Let’s Talk Exascale Code Development: WDMapp—XGC, GENE, GEM

Clockwise from top left: Tim Williams of Argonne National Laboratory, Aaron Scheinberg of Jubilee Development, Kai Germaschewski of the University of New Hampshire, and Bryce Allen of Argonne National Laboratory and the University of Chicago
Welcome to episode 82 of the Let’s Talk Exascale podcast. This is where we explore the efforts of the Department of Energy’s Exascale Computing Project—from the development challenges and achievements to the ultimate expected impact of exascale computing on society.
And this is the third in a series of episodes based on work aimed at sharing best practices in preparing applications for the upcoming Aurora exascale supercomputer at the Argonne Leadership Computing Facility.
The series is highlighting achievements in optimizing code to run on GPUs. We are also providing developers with lessons learned to help them overcome any initial hurdles.
This episode focuses on the computer codes used in the ECP project called WDMapp, or Whole Device Model application. The objective of the project is to develop a high-fidelity model of magnetically confined fusion plasmas. The modeling is urgently needed to plan experiments on ITER—the International Tokamak Experimental Reactor—and on future fusion devices.
Joining us are subject-matter experts Tim Williams of Argonne National Laboratory, Aaron Scheinberg of Jubilee Development, Kai Germaschewski of the University of New Hampshire, and Bryce Allen of Argonne National Laboratory and the University of Chicago.
Our topics: the goals of WDMapp and how its supporting coupled computer codes fit in, insights about the research the codes are used for, preparing the codes for exascale and how the WDMapp project applications will benefit from exascale, preparing for the Aurora machine, best practices, advice for researchers in getting codes ready for GPU-accelerated exascale systems, and more.
Interview Transcript
Gibson: Tim, can you start us off by telling us about the goals of the Whole Device Model Application project and how the various codes fit in?
Williams: This project is looking to model in a high-fidelity way the magnetically confined fusion plasma in a tokamak device. And especially looking toward exascale systems, we want to model plasmas in the ITER tokamak, which is now under construction.
If you look back at the history of tokamak devices, there’s been a succession of larger and larger ones with more successful plasma experiments, but there are phenomena such as microturbulence that lead to loss of confinement of energy in the plasma, which is a bad thing. And as the tokamaks got bigger in one important way, this loss behavior got worse. But there is theory and some simulations that have backed this theory up that once you get beyond a certain size, as ITER will, this behavior actually becomes better. And there are some important physics that act to confine the plasma better in a high-confinement mode—so-called H mode—and this relies on the formation of what’s called a pedestal at the edge of the plasma, which greatly improves the confinement.
This behavior, we understand it through theory and extrapolation from smaller machines, and it’s very important that it works correctly for ITER’s success. So, there’s a lot of interest in these kinds of simulations to understand that behavior and to use that then to plan experiments for ITER.
As I said, ITER is much larger than any existing tokamaks. If you think of it as a doughnut, with the radius of the doughnut being a metric of measurement, ITER’s major radius is 6.2 meters. The work we’re talking about in this project is doing kinetic plasma modeling as opposed to treating the plasma as a fluid, and this captures some very important physics effects that are relevant to this edge pedestal. It’s a special flavor of kinetic plasma modeling called gyrokinetics, so that’s why you see the letter G everywhere in the names of these various codes. The codes included in the project are XGC and two other kinetic codes—GENE and GEM.
A big part of the work is coupling of these codes together. One of the codes—a choice of either GENE or GEM—will be used to model the central core plasma in the tokamak. The other, XGC, will be used to model the edge of the plasma. And coupling those two together is itself an interesting and challenging numerical and mathematical problem. There’s no real barrier between the core and edge plasma, but in a simulation, you have to have some region of overlap and you have to consistently model the plasma using these different codes so that it’s a smooth transition. The reason you use two different codes is because the physics is different and simpler in some regards in the core plasma, so you can make a much more efficient kinetic simulation there than you can in the edge. So, it’s a cost-saving means.
