By Rob Farber, contributing writer
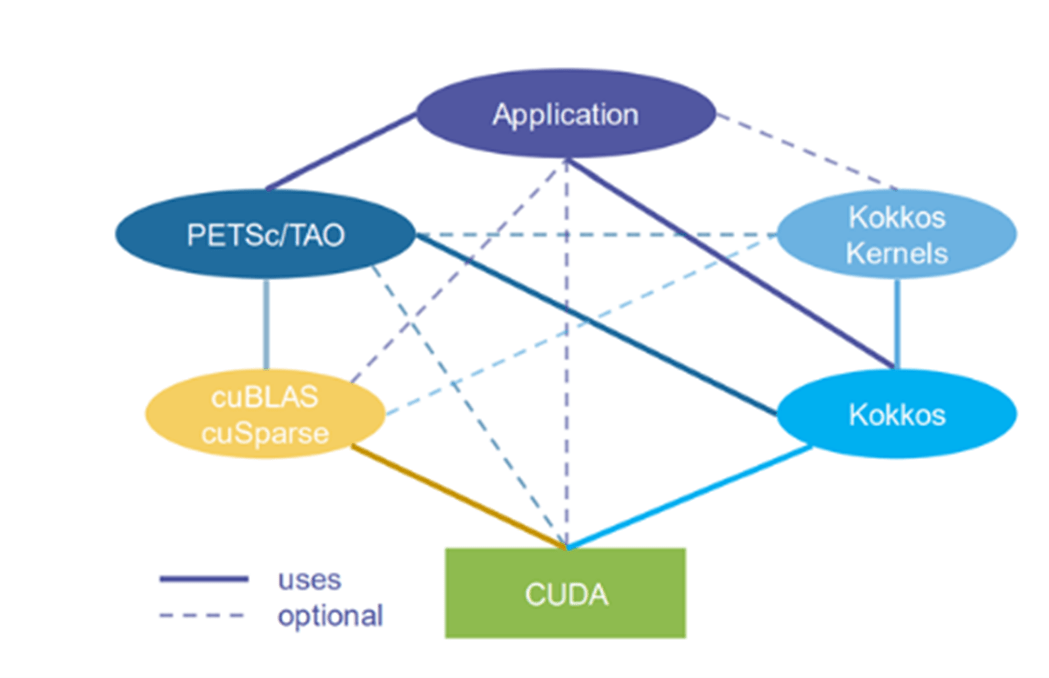
The Portable, Extensible Toolkit for Scientific Computation (PETSc) reflects a long-term investment in software infrastructure for the scientific community. As Mark Adams et al. observe in their paper, “The PETSc Community is the Infrastructure,” “The human infrastructure—people and their interactions as a community, within the broader DOE, HPC [high-performance computing], and computational science communities—is foundational and enables the creation of sustainable software infrastructure.” PETSc provides scalable solvers for nonlinear time-dependent differential and algebraic equations and for numerical optimization. PETSc is also referred to as PETSc/TAO (Figure 1) because it contains the Toolkit for Advanced Optimization (TAO) software library.
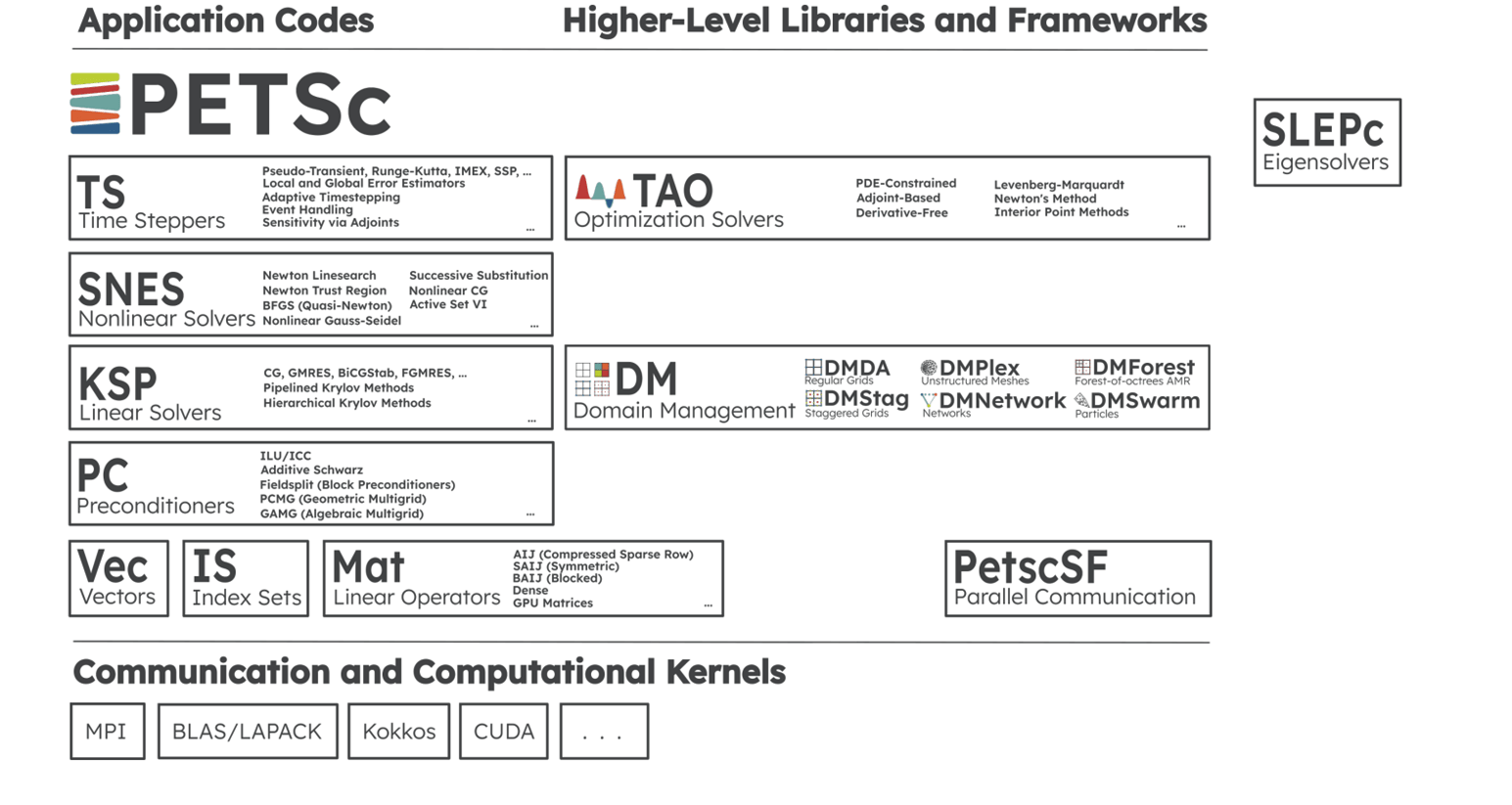
Figure 1. The PETSc/TAO Toolkit for scientific computation.
