A team funded by the Exascale Computing Project (ECP) have ported and scaled WarpX, a particle-in-cell (PIC) code for solving the motion of relativistic, charged particles in the presence of electromagnetic fields, to GPU-based supercomputers such as Summit and the upcoming Aurora and Frontier machines. Their work addresses limitations including the use of Fortran kernels for PIC operations such as current deposition, field gathering and particle pushers and field solvers. Additionally, hand-optimization to specific architectures had led to a lack of portability. The researchers ported the PIC kernels from Fortran to C++ and developed a framework wherein CUDA, HIP, or DPC++ is used to offload kernels, depending on the computing platform (e.g., NVIDIA, AMD, Intel). This advancement removes the need for mixed-language programming, which adds substantial complication and often overrides compiler optimizations, and offers a relatively consistent programming model across platforms. The researchers’ work was published in the September 2021 ECP special issue of Parallel Computing.
WarpX can be used for a variety of applications in plasma physics. The ultimate goal is for WarpX to aid in the design of smaller, less-expensive particle accelerators based on wakefield acceleration. This would impact the US Department of Energy’s (DOE’s) discovery science mission while resulting in a range of benefits to society including industrial, environmental, and medical applications. Because all the DOE supercomputers are now GPU-based, porting WarpX to GPU platforms was crucial and entailed refactoring, reimplementing, and rethinking many core algorithms.
The researchers have achieved a more than 100× improvement over their pre-ECP baseline on CPU machines. Pointing to the importance of optimized memory footprint, minimized kernel launch latency, and properly utilized memory hierarchy, the team expects their optimizations to generalize to other accelerator architectures as well as transfer to CPU-based machines. They provide lessons learned to others working on porting other CPU-based codes to exascale computers. Methods developed during this work, including particle sorting to improve cache-reuse in particle-mesh operations, memory pools to reduce the overhead associated with device memory allocation, and fusing kernels to minimize the overhead associated with GPU kernel launch latency, are all likely to be useful for other simulation codes, both inside and outside the PIC community. Current and future work involves further optimization of the current deposition and parallel communication routines, as well as improvements for non-NVIDIA GPUs.
A. Myers, A. Almgren, L.D. Amorim, J. Bell, L. Fedeli, L. Ge, K. Gott, D.P. Grote, M. Hogan, A. Huebl, R. Jambunathan, R. Lehe, C. Ng, M. Rowan, O. Shapoval, M. Thévenet, J.-L. Vay, H. Vincenti, E. Yang, N. Zaïm, W. Zhang, Y. Zhao, and E. Zoni. “Porting WarpX to GPU-Accelerated Platforms.” 2021. Parallel Computing (September).
https://doi.org/10.1016/j.parco.2021.102833
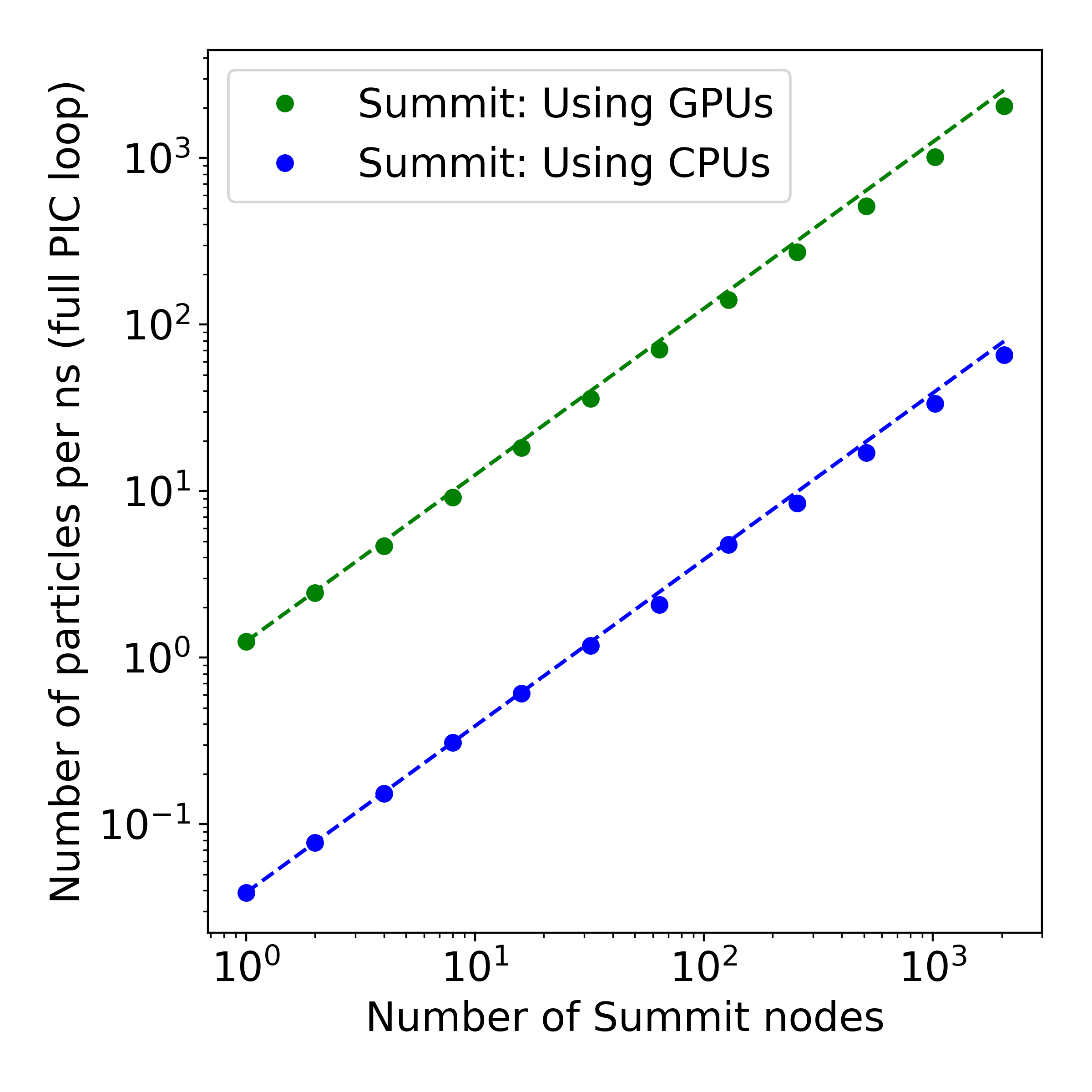
Results of a weak scaling study on a uniform plasma setup on Summit. The x-axis shows the number of Summit nodes, while the y-axis shows the number of particle advances per nanosecond. Both the CPU and GPU versions of the code scale well, and the overall speedup associated with using the accelerators is ∼30.