The XGC code that models the edge, it includes some of the more complex features of the magnetic field. There’s a very strong imposed magnetic field that confines the plasma in a device like ITER, and that magnetic field has something called an X-point as you get toward the outer layers of the plasma. And that’s where the X in XGC comes from. There is some important physics that are being added to these simulations looking toward exascale, including magnetic fluctuations of the plasma in addition to the more traditionally modeled electrostatic or electric-fluctuations and also the inclusion of impurity ions—tungsten ions, in particular, that come off of the walls of the ITER or other tokamak device.
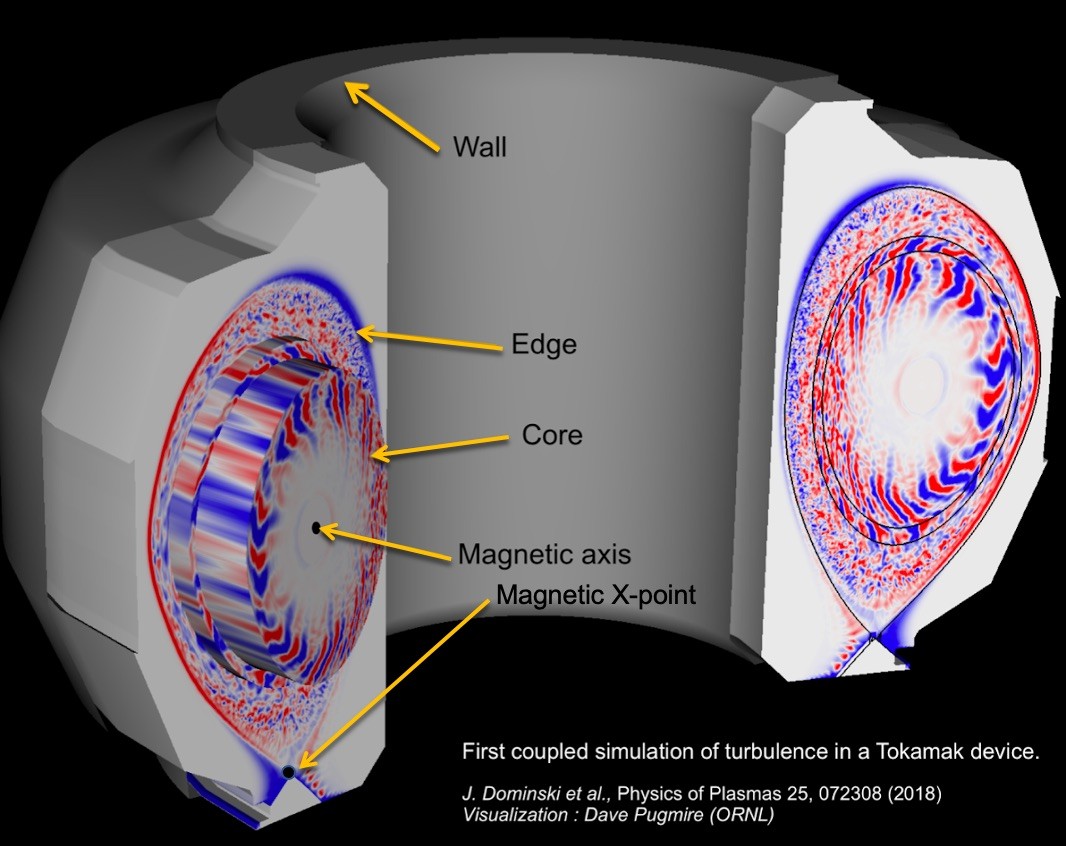
And I’ll just make one further comment that in addition to the work with ECP, there’s a project with XGC supported through ALCF’s Aurora Early Science Program that will be doing electrostatic simulation with ion impurities.
As to what the goals of ITER are, for the broader context, ITER aims to have a net gain of energy. Putting in 50 megawatts of heating power for the plasma, ITER should return 500 megawatts of power from fusion reactions in that plasma. It will produce what’s called a burning plasma, meaning there’s enough energy generated from fusion reactions within the plasma to sustain the high temperature of that plasma, some 150 million degrees, through energy from those reactions, with no need for additional external heating.