Lessons from a Successful, Decades-Long Community Effort
The PETSc/TAO project reflects a decades-long success story in how to create, maintain, and modernize an essential capability of scientific software.
The PETSc project began in the 1990s as an early software project of Argonne National Laboratory (Argonne) for parallel numerical algorithms. The creation of academic-grade software through an exploratory project reflects a common beginning for many HPC projects. Unfortunately, success frequently locks many HPC projects into code and design decisions that become increasingly unsustainable over time.
The current production-quality version of PETSc/TAO illustrates a time-proven use case in connecting users and developers (Figure 2), who together have added capabilities and adapted the software to the unforeseen and radical system architectures installed in data centers during the ensuing decades. The advent of GPU accelerators is the most recent example. When interviewed for this article, Richard Mills (Figure 4), a computational scientist at Argonne, noted that he found the usefulness of the toolkit so compelling that he joined the PETSc team.
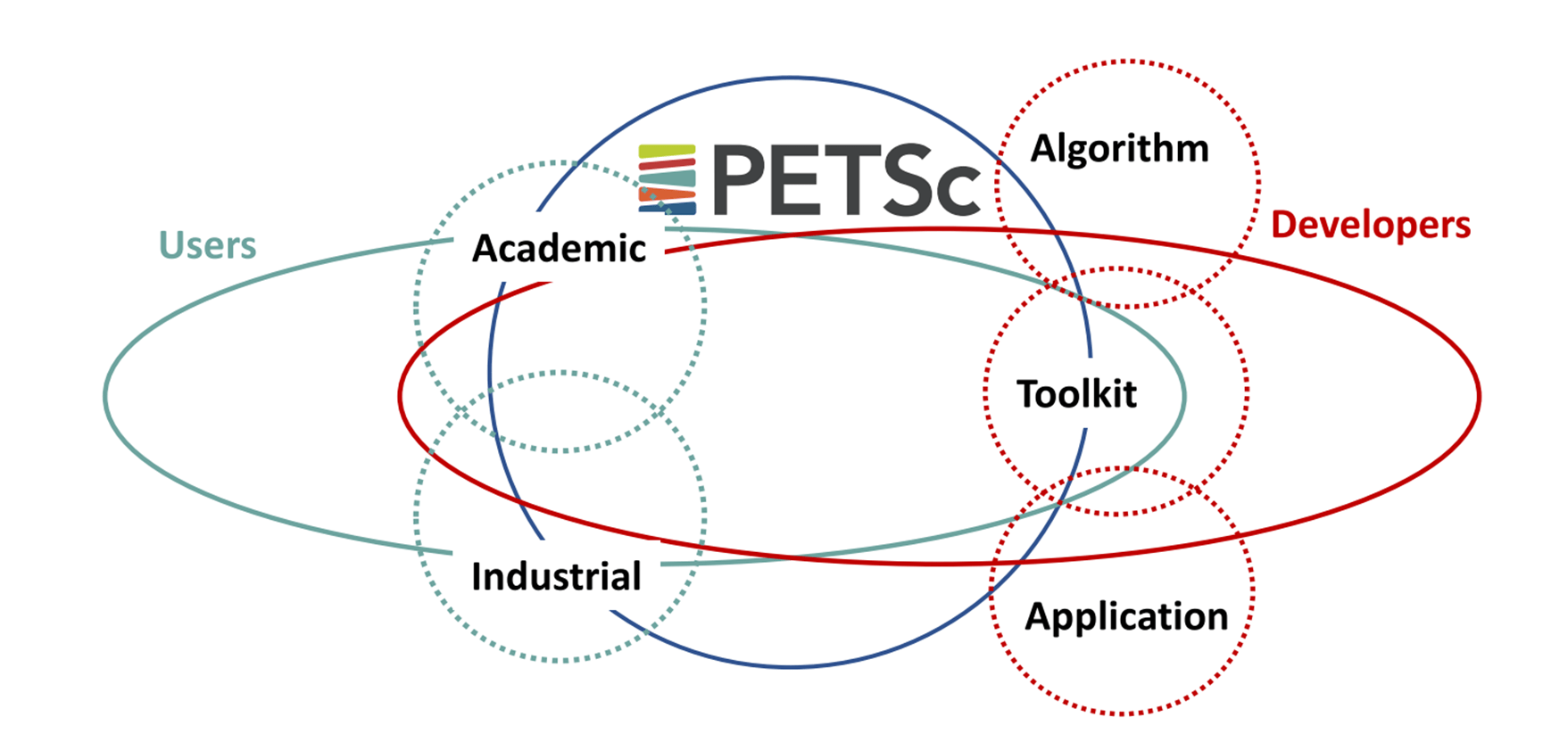
Figure 2. PETSc connects users and developers.
The PETSc/TAO success story of long-term sustainability through community fits perfectly into the Exascale Computing Project (ECP) mission to transform the current HPC ecosystem into “a software stack that is both exascale-capable and usable on US industrial- and academic-scale systems.”[1] With ECP funding and through collaborations within the ECP, the PETSc/TAO team has been preparing the toolkit to run on the forthcoming GPU-accelerated exascale systems. Both the ECP and PETSc/TAO efforts recognize that “to ensure the full potential of these new and diverse architectures, as well as the longevity and sustainability of science applications, we need to embrace software ecosystems as first-class citizens.”[2]
The benefit of first-class citizenship includes funding, but that tells only part of the story because community support for these ecosystems is also essential to their survival. Otherwise, “those without a community die out, have only a fringe usership, or are maintained (as orphan software) by other communities.”[3] Such sustainable, long-term, community-based thinking permeates the ECP as a myriad of software technology and application development efforts and strategies. These ECP efforts are tackling challenges in how research software is developed, sustained, and stewarded. The impacts are far-reaching, as exemplified by the National Nuclear Security Administration–funded Advanced Technology Development and Mitigation programs within the ECP. These programs focus on the long-term viability of essential, community-based, open-source software infrastructure that can support the latest generation of HPC architectures. The ability to rely on such up-to-date performance software ecosystems contributes to the success of national security programs and contributes to projects within the global scientific and HPC communities.[4],[5],[6]
The PETSc/TAO effort has successfully navigated the HPC landscape to earn both funding and extensive community support. This success makes it a good use case in how to incorporate good software practices and is worthy of study for any software effort.
