With the advent of the exascale supercomputing era, computational scientists can run simulations at higher resolutions, add more detailed physical phenomena, increase the size of the physical problems, and couple multiple codes spanning both physical and temporal scales. These exascale simulations generate ever-increasing amounts of data. The Data and Visualization efforts in the US Department of Energy’s (DOE’s) Exascale Computing Project (ECP) provide an ecosystem of capabilities for data management, analysis, lossy compression, and visualization that enables scientists to extract insight from these simulations while minimizing the amount of data that must be written to long-term storage (Figure 1).
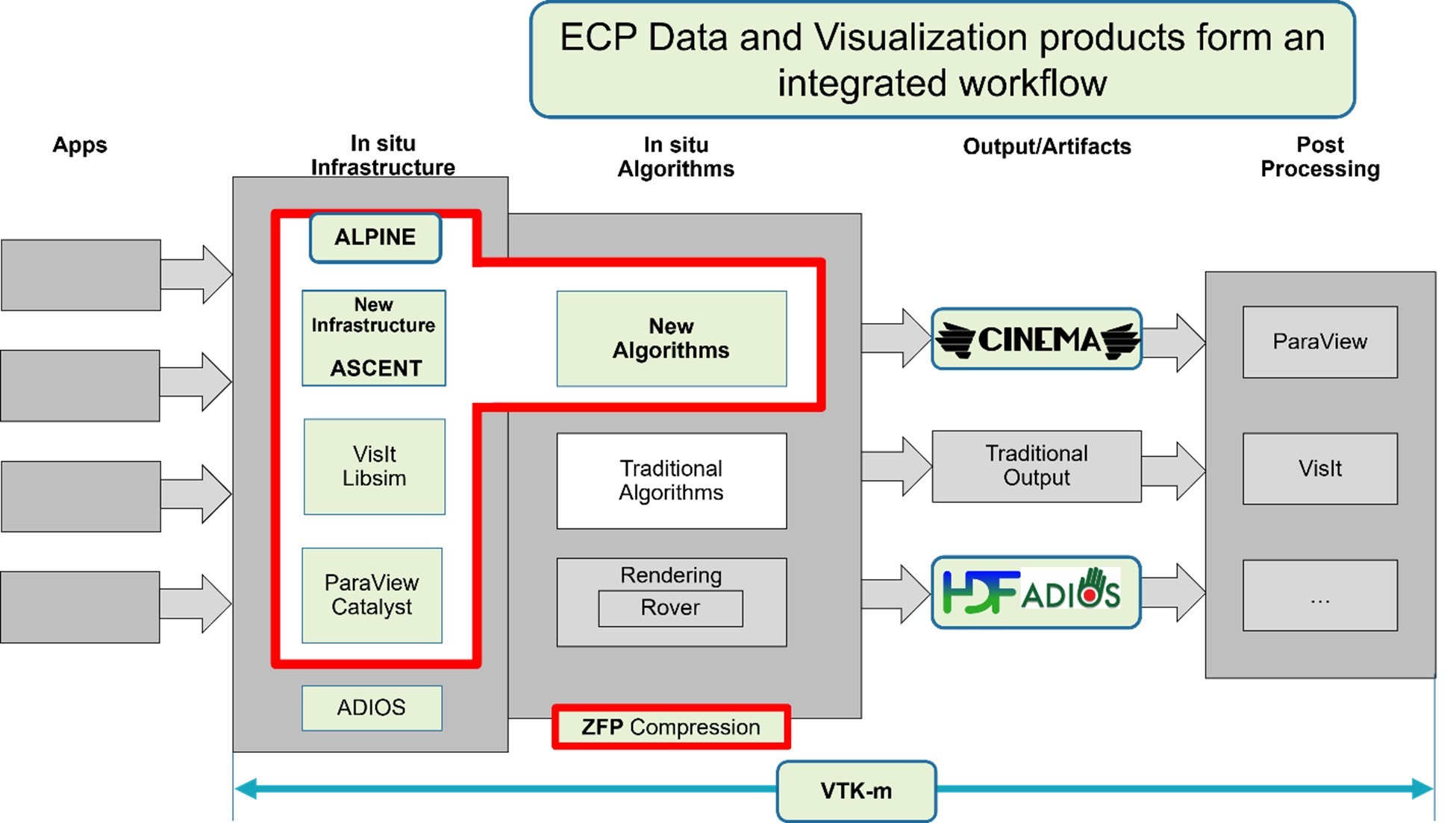
Figure 1. The ECP Data and Visualization products form an integrated workflow.
Big data is the conceptual link between the separate ALPINE and zfp projects that comprise the joint ALPINE/zfp ECP effort. The ALPINE project focuses on both post hoc and in situ infrastructures. The in situ approach delivers visualization, data analysis, and data reduction capabilities while the simulation is running. This approach takes the human out of the loop and can potentially move much of the post hoc analysis or visualization tasks from post hoc to in situ. ALPINE also has supported the development of a range of analysis algorithms over the course of the ECP. These algorithms often have the goal or side benefit of data reduction. The zfp project addresses the compute and I/O mismatch through floating point compression algorithms.
James Ahrens (Figure 2), project lead of ALPINE and L3 for the ECP Data and Visualization portfolio and staff scientist at Los Alamos National Laboratory (LANL), noted, “The purpose of ALPINE is to provide insight from massive data through general yet exascale-capable visualization and analysis algorithms.” Peter Lindstrom, computer scientist and project leader in the Center for Applied Scientific Computing at Lawrence Livermore National Laboratory (LLNL) and lead developer of zfp, noted that “zfp reflects a change in mindset in compression. The idea is to throw out the least significant floating point data bits via lossy compression acting in accord with user-defined error bounds. Further, let the application directly use the compressed data by making the algorithms both fast and amenable to hardware acceleration.”
 |
 |
Figure 2. James Ahrens (left) and Peter Lindstrom (right).