In this plasma you have deuterium and tritium, two hydrogen isotopes, and those, when they collide, get close enough to each other, as they do when they collide at very high temperature, have a nuclear reaction that produces a helium nucleus and a neutron and a substantial amount of energy, There’s a mass difference in what goes in an what goes out. That mass is converted directly to energy, and the famous factor of E=MC2 gives you a large multiplier to produce energy.
ITER will also demonstrate a lot of the technologies that will be needed for future actual fusion reactor plants and a few other important things such as generation of tritium that’s part of its fuel from the device itself.
Gibson: OK. With that very insightful background information, let’s get into some details about the codes. What type of research are GENE, GEM, and XGC used for? Our subject-matter experts speaking to that topic are Aaron and Kai. First, Aaron, will you tell us about XGC? And then we’ll pivot to Kai for information about GENE and GEM.
Scheinberg: XGC’s strength is, in particular, edge physics, although it’s a versatile code that can also examine other aspects of plasma physics. The challenge in the edge is, first of all, you can’t treat the changes—the plasma perturbations—as simply a perturbation from a mean. So you need to be able to model the distribution function in a nonlinear way. And another challenge is having to deal with the X-point, which in continuum codes and in certain coordinate systems can be a singularity. And so, the separatrix that separates the core from the edge can be a challenge to model. XGC uses an unstructured grid that allows you to model both the walls of your plasma containment vessel and the X-point and separatrix, which are more complicated geometries than in the core, in a consistent way.
Another key feature is that it is a particle-based code, so when you’re trying to describe a plasma, the state of a plasma is a distribution function. You can think of it as the density in space and the density in velocity space, and in a particle code you have that information inside of particles that are moving around in physical space in your simulation.
Germaschewski: Just like all of the codes in this project, GENE is a gyrokinetic code. It solves the time evolution of the 5D gyrokinetic distribution function. That is, it does use a very close to first principles kinetic description of a plasma. GENE is a continuum code, which means that it discretizes the 5D distribution function directly in 3 spatial and 2 velocity space dimensions. And it does take advantage of a simpler magnetic geometry in the core for its coordinates system.
For a bit of background on GENE, it’s been developed over the past 20-plus years. It has a large user community of researchers and students investigating plasma microturbulence and transport. This code has been targeted and optimized in particular for simulating small-scale turbulence in the closed flux-surface region in the core of a fusion device. It’s also been applied beyond nuclear fusion—for example, in space and astrophysics to study the turbulence in the solar wind.
In the WDMapp project, as Tim already mentioned, there’s also an alternative option for the core, and that is the GEM code, which is another well-established gyrokinetic code which is also designed for simulating the core plasma in a fusion device.
GEM employs a different numerical approach than GENE. Instead of discretizing the distribution function directly, it samples it using marker particles, so it’s using the particle-in-cell method quite similar to what XGC does.
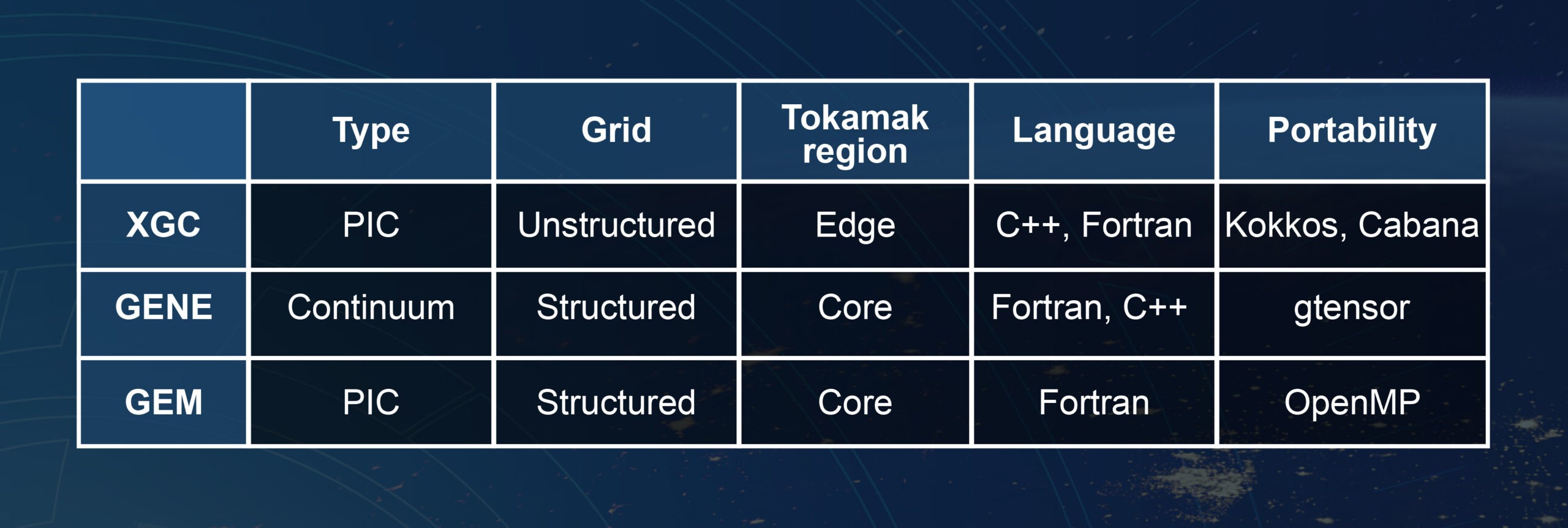
Comparison of the WDMapp coupled codes
Gibson: Kai, how will the WDMapp project applications benefit from exascale computing power?