Good software practices result in robust, portable, and high-performance code. It is not a burden but rather a benefit. Incorporating good software practices does not distract from the science but rather enables it. Meanwhile, even the smallest community open-source projects cannot exist as entities unto themselves. Mark Adams et al. highlight this principle: “Members of the PETSc community are actively engaged with program development, including communicating with program managers at the [DOE], the National Science Foundation, and with institutional management to ensure that support is provided and maintained. This form of interaction is crucial to the long-term viability of all open-source software communities; PETSc users and community members have played important roles in various local, national, and international conversations, including recent DOE activities related to software sustainability.”[7]
Successful Applications Tell the PETSc/TAO Success Story
An essential numerical toolkit for many applications, PETSc/TAO provides the workhorse numerical methods required to find solutions to the complex systems of equations that scientists use to model a system of interest.
These applications tell the success story of the toolkit by demonstrating the wide-spread adoption, usability, accuracy, portability, and performance of the PETSc/TAO solvers in a supercomputer environment. At the Oak Ridge Leadership Computing Facility (OLCF) at Oak Ridge National Laboratory (ORNL), performance and portability are, of course, also reflected in microbenchmarks and reports such as the “.” The 40-petaflops Crusher supercomputer has identical hardware and similar software to the OLCF’s Frontier exascale system. For this reason, preliminary results on Crusher are valid indicators of performance on Frontier. Part I does not reference Crusher, so only Part II of the report is referenced here.
Within the ECP, the PETSc/TAO team has been working with applications such as Chombo-Crunch, which addresses carbon sequestration, and with the Whole Device Model Application (WDMApp) for fusion reactors. WDMApp is developing a high-fidelity planning and optimization tool to help understand and control plasmas in tokamak fusion devices.[8]
The societal and scientific importance of these projects is very real.
The DOE, for example, identified whole-device modeling (WDM) as a priority for “assessments of reactor performance in order to minimize risk and qualify operating scenarios for next-step burning plasma experiments.”[9] The fusion energy project of the International Thermonuclear Experimental Reactor (ITER) is one high-profile example that is pressing the limits of human knowledge because it will utilize plasmas well beyond the physics regimes accessible in any previous fusion experiments. Understanding how plasmas behave in these new physics regimes requires both adapting existing computer models and using exascale supercomputers. PETSc/TAO meets both requirements.
In a win-win for the ECP, PETSc, and WDMApp projects, WDMApp became the first simulation software in fusion history to couple tokamak core to edge physics.
The Software Approach That Makes PETSc/TAO Work So Well
The callback design and use of a star-forest communications topology lie at the heart of the toolkit’s ability to run efficiently on so many generations of high-performance, distributed supercomputer architectures.
The Callback Design
According to the paper “Toward Performance-Portable PETSc for GPU-based Exascale Systems,” PETSc is designed to separate the application code and the model used by PETSc for its back-end computational kernels (Figure 3). This separation of concerns—which is a powerful design principle for computer science—allows PETSc users who program in C, C++, Fortran, or Python to employ their preferred GPU programming model (e.g., Kokkos, RAJA, SYCL, the Heterogeneous-Computing Interface for Portability [HIP], the Compute Unified Device Architecture [CUDA], or the Open Computing Language). Everything works so long as the programmer adheres to the so-called contract that is implicit in the abstraction and codified in the documentation.

Figure 3. PETSc application developers can use a variety of programming models for GPUs independently of PETSc’s internal programming.
At a high level, Mills explains how this process works: “On the front end, users write the function with whatever data structure is needed by the GPU or CPU code. So long as the user conforms to the callback interface and communicates via the appropriate matrices, the code will work with PETSc. If any distributed computing is required, then use PetscSF. On the backend, the users need to choose solvers that work for the numerics of the problem and the destination CPU or GPU device(s). For example, if the code spends most of the runtime in PETSc, use a solver that runs on the GPU.”
Todd Munson (Figure 4), a senior computational scientist at Argonne and PI of PETSc, adds, “The main burden for the developer is that they must provide the residual evaluation function and code.” For performance optimization, Mills notes, “PETSc is not a black box. Think of it as a semitransparent box in which the user can make adjustments to improve performance. For simplicity, novices can start by using PETSc as a black box and then look in the box to optimize performance later.”
To enable increased performance on GPUs, Mills notes that the team has developed a new API in 2021 that enables on-device assembly of matrices without requiring locks or other operations that do not perform well on GPUs.
Tobin Isaac (Figure 4), a computational mathematician at Argonne, explains further, “Hard problems don’t always fall into neat boxes. PETSc’s abstractions for the different subproblems are designed to compose together so that users and developers can more easily build good solutions by using root-finding, optimization, and time-stepping methods.”
The “Toward Performance-Portable PETSc for GPU-based Exascale Systems” paper provides a porting blueprint for application programmers who wish to use GPUs.[10] The authors highlight the performance and generality of their approach: “Applications will be able to mix and match programming models, allowing, for example, some application code in Kokkos and some in CUDA. The flexible PETSc back-end support is accomplished by sharing data between the application and PETSc programming models but not sharing the programming models’ internal data structures. Because the data are shared, there are no copies between the programming models and no loss of efficiency.”
 |
 |
 |
|
Figure 4. (Top left) Todd Munson, (top right) Richard Mills, and (bottom center) Tobin Isaac.
The PetscSF Scalable Communications Layer
PetscSF is the communication component of PETSc. It provides a simple API for managing both structured and irregular communication graphs based on a star-forest graph representation. Stars are simple trees consisting of one root vertex connected to zero or more leaves. The number of leaves is called the degree of the root. PetscSF also allows leaves without connected roots, which represent holes in the user’s data structure and do not participate in the communication. Many common communication patterns can be expressed as updates of root data by using leaf data and vice versa, hence the generality of this representation.[11] An example star forest distributed across 3 message-passing interface (MPI) ranks is shown below (Figure 5).
