out to us and follow our activities at exascale project.org. For the Exascale Computing Project, I’m Mike Bernhardt.