By Rob Farber, contributing writer
Lower-upper (LU) factorization is an important numerical algorithm used to solve systems of linear equations in science and engineering.[1] These linear systems of equations can be expressed as a matrix, which is then passed to a solver to find the solution to Ax = b. Dense matrices, in which a value is stored in memory for every matrix location, quickly impose limits on the problem size that can be solved on the target computer due to memory limitations. For example, a 1 million by 1 million matrix would have 1 trillion elements. The primary benefit of large systems of equations is that sparse matrices can be used to represent the system of equations without the n × n memory storage requirement, where n is the number of elements in the rows and columns of a square matrix. In Big-O nomenclature, this is expressed as O(n2). Sparse matrices avoid the impractical need to store every value in the matrix, especially zero values, in the computer memory. Bypassing the memory limitation gives scientists and engineers the ability to work with and solve large systems of linear equations.
The SuperLU library is a well-known, well-established library that scientists and engineers use to directly solve general unsymmetric sparse linear systems.[2] In a recent 2020 Exascale Computing Project (ECP) presentation, the SuperLU team noted that its library can solve a typical set of 3D partial differential equations by using O(n2) flop/s and O(n4/3) memory. Also, the SuperLU library provides error analysis, error bounds, and condition number estimates.[3] The condition number of a matrix measures how much the output value of the function can change for a small change in the input argument. With these measures, the SuperLU library provides scientists with important information about the robustness of their numerical solution in the face of noise and/or measurement error in the system being studied.
New approaches for new hardware architectures
In a June 2020 overview of direct solvers on the National Energy Research Scientific Computing Center website, Dr. Xiaoye S. “Sherry” Li, a senior scientist and group lead at Lawrence Berkeley National Laboratory, wrote that, “In the past 10 years, many new algorithms and software products have emerged which exploit new architectural features, such as memory hierarchy and parallelism.”[4] As part of the ECP, Li has worked with the SuperLU team to incorporate new algorithms and software approaches into its library to exploit these new hardware capabilities. Many of these new hardware devices will be used in the nation’s forthcoming generation of exascale supercomputers.
On evaluating their most recent GPU code to solve a sparse triangular matrix, Li observes, “Our triangular solver is on average 5.5× faster than NVIDIA’s cuSPARSE. For a matrix from the ExaSGD ECP application, our new triangular solver on a single GPU is faster than seven CPU cores on Summit. This will greatly improve the GPU capability of the applications that use SuperLU as a preconditioner.” Portability is another benefit of the SuperLU library as compared with the vendor- and GPU-specific NVIDIA cuSPARSE library.