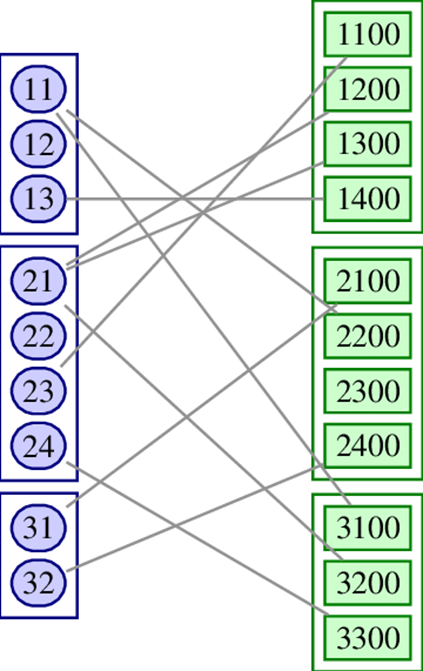
Figure 5. Distributed star forest with associated data partitioned across three processes and with specification arrays (right). Source: https://www.researchgate.net/publication/354516510_Toward_performance-portable_PETSc_for_GPU-based_exascale_systems.
Not all communications in modern systems are MPI-based. For example, many low-latency mechanisms communicate between the GPUs and the system CPU. The 2021 paper, “The PetscSF Scalable Communication Layer,” notes, “The [MPI], which has been the de facto standard for distributed memory systems, has developed into a large complex API that does not yet provide high performance on the emerging heterogeneous CPU-GPU-based exascale systems.” For this reason, “PetscSF is incrementally replacing all direct use of MPI in PETSc.”[12]
The MPI calls are being replaced with a new abstraction interface created in 2021. The abstraction interface illustrates a powerful programming pattern that developers can use to provide the flexibility needed to adapt core internal software activities, such as communications, to unanticipated new hardware capabilities. PetscSF uses this flexibility to utilize new GPU communications capabilities and to track data types for efficiency reasons:
- Address new hardware capabilities: A key motivator for an abstraction layer is noted in “The PetscSF Scalable Communication Layer” paper, “Unfortunately, at the time of writing, even GPU-aware MPI implementations cannot pipeline MPI calls and kernel launches because the MPI API does not utilize the stream queue.” The new PetscSF abstraction removes this performance bottleneck by allowing the use of GPU-vendor–provided communications collectives.One example is NVIDIA’s NVSHMEM, which the PetscSF abstraction layer can call when appropriate. Shared memory provides a low-latency, high-bandwidth mechanism for transferring data between the CPU and GPU memory subsystems. The use of shared memory can also eliminate expensive memory copies. Furthermore, PetscSF can use low-overhead synchronization (sync) operations and allow GPU-initiated data transfers, pipelining data transfers, and GPU kernel launches. This enables programmers to optimize GPU performance by overlapping data transfers and computations. Pipelining also hides the latency of a GPU kernel launch. “PETSc will use the simultaneous kernel launch capability of NVSHMEM to begin its parallel solvers,” the paper’s authors state, “thus making them more tightly integrated and remaining in step during the solve process.”
- Track Data Types: The paper’s authors also observe that the root and leaf indices of the star forest are typically not contiguous per rank, so the library must pack and unpack the data for send or receive operations. If the data is in GPU memory, these pack or unpack routines must be implemented in GPU kernels.To reduce or eliminate this performance bottleneck, PetscSF now keeps track of the memory types that are passed to PetscSF for communications because it was determined that inferring the datatypes slowed down the pack/unpack operations. According to the paper, “[a]t least two benefits accrue: (1) we can directly scatter source data to its destination without intermediate send or receive buffers for local communication, and (2) local communication is done by a GPU kernel (doing a memory copy with index indirection). The kernel can be perfectly executed asynchronously with remote MPI communication, overlapping local and remote communications.”[13]
PETSc is Ready to Run on Exascale Supercomputers
Parallel scalability has been a key design goal of PETSc since its inception. For much of PETSc’s history (the first release was in 1995), MPI was the primary tool in achieving good inter-node scaling. This has changed with the introduction of many-core processors and GPU accelerators and created a need for high intra-node and inter-node communications.
Support for GPU-Aware and GPU-Centric Communication in PetscSF
Vendor libraries such as NVIDIA NVSHMEM provide one route to achieving high intra-node communications performance beyond what is currently achievable with MPI. The OpenSHMEM library was extended by Potluri et al. to multinode GPU systems to address strong-scaling limitations on multinode GPU clusters.[14] NVSHMEM is NVIDIA’s implementation of the OpenSHMEM specification for CUDA devices. PetscSF supports several implementations based on MPI and NVSHMEM, whose selection is based on the characteristics of the application or the target architecture.
NVSHMEM uses the symmetric data-object concept, a powerful design pattern for fast communications that eliminates using the CPU as an intermediary. In NVSHMEM, a process is called a processing element (PE), which is analogous to an MPI rank. This similarity allows reuse of much of the PETSc code without change. With NVSHMEM, communication can be initiated either on the host or on the device.
The primary goal of NVSHMEM is to enable CUDA threads to initiate inter-process data movement from the GPU.[15] At NVSHMEM initialization, all PEs allocate a block of shared CUDA memory of identical size in what is referred to as a symmetric heap. This consistent sizing simplifies indexing as data can be remotely accessed by using the address of the symmetric object and the rank of the PE. Meanwhile the shared CPU/GPU memory blocks provide a high-bandwidth, low-latency media for communications and the opportunity to eliminate synchronization operations.
The New PetscSF Communications Abstraction
In 2021 the PetscSF team abstracted a new communications API that moves beyond the limitations of MPI to allow both pipelining and GPU-initiated communications. Given the ubiquity of MPI in the HPC community, the PetscSF API reflects a use case worthy of study in how to use GPU-centric communications capabilities.
The ability to pipeline communications operations so they overlap with device computations is a key advancement in PetscSF. Current MPI implementation requires that the GPU queue must be empty before an MPI communication operation can start. This requires a sync operation (Figure 6 [R]) that stalls the computation. A pipelined operation (Figure 6 [L]) allows the computation and communication operations to overlap, thereby resulting in a faster execution time.