These two projects, with ECP funding, address key software development needs for exascale science applications:
- ALPINE
- Deliver exascale visualization and analysis algorithms that will be critical for ECP applications as the dominant analysis paradigm shifts from post hoc (postprocessing) to in situ (processing data in a code as it is generated).
- Deliver exascale-capable infrastructure for the development of in situ algorithms and deployment into existing applications, libraries, and tools.
- zfp
- Deliver lossy compression through zfp—an open-source library for compressed floating point arrays that supports very high throughput read and write random access.
- Engage with ECP science applications to integrate zfp capabilities into their software, including variable-rate CUDA compression support, a HIP backend, support for 4D arrays, and new C and Python APIs for interacting with zfp’s C++ compressed-array classes.
The ECP Software Technology (ST) focus area is designed to support a diverse ecosystem of software products in a cohesive and collaborative software stack that emphasizes interoperability and sustainability for high-performance computing (HPC) and national security applications. Both ALPINE and zfp capabilities are part of this ECP ST focus area.
For easy deployment in a consistent system environment, these components are available through the Extreme-scale Scientific Software Stack (E4S) so they can be easily deployed as binaries or built on most computer systems from laptops to supercomputers.[1] Furthermore, the E4S software distribution is tested regularly on a variety of platforms, from Linux clusters to leadership platforms, to ensure performance and correct operations.[2]
ALPINE infrastructures include ParaView and VisIt for post hoc visualization and Catalyst and Ascent for in situ use cases. ParaView, Catalyst, and VisIt represent long-term investments by DOE, whereas Ascent is a new lightweight infrastructure developed under the ECP. Ascent supports a diverse set of simulations on many-core architectures. It provides a streamlined interface that minimizes the resource impacts on host simulations with minimal external dependencies.
These infrastructures integrate with co-design libraries, I/O capabilities, and compression capabilities, whereas zfp makes itself available through I/O technologies and other ECP libraries. Using only documentation and tutorials, external groups have adopted E4S software components, starting from scratch and using only internal resources. The uptake of Ascent demonstrates the success of the ALPINE ECP development and Ascent efforts. Such successes also indicate that short time to delivery and limited budget projects can successfully utilize Ascent and projects in which collaborative efforts are discouraged or forbidden.
ALPINE Technical Drivers
Ahrens noted, “The ALPINE project demonstrates the advantages to having people work together rather than creating separate, overlapping tools. The idea driving the ALPINE project is to give users the ability to examine larger spatial problems and exploit more efficient parallel computing. Both are important due to the massive amounts of data possible on GPU-accelerated hardware.” He also noted that GPU compression with zfp is important.
The ALPINE project demonstrates the advantages to having people work together rather than creating separate, overlapping tools. The idea driving the ALPINE project is to give users the ability to examine larger spatial problems and exploit more efficient parallel computing. Both are important due to the massive amounts of data possible on GPU-accelerated hardware. — James Ahrens
The community development model has proven very important for general-purpose HPC libraries and tools.[3], [4] The community model collectively solves a generic computational need in a cost-effective manner because groups can leverage the same funding and technology investment. Cooperation also contributes to a healthy development community because it gets people working on the same services rather than competing.
Cross-fertilization between other projects is good and a natural extension of the community model. This approach benefits groups that may not have the resources or capability to interact with other groups solving similar problems. Further community-based projects are far more likely to maintain and provide support in the future. Ahrens noted that making compressors such as zfp or SZ available via ALPINE infrastructures is a good example of cross-fertilization with other projects that provides support for a broad range of data types.
As part of the unified ECP workflow, a strong collaboration also exists between the ECP ALPINE and the Cinema project. The Cinema project is a highly interactive image-based approach to data analysis and visualization. Through browser-based viewers, Cinema provides access to visualization images that can be exported through ALPINE infrastructure as part of the in situ approach. Scientific workflows leveraging ALPINE in situ and Cinema post hoc provide the analytic capabilities users need for flexible exploration of their data. The December 3, 2020, episode of the ECP’s Let’s Talk Exascale podcast, “Supporting Scientific Discovery And Data Analysis in the Exascale Era,” featured the Data and Visualization portfolio lead Ahrens discussing ECP visualization tools, including Cinema and ALPINE, with host Scott Gibson.
ALPINE for Algorithms and Infrastructure
The ALPINE team is addressing two problems related to exascale processing: (1) delivering infrastructure and (2) delivering high-performance in situ algorithms.[5] These capabilities provide users with a high-performance infrastructure for in situ exascale visualization and the ability to computationally identify features in the data.
ALPINE analysis algorithms support topological analysis, adaptive data-driven sampling approaches, task-based feature detection, statistical feature detection, Lagrangian flow analysis, and optimal viewpoint characterization. ALPINE infrastructure can be used in concert with these algorithms and with other ECP capabilities to develop visualization pipelines to support scientific discovery. The ALPINE algorithms documentation describes these features, capabilities, and more.
An example from an ECP science workflow can be seen in Figure 3. To create these images, the ECP Combustion-Pele science application is linked via Ascent to a cokurtosis kernel from the ECP ExaLearn project to search for autoignition events.