Germaschewski: As Tim already mentioned, the stretch goal for this ECP project is to develop the capability of predicting the edge pedestal height and shape in the ITER machine, and that will have a critical impact on the successful operation of ITER. Optimizing the pedestal essentially means trying to create as good a transport barrier as possible, so keeping the energy and the particles confined inside the core plasma and being able to fuse there rather than it being lost out to the edge. And that’s crucial to achieving ignition—that is, getting a burning fusion plasma which is self-sustaining. Beyond that, there are also many other active areas of research that will benefit from the upcoming exascale capabilities.
On the GENE side, one example is simulating and analyzing multiscale turbulence. That is, it involves electrons and ions. Electrons are much lighter than the ions, and so they experience different kinds of instabilities, and the turbulence happens on different spatial and time scales. Currently, only a handful of pretty limited multiscale simulations have been performed, due to their extreme computational cost, and they’ve been using an additional approximation, looking at flux tubes only.
From this preliminary work, we have found unexpected cross-scale interactions, and we don’t fully understand those yet. And with the added exascale computing power, we will actually be able to simulate full-scale simulations of such a plasma which is multiscale and so involves both electrons and ions in one simulation and also is going to allow us to have a more realistic model of the tokamak.
Gibson: So, what new vistas will exascale open up for XGC, Aaron?
Scheinberg: As Kai has said, the main challenge with plasma physics is this multiscale issue, where we need to be able to understand how turbulence—that occurs on the length scales of tenths of millimeters—is going to interact with effects that occur on the scale of the full tokamak, which is meters. And in order to look at these individual problems, before we’ve always had to split up the problem and make a lot of assumptions—from gyrokinetics to separating the core from the edge, because the core’s timescale is about a hundred times slower than the edge timescale in terms of most physics of interest, and then also assuming an electrostatic plasma rather than an electromagnetic plasma, which means that there is a perturbation to the magnetic field that is non-negligible created by the plasma itself.
And previous simplifications have always involved studying these phenomena essentially separately or assuming that they’re not interacting with each other strongly. With exascale computing, we will be able to do a lot with XGC and WDMapp, including impurities, such as tungsten, that will strongly affect the heat distribution of a plasma as well as these multiscale ion scale turbulence and electron scale turbulence at the same time, plasma wall interactions, RF heating, and energetic particles, which are going to need a shorter timescale to resolve. And with exascale computing, we will be able to do all of these in a self-consistent manner and study how they interact.
Gibson: Now let’s talk about how you’re preparing these codes for exascale. How do you get ready for systems that don’t yet exist?
Scheinberg: Fortunately, we’re not going in totally blind to these systems that don’t exist. There’s some continuity between the existing machines like Summit, so we can do a lot of work on existing supercomputers and take those lessons over to the new ones. We’re also constantly running on test beds that are provided by the vendors and that are becoming progressively more similar to the full exascale machines. And, generally speaking, in terms of improving the code, there’s a lot of work to do to make a code work really well on exascale, and that’s keeping us busy.