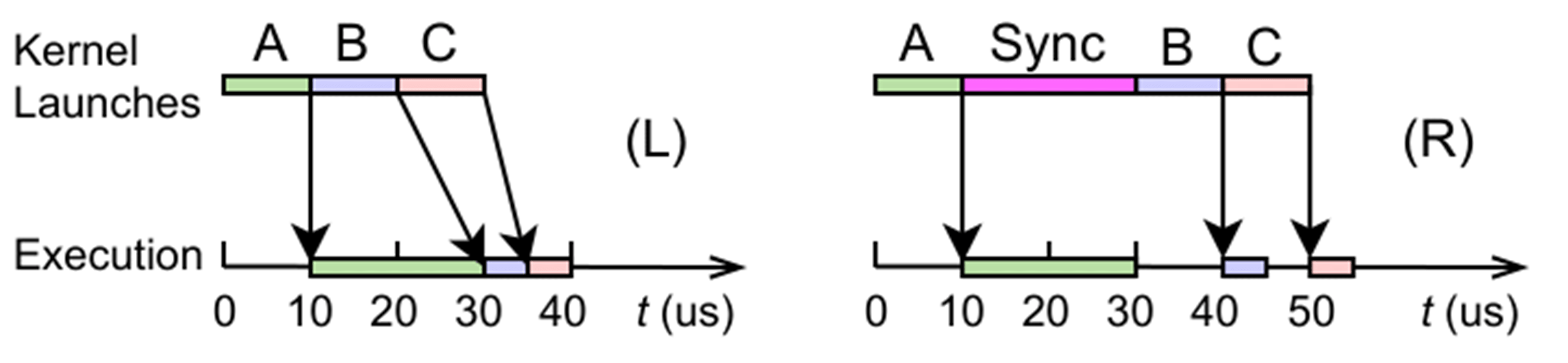
Figure 6. (L) Pipelined kernel launches vs. (R) interrupted kernel launches. Suppose a kernel launch takes 10 µs, and to run, kernel A takes 20 µs, kernel B takes 5 µs, and kernel C takes 5 µs. (L) shows a timeline with fully pipelined kernel launches. (R) shows a timeline with a device sync after kernel A. MPI communication forces syncs, such as in (R); NVSHMEM does not force syncs and allows a timeline, such as in (L).
Verifying Exascale Performance Capability in PetscSF
In preparation for production runs on the forthcoming US exascale systems, the PETSC team has been performing numerical experiments with NVIDIA, AMD, and Intel GPUs. The target platforms are shown below (Figure 7). However, the results were obtained on the 40-petaflops Crusher testbed rather than on Frontier because Frontier is undergoing acceptance testing. The Crusher testbed is used as an early-access testbed for the Center for Accelerated Application Readiness, the ECP, and the NCCS staff and vendor partners.[16],[17] It has identical hardware and similar software to Frontier.

Figure 7. Platforms for numerical experiments. Crusher results are reported as surrogates for Frontier, which is currently undergoing acceptance testing.
As discussed next, results on Crusher reflect the success of the PETSc development efforts and portend high performance once Frontier becomes available for production runs.
Testing Communications Latency
To evaluate the efficacy of the PetscSF communication layer against raw MPI performance, the team wrote their own benchmark to mimic the highly regarded OSU ping-pong latency test.
To perform the ping-pong test, PetscSF sends a message to a receiver and waits for the reply. More specifically, PetscSFBcast sends a message from between two MPI ranks (rank 0 to rank 1), and a following PetscSFReduce bounces a message back. The messages are sent repeatedly for a variety of data sizes to report the average one-way latency.
To test the efficacy of overlapped communications, two synthetic kernels were incorporated that can mimic compute-bound or memory-bound behavior. The compute-bound kernel repeatedly performed a multiplication in place. The memory-bound kernel repeatedly called PETSc’s VecAXPY(x,alpha,y), which computes y += alpha∗x with two vectors x and y. The results (Figure 8) show that the PetscSF overlapped communications performed well. For the complete analysis, consult the Argonne technical report, “Evaluation of PETSc on a Heterogeneous Architecture, the OLCF Crusher System: Part II – Basic Communication Performance.”
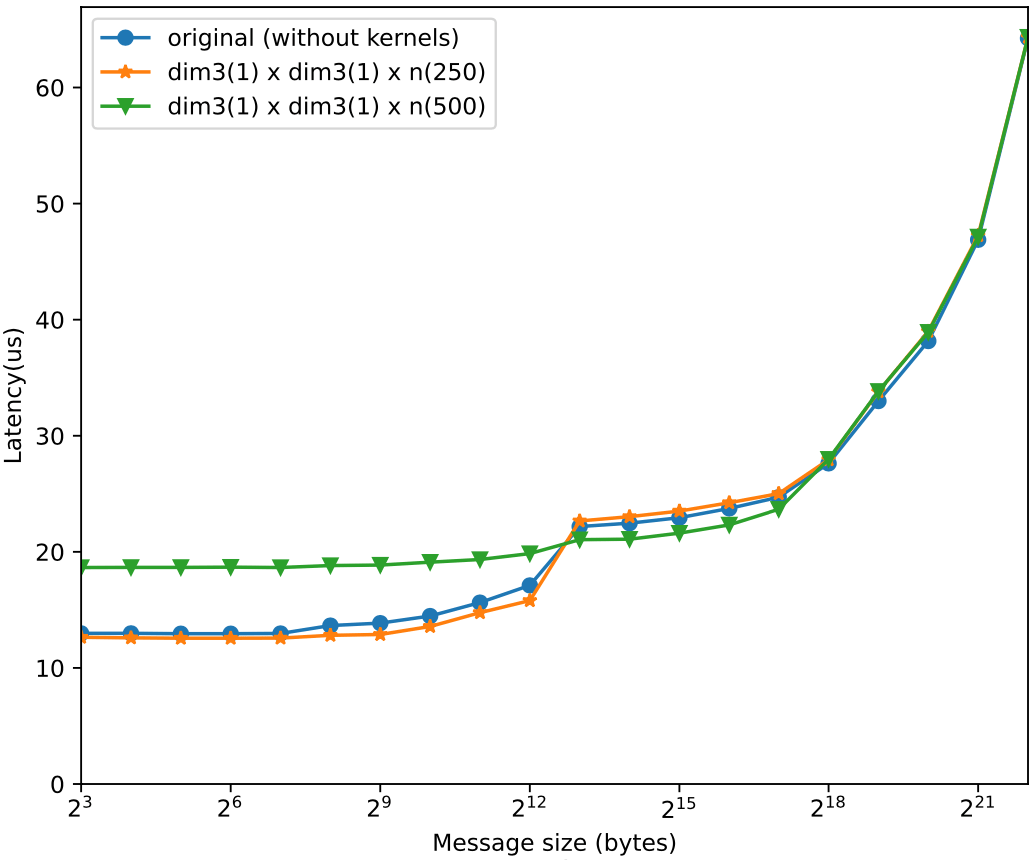 (a) PetscSF ping-pong + doComputeBoundWork() (a) PetscSF ping-pong + doComputeBoundWork() |
 (b) PetscSF ping-pong + VecAXPY() (b) PetscSF ping-pong + VecAXPY() |
Figure 8. Overlap communication with either (a) compute-bound work or (b) memory-bound work on the GPU. Blue lines show the ping-pong latency without overlapped kernels. Other lines show the latency by overlapping the communication with a kernel. From the almost overlapped orange lines, we can see up to a point, inserting a kernel (either compute-bound or memory-bound) does not affect the latency.