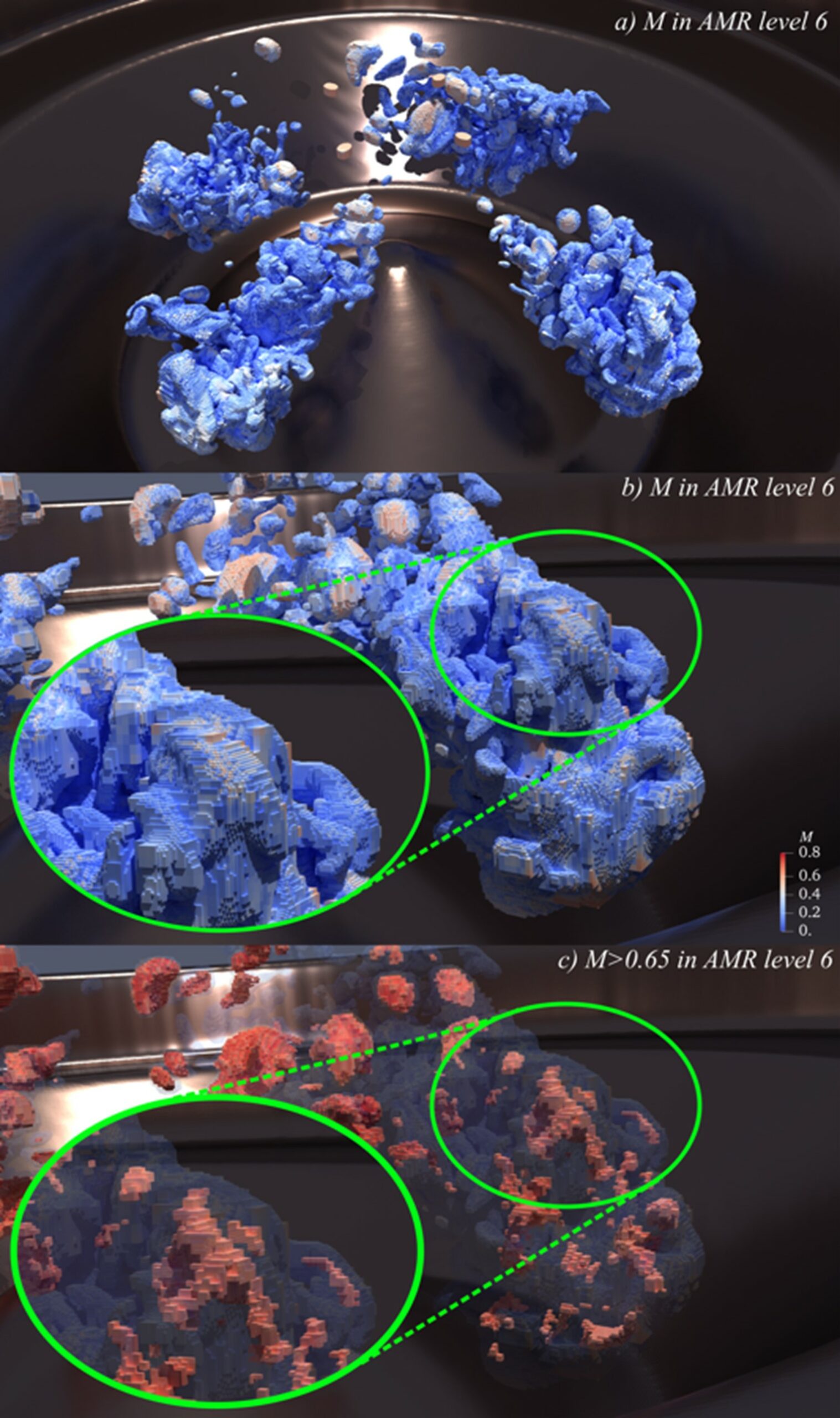
Figure 3. To each box, containing at least 163 cells, corresponds a single nondimensionalized metric value M, colored from blue to red; higher values of M correspond to a larger possibility for autoignition. (a) Metric values for the box subset on the highest level of refinement (level 6). (b) Detailed view of adaptive mesh refinement (AMR) blocks in the highest level of refinement. Zoomed-in view (green circle) shows the blocks in more detail. (c) Same detailed view as in panel a but only for blocks with anomaly metric M > 0.65. Figures were produced a posteriori using Python and ParaView. (Credit: J. Salinas, M. Arienti, and H. Kolla [Sandia National Laboratories]))
In terms of ease of use, David Honegger Rogers (PI and team lead for the Data Science at Scale team at LANL), noted that ALPINE’s Catalyst infrastructure is designed so scientists can think about the data —specifically the images—and not about the infrastructure that accomplishes the task.