Our triangular solver is on average 5.5× faster than NVIDIA’s cuSPARSE. For a matrix from the ExaSGD ECP application, our new triangular solver on single GPU is faster than seven CPU cores on Summit.—Sherry Li, senior scientist and group lead at Lawrence Berkeley National Laboratory
The GPU results for the SpTRSV (Sparse Triangular Solve) GPU function are shown in Figure 1.
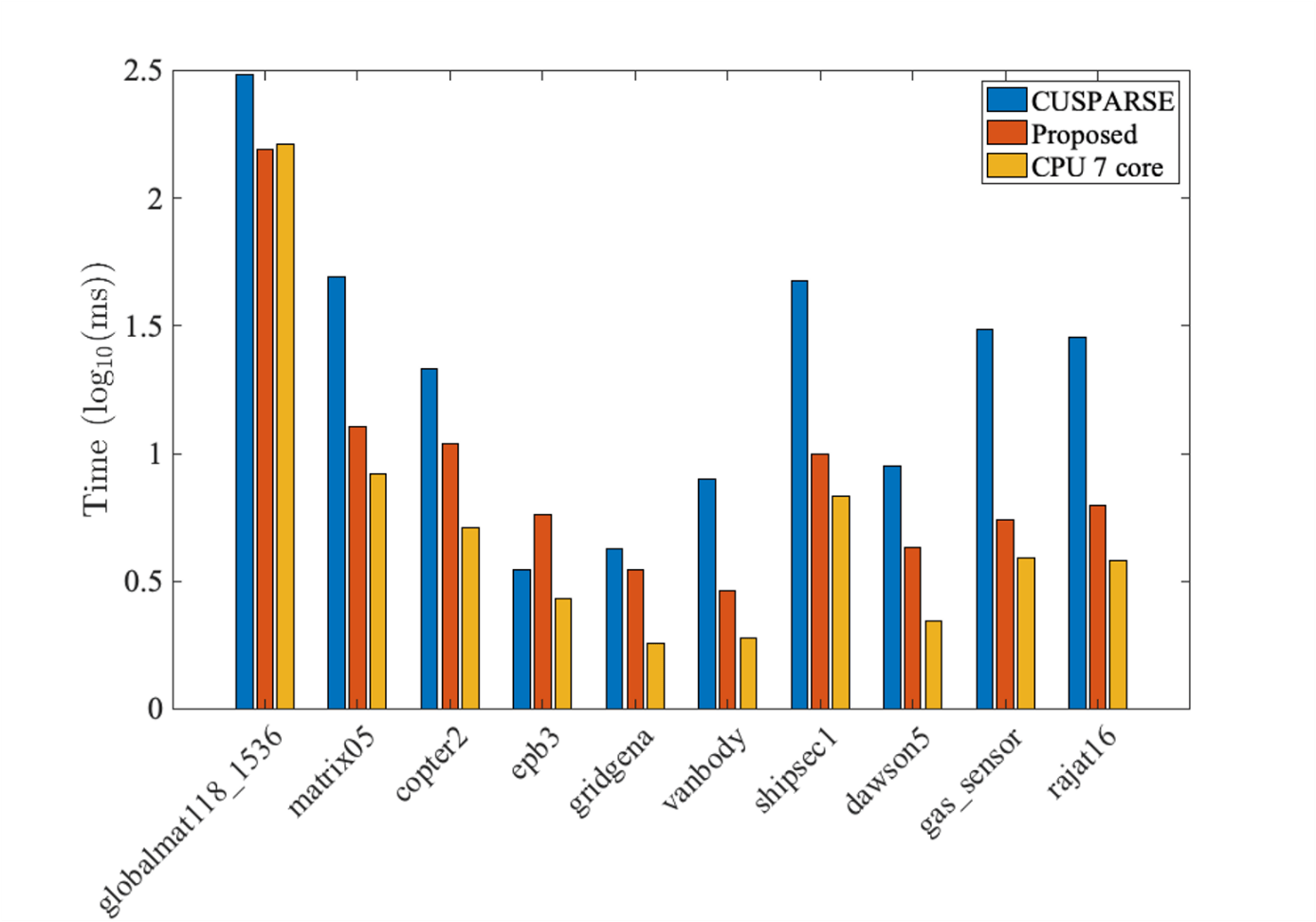
Figure 1: Comparative GPU results for SpTRSV. (Source https://ecpannualmeeting.com/assets/overview/posters/SuperLU-poster-2020.pdf.)
On solving sparse linear systems in a distributed computing environment, Li notes, “The team also improved the asynchronous algorithm in [a] parallel triangular solve using [a] 3D MPI process organization, achieving a 7× speedup over the earlier algorithm on 12,000 cores.” This speedup was achieved by observing that there was some data replication in 1D, specifically in the Z-dimension. The team exploited this replication to eliminate some communications overhead at the expense of consuming more memory. Furthermore, the team also used one-sided communications, which “enjoy higher effective network bandwidth and lower synchronization costs compared with two-sided communications.”[5] Details on the algorithm are found in the 2019 article, “A Communication-Avoiding 3D Sparse Triangular Solver.”
The team also improved the asynchronous algorithm in [a] parallel triangular solve using [a] one-sided MPI communication scheme, achieving a 2× speedup over the earlier algorithm on 12,000 cores.—Sherry Li
Summary
The SuperLU team has been developing new parallelization strategies that run faster on new accelerated systems, such as those based on GPUs and new computational approaches, to reduce inter-process communications and speed up computations in distributed computing environments. Both approaches are important for creating a portable, performant library for the ECP and high-performance computing (HPC) communities. Given how important sparse solvers are to scientists and engineers, these additions to the SuperLU library will be very helpful in advancing the state of the art in scientific computing on the forthcoming generation of exascale supercomputers.
Li also notes that the team is currently collaborating with ECP application teams for the application-specific and hardware-specific tuning of the parameters space to achieve optimal efficiency of their solvers. The team is also working to integrate its solvers into the higher level algebraic solvers in the extreme-scale scientific software stack (xSDK), such as hypre, PETSc, SUNDIALS, and Trilinos.
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national laboratories and commercial organizations. Rob can be reached at [email protected].
[1]https://www.researchgate.net/publication/261702679_Achieving_Numerical_Accuracy_and_High_Performance_using_Recursive_Tile_LU_Factorization
[2]https://github.com/xiaoyeli/superlu_dist/blob/master/DOC/ug.pdf
[3]https://ecpannualmeeting.com/assets/overview/posters/SuperLU-poster-2020.pdf
[4]https://portal.nersc.gov/project/sparse/superlu/SparseDirectSurvey.pdf
[5]https://ecpannualmeeting.com/assets/overview/posters/SuperLU-poster-2020.pdf