Overlapped Communications in a Conjugate Gradient Solver
The team also verified the benefits of the PetscSF overlapped communications in a PETSc conjugate gradient (CG) solver by using the NVIDIA Nsight profiler on a Summit computational node. Figure 9 shows that the CUDA-aware MPI (top) frequently stalled the computational kernel. PetscSF that used NVSHMEM (bottom) fully pipelined the computational kernels and resulted in better utilization and faster execution.
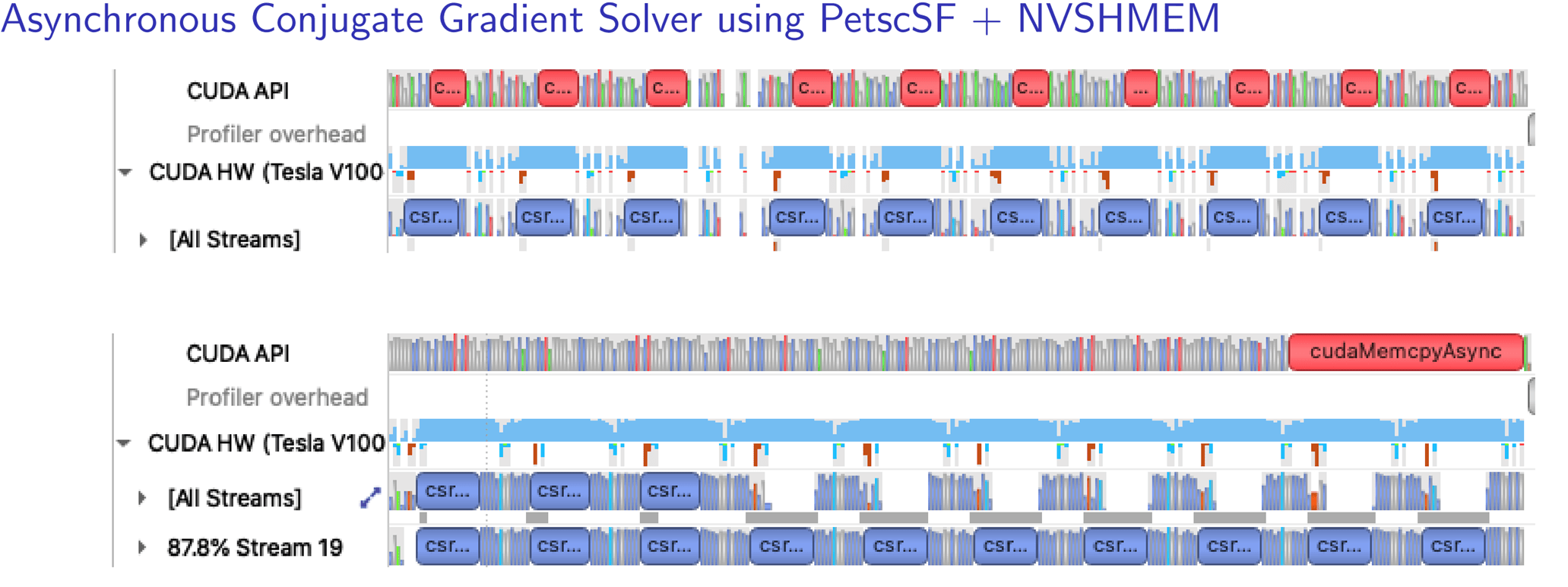
Figure 9. (Top) Timeline of CG with PetscSF + CUDA-aware MPI and (bottom) CGAsync with PetscSF + NVSHMEM on rank 2 of a test run with 6 MPI ranks (GPUs) on a Summit compute node. Each ran 10 iterations. Blue csr… bars are csrMV (i.e., SpMV) kernels in cuSPARSE, and the red c… bars are cudaMemcpyAsync() that copies data from device to host.
Crusher Performance on an End-to-End Additive Manufacturing Benchmark
The following benchmark from the paper “Performance-Portable Solid Mechanics via Matrix-Free -Multigrid” reports the efficiency of an end-to-end nonlinear solve, such as preconditioning, of an extruded Schwarz primitive surface under load. The Schwarz primitive surface exhibits interesting geometric and material nonlinearities that are of interest for additive manufacturing (AM).
Additive manufacturing (a.k.a. 3D printing) creates an object by building it one layer at a time. It is considered a revolution in manufacturing and a way to address the resiliency and competitiveness in US supply chains. The ECP ExaAM project, for example, is preparing to use exascale simulations to enable the design of AM components with location-specific properties and to accelerate performance certification of printed parts.
In this benchmark, the left wall (Figure 10) was fixed while a compressive force was applied to the opposite-facing surfaces on the right. A force induced a 12% strain. This value was chosen because it was slightly below the force at which plastic yielding occurs for photopolymer additively manufactured products of these models. The yield strength is often used to determine the maximum allowable load (e.g., strength) in a mechanical component because it represents the limit to forces that can be applied without producing permanent deformation.[18]

Figure 10. Example benchmark of an extruded Schwartz primitive surface under strain and just prior to deformation (e.g., plastic yielding).