zfp Technical Drivers
In the separate zfp project, Lindstrom explained the technical drivers motivating the use of zfp for lossy compression: “Data movement is going to become a gating factor in terms of performance and power consumption. We have to figure out a better way. Most data compressors don’t work well on floating point data.” (See Figure 4.) Lindstrom noted that even the best compressors can reduce the data size by only 10%. A high-level overview is provided in the YouTube video “zfp: Fast, Accurate Data Compression for Modern Supercomputing Applications.” The paper “Significantly Improving Lossy Compression for HPC Datasets with Second-Order Prediction and Parameter Optimization” and supplemental video noted that lossless compression cannot lead to a high reduction ratio on scientific data because the ending mantissa of scientific data looks very random.[6],[7]
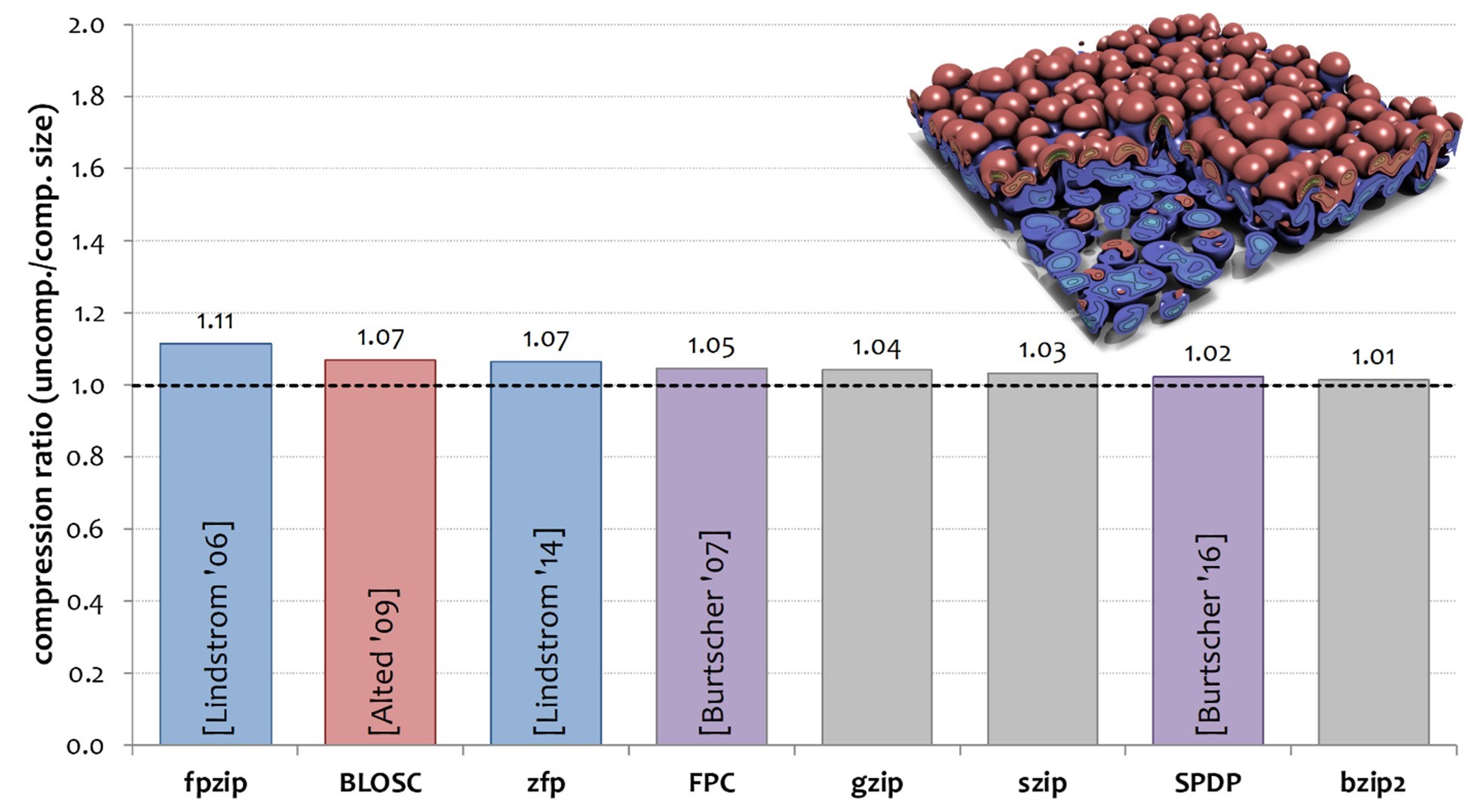
Figure 4. 64-bit floating point data does not compress well losslessly. Even the best compressor can reduce data size by only 10%.
The inability to directly access compressed data requires initiating a multistep set of operations to access compressed data: read the compressed data, uncompress it in memory, and then access the data via some usage model. Lindstrom noted that compressors traditionally support only sequential access. Just as with a tape, accessing data requires starting at the beginning of the sequential stream of (relatively large) compressed data. In contrast, zfp supports random access to tiny bits of data (e.g., in chunks of 64 uncompressed bytes [1 cache line] at a time).
Lindstrom continued, “zfp lets applications process compressed data on the fly, plus it allows random access into the compressed data. This means simulations can effectively run with larger memory footprints by keeping the working stack compressed. This is important in heterogenous computing environments given limitations of GPU memory capacity compared to CPUs, which also explains the importance of using zfp to perform compression and decompression operations on GPUs.” The reduced size of the compressed data is also important for I/O and network operations. See Figure 5.
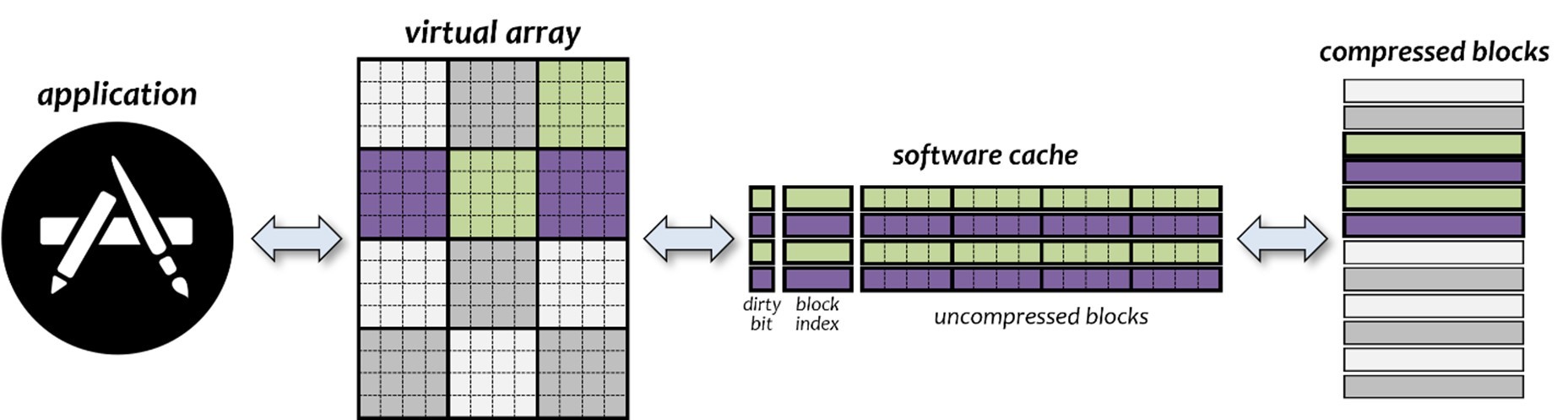
Figure 5. zfp arrays limit data loss via a small write-back cache.