A major component is taking all of our larger computational kernels and offloading them to the GPUs since these systems will all have most of their computational ability on the GPUs. Another important aspect is flexibility. I want to prepare my code so that if the final machine requires a certain type of communication pattern or memory layout, then this can be changed in a relatively easy way. And a big part of that is abstraction, so using templates in C++ as a means of easily being able to change or swap out a routine. And that’s also modularization, making sure that different aspects of the code don’t affect each other in a way that limits your ability to adapt quickly to these.
Additionally, testing is something that’s just very important when we’re doing this larger refactoring, because if a piece of code needs to be refactored, it’s a lot easier to hone in on bugs that you might introduce during that work if there is a good testing suite. And, finally, the most important way to do work is to outsource work to others—by which I mean libraries. We want to avoid reinventing anything or duplicating efforts, so where there are other applications and other libraries that are doing similar work, we want to be able to take advantage of those rather than using additional effort.
Gibson: Bryce, how are you getting the GENE code ready for exascale?
Allen: Well, as Aaron said, taking advantage of existing leadership-class systems and the early-access exascale systems has been a key factor in allowing us to do this. Also, since all of these upcoming systems rely on GPUs for most of their computational power, a lot of our laptops and inexpensive workstations have GPUs in them. While they can’t be used for large-scale performance testing, they can be useful for feature development for quick turnaround where you can compile and run on your own laptop.
And another really important tool is understanding overall performance of your code, especially if it has no GPU support yet, just understanding how it’s running on CPU using profiling tools. And then as you begin to transition it to run on GPUs, continuing to profile using the tools and see how that balance changes and make sure that we’re focusing on optimizing the parts that really matter. For GENE, specifically, we took advantage of the TAU profiling suite, which has both CPU and GPU profiling features.
For GENE, our initial porting approach is to use CUDA C. GENE is actually a Fortran code, so we considered using OpenMP and OpenACC, but the compilers were not mature at the time we needed to start. In particular, GENE uses features of Fortran 2008, and we ran into some compiler issues related to that. So, just to start the work on restructuring the code for GPUs, we chose the most well-established programming model, which was CUDA, and as Aaron said, Summit became available very early on and allowed us to jump-start development in preparation.
The other thing that we’ve been relying on is working closely with our hardware vendors. These are complex systems still under development, and bugs are expected. So I think it’s a really important skill while working in this area to be able to write good test cases like Aaron was saying and also, when necessary, create bug reports to send to the vendors—and they’ve been very helpful addressing those as quickly as they can. The other thing specific to GENE . . . Our initial approach for porting to GPU—because GENE had really no GPU support—was to factor out the code into operations that could have multiple implementations. In this case, you could have a CPU implementation and a GPU implementation. There was already some of this in the code where you might use different algorithms, and this was sort of extended to have better support for different architectures. And Kai will talk more on how this approach evolved as the port developed.
Gibson: This is for Aaron and Kai. How do you approach developing code targeted at the upcoming GPU-accelerated architectures?
Scheinberg: Well, first I want to say that there are a lot of good ways to do it, so I don’t want to tell any other applications that this way is the right way. In fact, even the three codes within WDMapp have chosen very different approaches to getting onto these GPU-accelerated architectures.
The way that XGC has chosen has been to use Kokkos, which is a programming model that acts as an abstraction layer to allow us to run with CUDA or HIP or SYCL depending on which architecture we’re on. In addition, Kokkos allows us to use OpenMP as a back end. So we can both use the native languages supplied by the vendors or the OpenMP offloading and we can compare and see which are going to be the best in which situations.
An additional library that we’ve incorporated while getting started on these architectures has been Cabana, which is a library also part of ECP, in the ECP CoPA project. This is a Kokkos-based library that allows us to take care of common particle operations in a way that we don’t have to worry about because the library, for the most part, is doing this optimization work. And these are just operations that typically appear in particle codes like sorting particles, transferring particles, between different MPI ranks. That has been very useful having those libraries so that we don’t have to worry about what’s on CUDA, what’s on OpenMP or HIP.