Nonlinear Solve
The benchmark study swept through a range of primitive models up to 203 per Crusher node (184 multiple degrees of freedom [MDoF]) and performed a nonlinear solve. The yellow lines in Figure 11 report the observed efficiency per newton iteration of the solver and show that the Crusher testbed delivered the highest efficiency of the systems tested.[19]
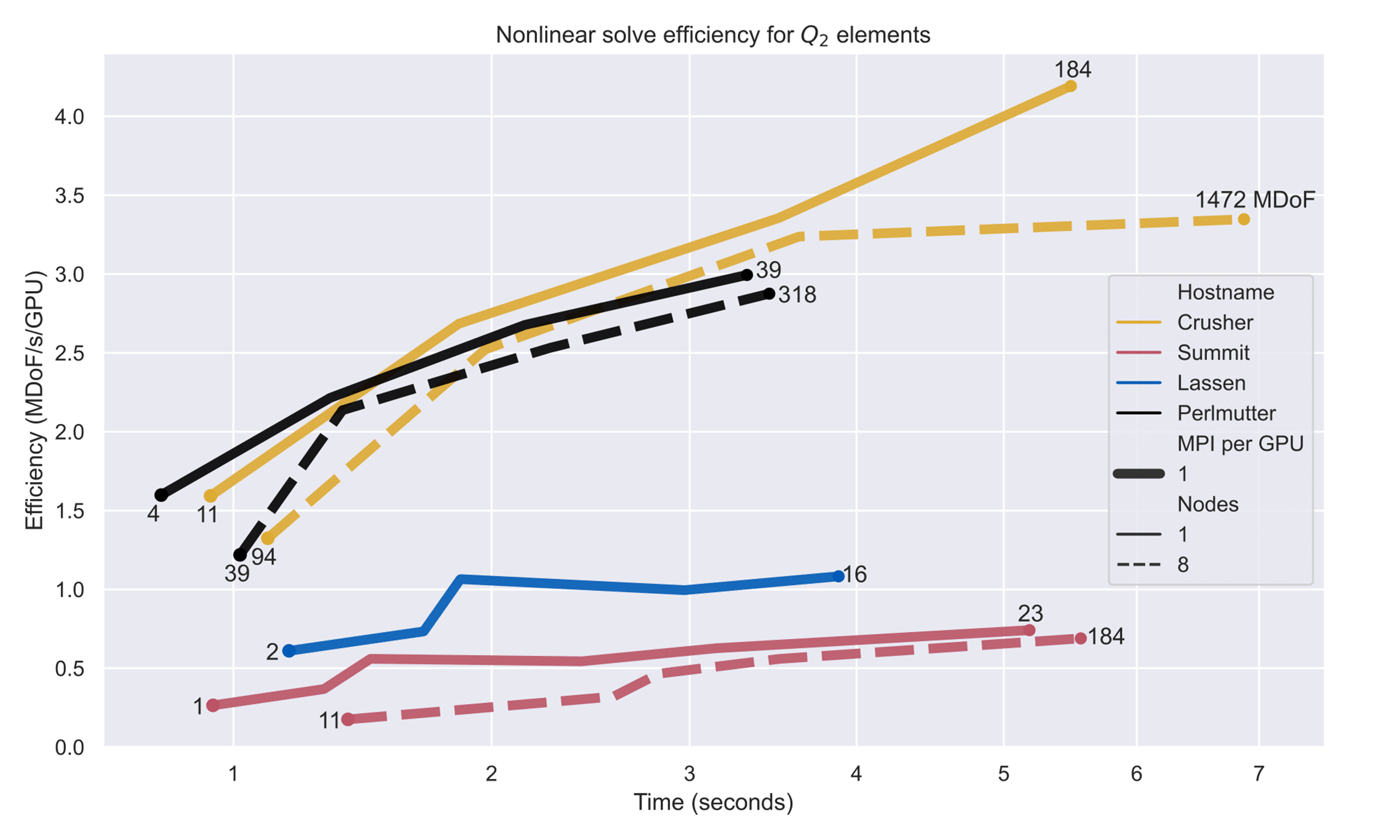
Figure 11. Efficiency per newton iteration vs. time for Q2 finite elements. The test used matrix-free Newton–Krylov methods with p-MG preconditioning and BoomerAMG coarse solve. Problem sizes (in MDoF) are annotated for the minimum and maximum sizes for each host and number of nodes combination. The impact of latency was ever-present and memory capacity limited the right end of each curve.
As shown in Figure 11, the black lines reflect weak scaling. Perfect weak scaling would have the 1-node and 8-node curves on top of each other and have strong-scaling limits visible in the minimum time at which acceptable efficiency can be achieved. These black lines are, as the paper authors note, a humancentric figure meant to assist the analyst with cloud or HPC access in choosing an efficiency-versus-time trade-off.
Preconditioner Setup
Figure 12 reports the preconditioner setup efficiency. Again, the Crusher testbed delivered the highest efficiency of the systems tested. This non-trivial benchmark consisted of algebraic multigrid analysis, Galerkin products, and Krylov iterations to calibrate the smoothers.

Figure 12. Preconditioner setup efficiency spectrum for using matrix-free Newton-Krylov with p-MG preconditioning and BoomerAMG coarse solve. The times and efficiencies are per newton iteration. Problem sizes (in MDoF) are annotated for the minimum and maximum sizes for each host and number of nodes combination.
User and Developer Interactions Have Created a Very Useable Toolkit
The PETSc community effort previously discussed has delivered many benefits, such as a very usable toolkit that supports both CPUs and a variety of GPU backends.