The “change in mindset” referred to by Lindstrom reflects how lossy compression of floating point data makes scientists nervous. To address this reasonable skepticism and concern about introducing unacceptable errors, the zfp team has developed rigorous error bounds for zfp both for static data and in iterative methods (Figure 6). Furthermore, the team has worked to ensure zfp error correction ensures unbiased errors.[8]
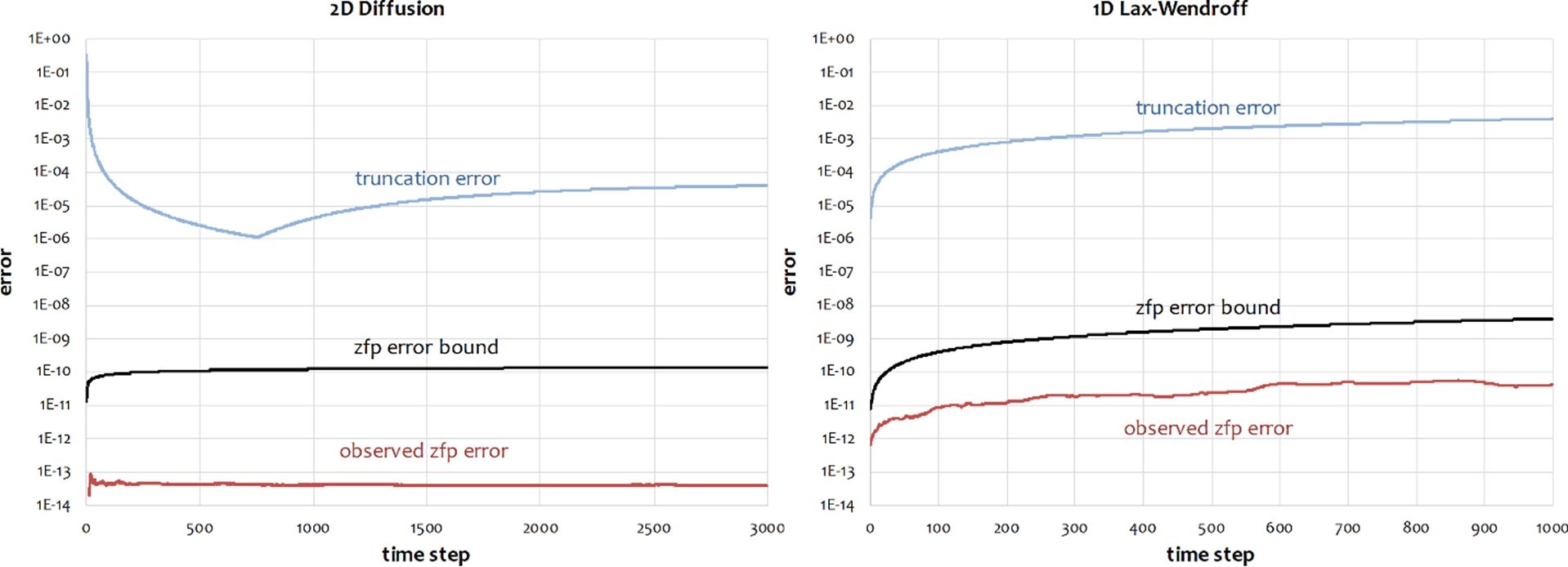
Figure 6. zfp has rigorous error bounds. See [Fox et al., “Stability Analysis of Inline zfp Compression for Floating-Point Data in Iterative Methods,” SIAM SISC 2020] for more information.
Use Cases Highlight the Value of Both Projects
Scientists and application developers are using both ALPINE and zfp. Numerous use cases highlight the value of each individual project.
Recent ALPINE Highlights
Ahrens highlighted that ALPINE is already helping projects achieve exascale capability but that this is a new approach, and the project is just starting. “We are in the process of building our user community,” he said, “and automating some of the workload. Users can currently make all the choices to perform interactive postprocessing. We are now exploring approaches to pick the cameras correctly via automated means.”
Ahrens highlighted a number of recent integration successes:
- WarpX: [10] A highly optimized particle-in-cell (PIC) simulation code that can run on CPUs and GPUs, WarpX is used to model the motion of charged particles, or plasma. These simulations have many applications, including nuclear fusion, accelerators, space physics, and astrophysics.[11] In simulations run in 2022, the WarpX project demonstrated a 500× improvement in performance on the exascale Frontier supercomputer over the preceding version of Warp.[12] WarpX has reached its project goal by running at scale on Frontier along with performing the first 3D simulations of laser-matter interactions on Frontier, Fugaku, and Summit—something that has so far been out of reach for standard codes.[13] Integrating WarpX with ALPINE’S Ascent infrastructure enables the generation of complex visualizations in situ, thereby speeding up the generation of movies that drive scientific insight for domain scientists. See Figure 7.