A lot of refactoring has had to happen. We needed a much more object-oriented code than we had a couple of years ago, and so that has been an ongoing project that has continually been giving us performance benefits and just structural benefits, easier debugging, so it’s been really paying off even in the meantime.
A big design decision that we had to make at XGC was whether to stay in Fortran or to convert our code into C++, and, in the end, we did decide to convert, partly because we are using Kokkos and Cabana, which are C++ libraries, and in order to make sure that we were able to use them to their full ability, we thought it would be best to start converting. But also, in general, C++ seems to have stronger and earlier support as well as more mature capabilities for templates and other features that we really need to get good performance on these new machines.
And we’d always have to be asking what’s going to be supported. If we were to use Fortran, then we may need to use an OpenMP back end only, and it’s not guaranteed that we will always have peak performance with Fortran with the specific back end. So those are the main decisions that we had to be making.
Germaschewski: As Bryce had mentioned, we started out using CUDA directly, and that was a good way to get us started. But CUDA is rather mature, but it’s also very low level and very hardware specific. So, it’s not too surprising that as we went on, we encountered limitations and our approach had to evolve.
One reason is that the upcoming exascale machines are going to feature AMD and Intel GPUs, and in the case of AMD, it’s pretty straightforward to make CUDA kernels work on AMD GPUs using the HIP portability wrappers. But Intel’s SYCL GPU API is significantly different, and that’s one reason why we had to change our approach.
Another reason is that GENE is a grid-based code using finite-differences/finite-volumes, so in the end it uses a lot of stencil computations for the various terms in the gyrokinetic equations. And so, what that meant is that actually that’s not like one or two or three kernels that we could focus on, but there’s like dozens of kernels that go into evolving the right-hand side and having to handle so many kernels means handwriting everything in detail is a lot of work and also not very maintainable. The other part of that is memory.
We chose managed memory to avoid having to deal with explicitly having to move memory back and forth, so, basically, the hardware would do it for us depending on where we access the memory. And that was a good way to work initially because it allows to port one kernel at a time and focus on the kernels and not having to worry about who else may be accessing the memory at a later time. But it does not get rid of the memory transfers—they’re still there. And, as I said, there are many kernels that are relatively simple, so they’re also pretty fast. And the memory transfer times are very significant.
So in order to get the real benefit of GPU acceleration, what we do need is to have basically the entire calculation of the right-hand side on the GPU, and, again, that means there’s lots of kernels to port. That’s why we evolved our approach into something that would be specific to what GENE needs but still pretty flexible, simple, and maintainable to use and also be portable across the different hardware architectures.
Gibson: Please describe for us how you’re addressing performance portability challenges.
Scheinberg: Performance portability has been integral to this entire transition. So Kokkos and Cabana—these libraries that we’re using—have really helped us along with that. In addition to controlling and managing how kernels are sent to the GPU, they also allow us to change memory layout—to experiment with memory layout very readily. Although for the most part the libraries are taking care of the performance portability, we’re also able to address, maybe, issues that are specific to us.
Another challenge for us is that we are trying to maintain portability also on CPUs and on ARM machines, and so we can’t just throw away everything from CPU and just think about GPUs. In terms of the general approach, we’re making sure that our code is being tested for accuracy and performance on all the different architectures that we intend to run production science on.
Germaschewski: For GENE, in past years we did look at various options, like how would we have the various kernels that we have, how would we handle them in a way that’s maintainable, that’s performance portable, and that works across different compilers? And so, we looked at OpenMP, OpenACC. We looked at the same portability frameworks too, like Kokkos and RAJA, and we experimented with some of them. In the end, we actually ended up settling on our own approach, and for our specific needs that worked out pretty well.
We implemented a C++ library we called gtensor. The idea is based on an existing library which is called xtensor, and that one adds numpy-style programming to C++ so you can do things like multidimensional array arithmetic, and you can do slicing and reductions, those kinds of things. It uses lazily evaluated expression templates, so, basically, we used template metaprogramming to turn the C++ compiler into a code generator that can actually generate efficient implementations of stencil computations on the fly as you compile your code. In gtensor, we took that idea and we extended it to generating GPU kernels; xtensor is a CPU-only solution at this time.