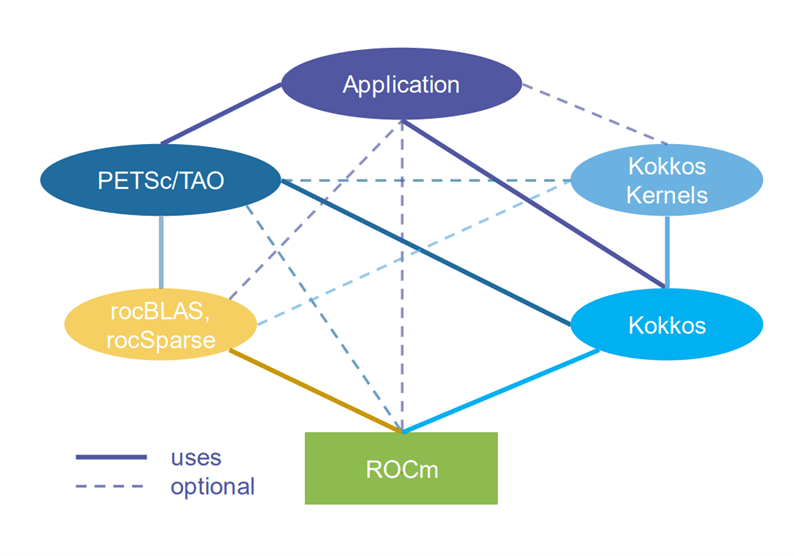
For example, users can transparently use GPUs for common matrix and vector operations via run-time options—no changes to user code required. The team notes that currently the CUDA and Kokkos backends are the best supported, but HIP, SYSCL and Open Multi-Processing are supported and can be selected at build time. Software stacks for NVIDIA, AMD, and Intel GPUs are shown in Figure 13.
 |
 |
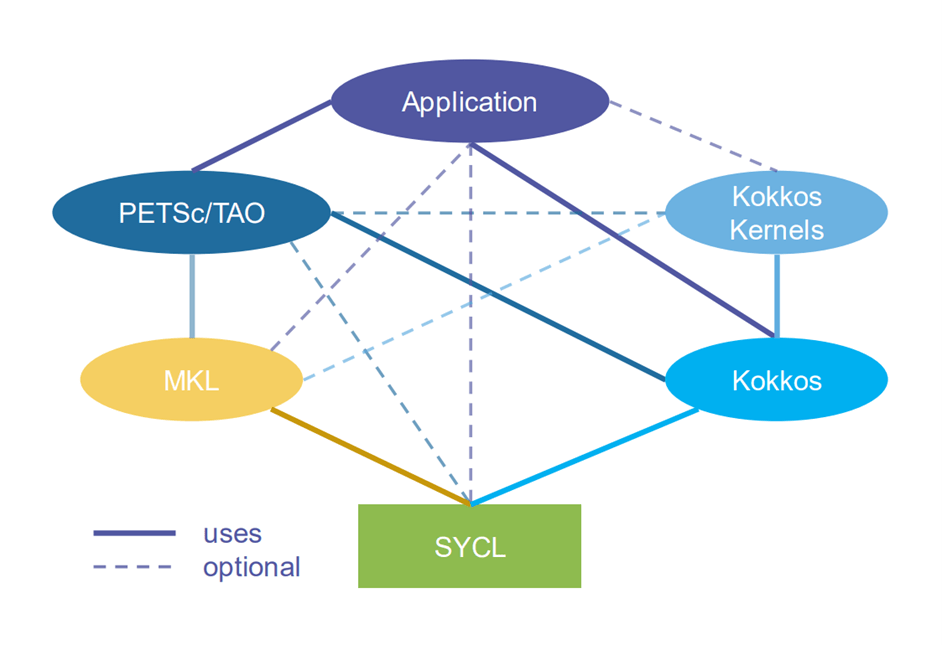 |
Figure 13. Illustrative software stacks for NVIDIA, AMD, and Intel GPUs.
PETSc application codes, regardless if they use time integrators, nonlinear solvers, or linear solvers, follow a common pattern:
- computing application-specific data structures,
- providing a Function computation callback,
- providing a Jacobian computation callback, and
- calling the PETSc solver, possibly in a loop.
This approach does not change with the use of GPUs. In particular, the creation of solver, matrix, and vector objects and their manipulation do not change.
Users must consider where the computation will be performed. This means that the Function and Jacobian callback will call a GPU kernel when running on a GPU. Correspondingly, some data structures must reside in GPU memory. Thus, the user must either construct these data structures on the GPU or copy them from CPU memory.
Summary
PETSc provides a compelling use case that has passed the test of time in creating a sustainable, high-performance library for scientific computation. Key design patterns and motivators include
- letting users program in the language of their choice,
- selecting the run time of hardware components,
- using a community model that ensures longevity,
- providing usable, flexible callback interfaces and abstractions to merge both user needs and hardware capabilities,
- investing in good software design and best practices, and
- testing and validating to ensure excellence in supporting science research.
This research was supported by the Exascale Computing Project (17-SC-20-SC), a joint project of the U.S. Department of Energy’s Office of Science and National Nuclear Security Administration, responsible for delivering a capable exascale ecosystem, including software, applications, and hardware technology, to support the nation’s exascale computing imperative.
Rob Farber is a global technology consultant and author with an extensive background in HPC and machine learning technology.
[1] https://ieeexplore.ieee.org/abstract/document/7914605
[2] https://www.nature.com/articles/s43588-021-00033-y
[3] https://arxiv.org/abs/2201.00967
[4] https://www.exascaleproject.org/highlight/llnl-atdm-addresses-software-infrastructure-needs-for-the-hpc-nnsa-cloud-and-exascale-communities/
[5] https://www.exascaleproject.org/highlight/advancing-operating-systems-and-on-node-runtime-hpc-ecosystem-performance-and-integration/
[6] ibid
[7] See note 3
[8] R. Aymar, P. Barabaschi, and Y. Shimomura, “The ITER design,” Plasma Physics and Controlled Fusion 44, no. 5 (April 2002): 519–565, https://doi.org/10.1088/0741-3335/44/5/304.
[9] http://www.sci.utah.edu/publications/Suc2021a/10943420211019119.pdf
[10] https://arxiv.org/pdf/2011.00715.pdf
[11] https://petsc.org/release/src/vec/is/sf/tutorials/ex1.c.html
[12] See note 10
[13] https://arxiv.org/pdf/2102.13018.pdf
[14] https://on-demand.gputechconf.com/gtc/2016/presentation/s6378-nathan-luehr-simplyfing-multi-gpu-communication-nvshmem.pdf
[15] https://github.com/NVIDIA/df-nvshmem-prototype/blob/master/README
[16] https://docs.olcf.ornl.gov/systems/crusher_quick_start_guide.html
[17] https://www.datacenterdynamics.com/en/news/us-doe-launches-crusher-supercomputer-as-testbed-for-frontier-exascale-system/
[18] https://en.wikipedia.org/wiki/Yield_(engineering)
[19] https://arxiv.org/pdf/2204.01722.pdf