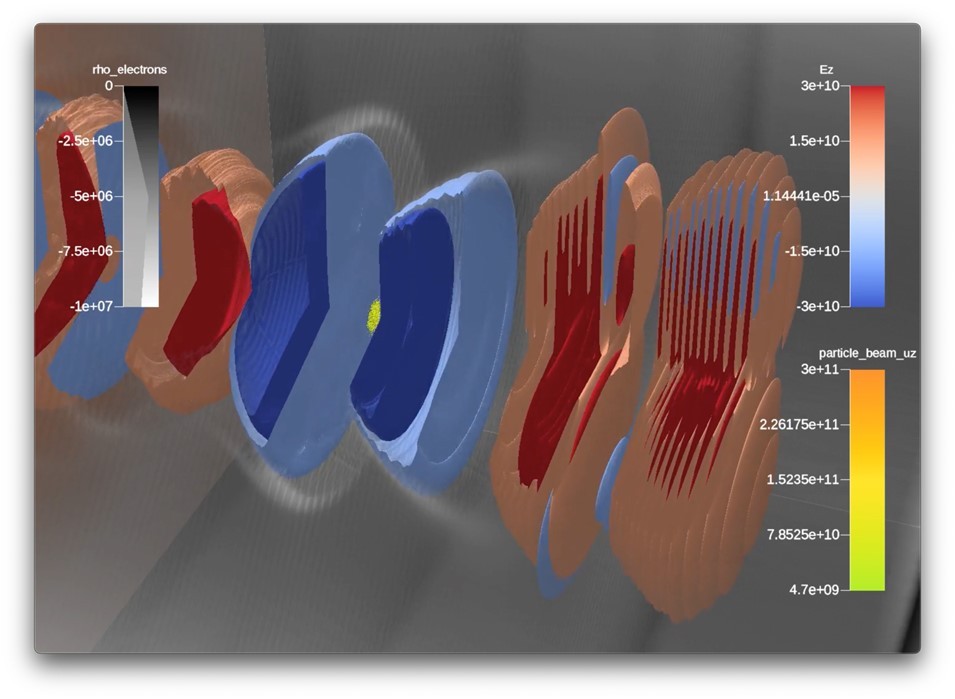
Figure 7. In situ visualization with Ascent and VTK-m of a staged laser-wakefield accelerator simulation run on Frontier with WarpX. Shown are the strong accelerating fields (red to blue) in the plasma stages (gray). Injected in this structure is an electron beam (green to orange) that is accelerated to the right to high energies. (Credit: Nicole Marsaglia [LLNL] and Axel Huebl [Lawrence Berkeley National Laboratory])
- Ascent-NekRS: Ahrens noted that an integration of NekRS with Ascent is ongoing. Researchers use NekRS for mission-critical DOE problems such as the simulation of coolant flow inside small modular reactors.[14],[15] Using the prototype Ascent-NekRS integration, volume-rendered flow-field images were generated at multiple time steps for a simple Couette flow test case, which has an analytical solution.
- AMR-Wind: AMR-Windis a massively parallel, block-structured adaptive mesh, incompressible flow solver for wind turbine and wind farm simulations.[16] It is part of the ExaWind software ecosystem. The primary applications for AMR-Wind are performing large eddy simulations of atmospheric boundary layer flows, simulating wind farm turbine-wake interactions for turbines (Figure 8), and performing (in combination with Nalu-Wind) blade-resolved simulations of multiple wind turbines within a wind farm.

Figure 8. Snapshot of the instantaneous flow field for an NM-80 rotor using the hybrid ExaWind simulation solver suite. The image shows the tip vortices rendered using Q-criterion, and the contour colors show the magnitude of the x-velocity field. (Credit: Mike Brazell, Ganesh Vijayakumar and Shreyas Ananthan [National Renewable Energy Laboratory], and AmrWind)
- MFIX-Exa: A collaboration with the ECP MFIX-Exa project demonstrated in situ data reduction and feature detection with post hoc interactive analysis via Cinema. Cinema is a lightweight visualization ecosystem with a database foundation that stores imagery and associated metadata. Developed at LANL, the Cinema project has received ECP funding to develop scientific workflows and incorporate them into components of the ECP ALPINE project.[17] MFIX-Exa specifically targets the scale-up of gas-solids reactors such as chemical looping reactors for industrial carbon capture. Figure 9 shows an image from the integration pipeline that demonstrates the use of ALPINE’s Catalyst statistical feature detection algorithm to identify void regions and write out a feature similarity field in situ while the simulation runs. That similarity field can then be used in a post hoc workflow to identify the void as bubbles, and images are generated for each bubble. Additional information can be found in the paper “In Situ Feature Analysis for Large-Scale Multiphase Flow Simulations.”

Figure 9. Feature detection of bubbles. ALPINE’s in situ statistical feature detection algorithm is used to identify voids or bubbles in the data. The output is reduced from 5 × 109 particles to a small scalar output field.
Recent zfp Highlights
An R&D 100 winner in 2023 and a compressed floating point and integer arrays software with over 1.5 million downloads per year, zfp has achieved significant recognition and uptake by its HPC and industry user base. The need to address the cost of data movement illustrates why (Figure 10). Lindstrom noted in his International Conference for High Performance Computing, Networking, Storage, and Analysis (SC22) presentation that zfp compression on a GPU achieves up to 700 GB/s of data transfer throughput.[18]
Figure 10. Data movement will dictate performance and power usage at scale. (Credit: Peter Lindstrom)
According to Lindstrom, zfp has the following benefits while addressing user questions:
- zfp compression enables substantial savings in storage, including the following:
- A 4–10× reduction in numerical state (e.g., partial differential equations [PDEs])
- A 10–250× reduction in data analysis and visualization
- zfp provides a continuous knob that enables trading accuracy and storage, including the following:
- No half/float/double dichotomy as in mixed-precision computations
- A 1,000,000× reduction in error using similar storage
Use Cases Illustrate zfp Benefits
In his SC22 presentation, “Compressed Number Representations for High-Performance Computing,” Lindstrom illustrated these benefits through a variety of HPC use cases. A few are excerpted below.