On the back end side, we support generating CUDA or HIP or SCYL kernels, and on the application side, really all we have to do is write numpy-style array expressions. So, they end up looking a bit uglier in C++ than in Python; the syntax has to be a bit different. But they pretty much do the same thing if one is familiar with numpy ones—able to understand those quite easily. They look the same, but they actually give us efficient GPU code in a performance-portable fashion.
Allen: One of the advantages of this approach that we found is that it makes fusing kernels very elegant because you can have these complex array expressions that may be in separate functions and compiled to separate kernels, and then you just make slight changes to the code and evaluate them as a single expression as a single kernel. And this can be important for GPU programming because, in particular for GENE, stencil calculations are typically memory bandwidth bound, which means getting the data to the computation units is the bottleneck rather than the max FLOP rate of the processor. So sometimes if you can combine operations and do more at once with the data, then you can increase what we call the arithmetic intensity of the operation.
We did an analysis on Summit for a specific kernel in GENE using the Roofline performance model. We fused what was three kernels into one. We had an x derivative calculation, a y derivative calculation, and then a third calculation that takes those calculated derivatives and updates the right-hand side of the equation. Combining those into a single kernel instead of executing them separately gave us roughly twice as fast performance. So, we were quite pleased with how gtensor simplified that workflow.
Another issue for performance portability for GENE is that it makes use of FFTs, some BLAS operations, and an LU solver. The GPU vendors have their own libraries for each of these, but they each have slight differences. And there isn’t really a well-established wrapper library. As an extension to gtensor, we implemented wrappers around these. For example, for FFT, there’s CUFFT for CUDA. There’s rocFFT for AMD GPUs. And then there’s oneAPI MKL for Intel GPUs.
Our library provides a uniform interface across all of the GPU vendors and provides some convenience methods for using gtensor objects with them, because those libraries tend to be very low-level C-style libraries.
Gibson: What are you doing to prepare for Argonne’s Aurora system?
Scheinberg: We’re refactoring the code. We’re moving it into C++. We’re offloading the kernels. There’s a lot of work to do that is in progress. And specifically on Aurora, we have the Aurora test bed systems available, and we have been running our codes, testing them, doing some basic performance analysis, and submitting bug reports, as Bryce has said. It’s new compilers, and everything is under development at the same time; and there are bugs.
Allen: For GENE, we ported gtensor to Intel SYCL [DPC++] very early on as their tool chain became available, and even before test systems were available, it was working on Gen9 integrated GPUs, which are available on many laptops. So that was another thing that worked out well with our approach. Gtensor is a relatively narrow-scope library, and it was fairly easy for us to get that working quickly without waiting for a more complex library to do the porting process.
There are a few aspects of gtensor that we’re still working on. In particular, the multi-GPU support in gtensor follows the CUDA and HIP model of using indexes to indicate which GPU on the system you want to use. To get that to work with Intel SYCL [DPC++] requires some clever programming. That’s one thing that we’re still working on.
Another aspect that is often not talked about but is especially an issue with GENE where it has multiple languages—Fortran and C++—is updating your build system to work with new compilers and dealing with how they may have different command line switches for different options. And tools like CMake can help with this, but they don’t magically make the problem simple. We’re still working on that for GENE. The other thing is that we still have some kernels that are written in CUDA and HIP that need to be ported to gtensor. That work is ongoing.
Gibson: What are the next steps in your preparations for exascale?
Scheinberg: Our campaign to offload all of our kernels that are computationally expensive onto GPU is wrapping up now, and we’re starting to move more into looking at communication: internode communication between the different MPI ranks as well as host-device communication and looking at ways to optimize that and also keep it flexible, as I’ve said. There are different algorithms that get used in XGC that may not be required if there is sufficient memory on the GPU, for example.
Really, depending on the specifics of the machine, that might change the sorts of communication algorithms that we use. So, we’re trying to keep things flexible and also wait and see for the final configurations on all these different exascale machines.