A More Than 4× Reduction in Data Size
Another important application of zfp arrays is in-memory storage of state and large tables in numerical simulations. Arrays of zfp reduce the memory footprint and may even speed up severely memory bandwidth–limited applications. Figure 11 illustrates how zfp arrays are used in a 2D simulation of a shock-bubble interaction. It shows the final-time density field resulting from computing on simulation state arrays (e.g., density, pressure, velocity) represented as conventional 64-bit and 16-bit IEEE floating point (top row) and 12-bit zfp and 16-bit posit arrays (bottom row). At less than 5× the storage, zfp arrays give essentially identical simulation results to 64-bit double-precision storage, and the competing 16-bit representations show significant artifacts. For the simulations below, running with compressed arrays took 2.5× as long as running with uncompressed floats or doubles, although in read-only applications such as ray tracing, reduced rendering time using compressed arrays has been observed (Figure 11).
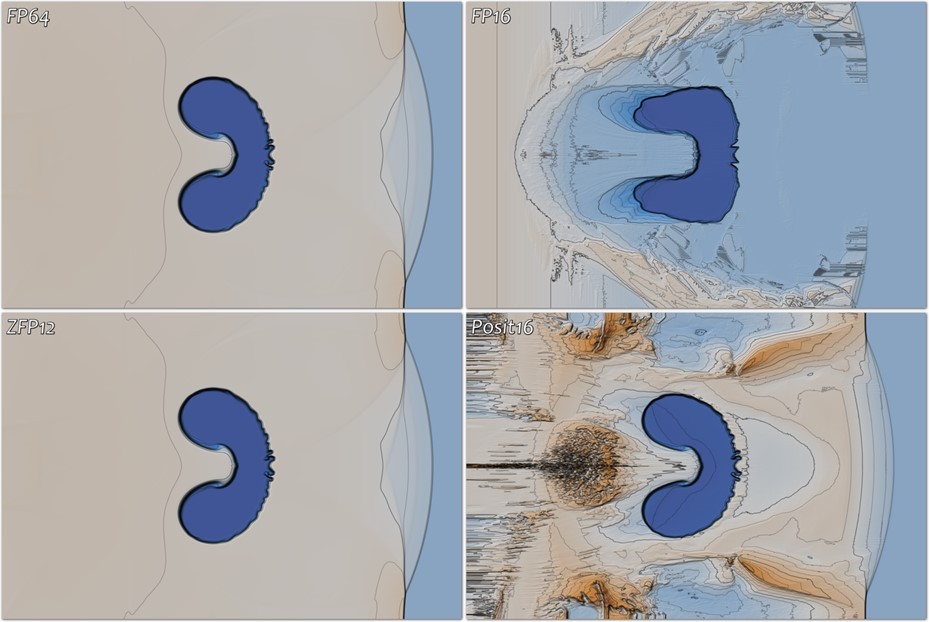
Figure 11. Final-time density field of a 2D simulation of a helium bubble (dark blue) impacted by a shock using four different number representations. At only 12 bits/value in-memory storage, zfp yields a solution (bottom left) that is qualitatively identical to the ground-truth solution (top left) based on a 64-bit IEEE double-precision floating point. Using 16-bit IEEE half precision (top right) and 16-bit posits (bottom right) results in significant artifacts from rounding errors that propagate and grow over time (source). Click here to watch a movie of this process.
Improved Accuracy
In a separate use case, zfp adaptive arrays were used to improve the accuracy of a PDE solution by 6 orders of magnitude while using less storage. The zfp compressed error of 9.5 × 10−11 is significantly better than that of FP32 (Figure 12).
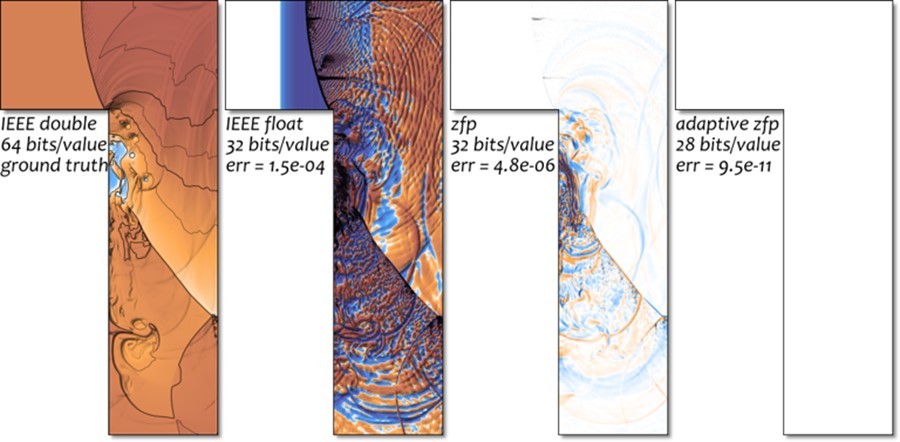
Figure 12. zfp adaptive arrays improve accuracy in PDE solution over IEEE by 6 orders of magnitude while using less storage. (Credit: Peter Lindstrom)
Increased Grid Resolution for Some Problems
Contrary to conventional thinking, zfp compression can actually increase the accuracy of some finite-difference problems by enabling increased grid resolution (Figure 13).
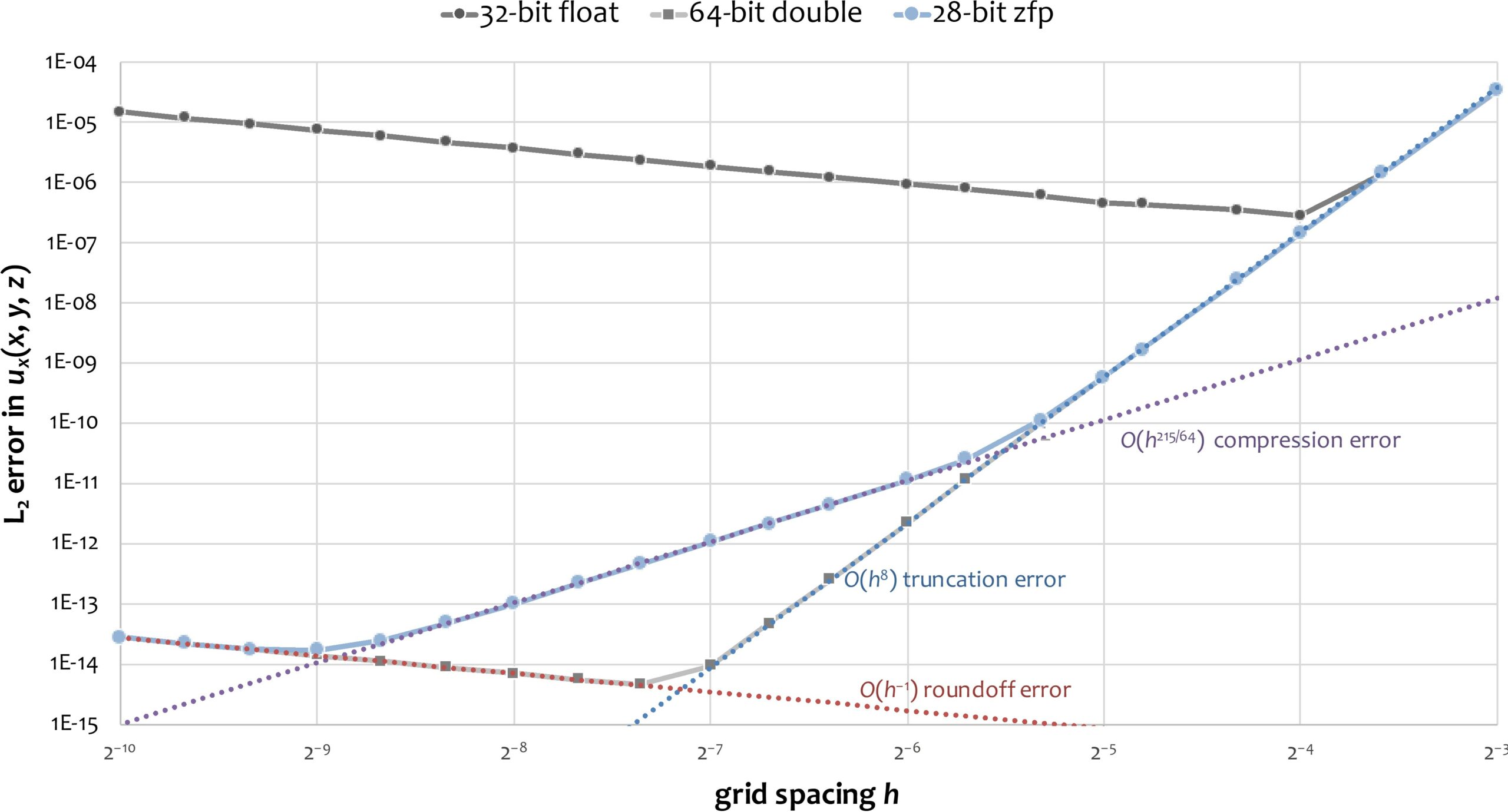
Figure 13. zfp can enable computations on finer grids to increase accuracy compared with convention floating point. (Credit: Peter Lindstrom)
Summary
The combined ALPINE/zfp delivers a two-pronged approach to addressing the last-mile problem in data storage and visualization. ALPINE provides visualization methods that can render images on the same nodes that are running the simulation (e.g., in situ visualization). Additional analysis techniques can help scientists automatically identify key features in situ.
The zfp project compresses floating point data to ease the burden on memory capacity. This capability can greatly help when running on GPU devices and particularly problem domains such as high accuracy, finite-difference methods. It also helps decrease data volumes to ease the burden of data movement across storage and communications subsystems. With over 1.5 million downloads per year, zfp has demonstrated significant adoption in industry and the HPC communities.
This research was supported by the Exascale Computing Project (17-SC-20-SC), a joint project of the US Department of Energy’s Office of Science and National Nuclear Security Administration, responsible for delivering a capable exascale ecosystem, including software, applications, and hardware technology, to support the nation’s exascale computing imperative.
[1] https://e4s-project.github.io/
[3] https://arxiv.org/abs/2201.00967
[4] https://www.exascaleproject.org/research-project/xsdk4ecp/
[5] https://ALPINE.dsscale.org/
[6] See time 4:46 in the supplemental material video: https://dl.acm.org/doi/10.1145/3369583.3392688.
[7] https://dl.acm.org/doi/10.1145/3369583.3392688
[8] https://doi.org/10.1109/DRBSD-549595.2019.00008
[9] https://sc22.supercomputing.org/presentation/?id=misc169&sess=sess421
[10] https://doi.org/10.1063/5.0028512
[11] https://awards.acm.org/bell
[12] https://crd.lbl.gov/news-and-publications/news/2023/warpx-code-shines-at-the-exascale-level/
[13] https://www.exascaleproject.org/warpx-code-shines-at-the-exascale-level/
[14] https://www.exascaleproject.org/highlight/exasmr-models-small-modular-reactors-throughout-their-operational-lifetime/
[15] https://www.alcf.anl.gov/news/optimizing-computational-dynamics-solver-exascale
[16] https://exawind.github.io/amr-wind/api_docs/index.html
[17] https://www.exascaleproject.org/highlight/visualization-and-analysis-with-cinema-in-the-exascale-era/
[18] https://sc22.supercomputing.org/presentation/?id=misc169&sess=sess421