Allen: For GENE, the Spock test system at OLCF [Oak Ridge Leadership Computing Facility] is a test system for Frontier that recently became available. So we’ve been working on getting GENE to run on Spock. And also, for the AMD platform in general, we ran into performance issues with managed memory, so we’re into work with AMD and Cray on that to figure out the best path forward for GENE. As more Aurora test systems come online, we will be doing the same for them and for all of these systems doing performance profiling to see where we need to improve.
Another aspect similar to what Aaron was saying is the MPI communication. For GENE, our CUDA port is in pretty good shape right now and it runs very efficiently on a single node on Summit, for example, and on a moderate number of nodes it runs very well. But as we try to scale to thousands of nodes, the MPI communication really becomes a bottleneck, and this is, in many ways, a much harder problem to solve than optimizing GPU kernels for a single node. So that’s something that we need to explore more in the future.
And another interesting aspect is collaborating with other projects. One we have just started is . . . There’s this library called Bricks, which does stencil computations in a flexible way. We are collaborating with them to see if they can help us improve the performance of stencil calculations in GENE, which it really is a significant portion of the kernels.
Gibson: Tim, let’s wrap up by having you share best practices, lessons learned, and advice that may help researchers in getting their codes ready for GPU-accelerated exascale systems.
Williams: If you think about all the detailed development work that you’ve heard about from Aaron and from Bryce and Kai, we think you can definitely abstract some broader lessons and approaches.
One of those is that, first, you should consider GPU acceleration generically. If you haven’t already implemented your code for GPU acceleration, you may find that parts of it need to be refactored or you may need to choose a different algorithm for parts. This kind of work you can do with today’s production GPU-accelerated systems, and you should.
Second, you should identify a portability strategy that’s appropriate for all of the CPU–GPU systems you see on the horizon for your application. This means, for example, in the CPU space considering Intel, AMD, and Arm CPUs. In the GPU space, considering Intel, AMD, and NVIDIA GPUs.
Next, it’s worth considering high-level portability layers. As an example, by using Kokkos in XGC, if you look at the difference in the Intel versus AMD versus NVIDIA GPU-accelerated versions, it’s really just a couple of lines of code. And, similarly, GENE, for example, has adopted and implemented its own high-level portability layer, the [gtensor] library.
From that point, you should start doing work with the closest previous-generation GPU accelerators to what you have coming in the exascale system or whatever you’re targeting next. Along with that, you should if you can, start using the alpha and beta developer software for those systems. In our case, we’re using those for the exascale systems. So, programs like ECP and ESP provide access to those software development kits, but outside of those you can, for example, go out if you’re targeting Intel GPUs and download the oneAPI public beta software.
If you’ve chosen a portability layer, then you should try to work with developers at that layer if it’s not your own team. For example, the XGC developers have been working with the Kokkos and Cabana development teams that are targeting the exascale systems.
Now, when it comes to optimization, one of our main takeaways is do not optimize prematurely. Focus on functionality and correctness and portability first. Keep in mind that if you’re using this alpha or beta early software, it may not optimize the same way—and certainly not as well—as it will eventually when it becomes mature. Likewise, the previous-generation hardware that you’re using or any early-release hardware that you’re using, may have some significant or meaningful differences in performance with respect to what will land on the exascale system. Not just that the hardware on the exascale system will be faster or improved in performance, but there may be some differences that imply a different optimization approach or different choice of parameters for optimization.
And one more point on this thread . . . When you do profile your application and start looking at optimizing parts of it, make sure that you use a physically realistic problem representative of what you intend to run on the real system so that you are correctly focusing on what will be important to optimize on the exascale system.
Looking towards what needs to happen between now and the delivery of the exascale systems and running the science cases we have planned for this application, we’ll be looking at starting to test the coupling of the codes together and doing that on the new hardware, looking at how the different programming models within the different applications that are coupled together that you’ve heard about integrate. And final considerations such as I/O, which of course becomes immediately important upon running a real science case. For example, for the Aurora system, we’ll want to consider the effects of using its DAOS object store I/O system.
Gibson: This has been quite informative. Thank you all very much.
Williams: Thank you for having us.
Related Links
Porting a particle-in-cell code to exascale architectures—article by Nils Heinonen, Argonne Leadership Computing Facility
Whole Device Model Application (WDMapp) project description
Co-design Center for Particle Applications (CoPA) project description