By Rob Farber, contributing writer
HeFFTe (highly efficient FFTs for Exascale, pronounced “hefty”) enables multinode and GPU-based multidimensional fast Fourier transform (FFT) capabilities in single- and double-precision.[1] Multidimensional FFTs can be implemented as a sequence of low-dimensional FFT operations in which the overall scalability is excellent (linear) when running in large node count instances. Considered to be one of the top 10 algorithms of the 20th century, the FFT is widely used by the scientific and high-performance computing (HPC) communities. Over the years, this demand has stimulated the development of many excellent FFT implementations.
Stan Tomov, the Research Director in the Innovative Computing Laboratory (ICL) at the University of Tennessee, distinguishes heFFTe from other FFT implementations: “HeFFTe provides high performance and scalability to support even exascale platforms. It has the flexibility to target many applications as we collected the functionalities of existing projects (including when the starting data is real, complex to real, discrete cosine transform, discrete sine, convolutions, etc.) and incorporated them into a sustainable library. With so many projects, sustainability is important, which is why heFFTe uses Spack integration for portability along with validation suites to ensure performance and correctness.” Excellent scalability, along with portability and performant behavior on CPUs and GPUs, makes heFFTe a valuable addition to the Exascale Computing Project (ECP) software stack for exascale systems.
HeFFTe provides high performance and scalability to support even exascale platforms. It has the flexibility to target many applications as we collected the functionalities of existing projects (including when the starting data is real, complex to real, discrete cosine transform, discrete sine, convolutions, etc.) and incorporated them into a sustainable library. With so many projects, sustainability is important, which is why heFFTe uses Spack integration for portability along with validation suites to ensure performance and correctness. — Stan Tomov, ICL Research Director at the University of Tennessee
Jack Dongarra, an Industry Luminary and American University Distinguished Professor of computer science in the Electrical Engineering and Computer Science Department at the University of Tennessee, explains the excellent scaling by noting that, “HeFFTe reduces FFT to a communications problem.”
HeFFTe reduces FFT to a communications problem. — Jack Dongarra, Industry Luminary and American University Distinguished Professor of computer science in the Electrical Engineering and Computer Science Department at the University of Tennessee
Overcoming the Limitations of Existing FFT Packages
As part of the ECP, the heFFTe overview notes: “The current state-of-the-art FFT libraries are not scalable on large heterogeneous machines with many nodes or even on one node with multiple high-performance GPUs (e.g., several NVIDIA V100 GPUs). Furthermore, these libraries require large FFTs to deliver acceptable performance on one GPU. Efforts to simply enhance classical and existing FFT packages with optimization tools and techniques—like autotuning and code generation—have so far not been able to provide the efficient, high-performance FFT library capable of harnessing the power of supercomputers with heterogeneous GPU-accelerated nodes.” [2]
Figure 1, which contains a profile of a 3D FFT of size 1,024 × 1,024 × 1,024 running on four Summit nodes using CPUs (left) vs. GPUs (right), shows an overall 2× speedup of the multidimensional FFT when using GPUs. Although there is a 43× increase in GPU kernel performance, communication time is unchanged and becomes dominant for the overall computation, illustrating the communications’ limited nature of the FFT computation as described by Dongarra.
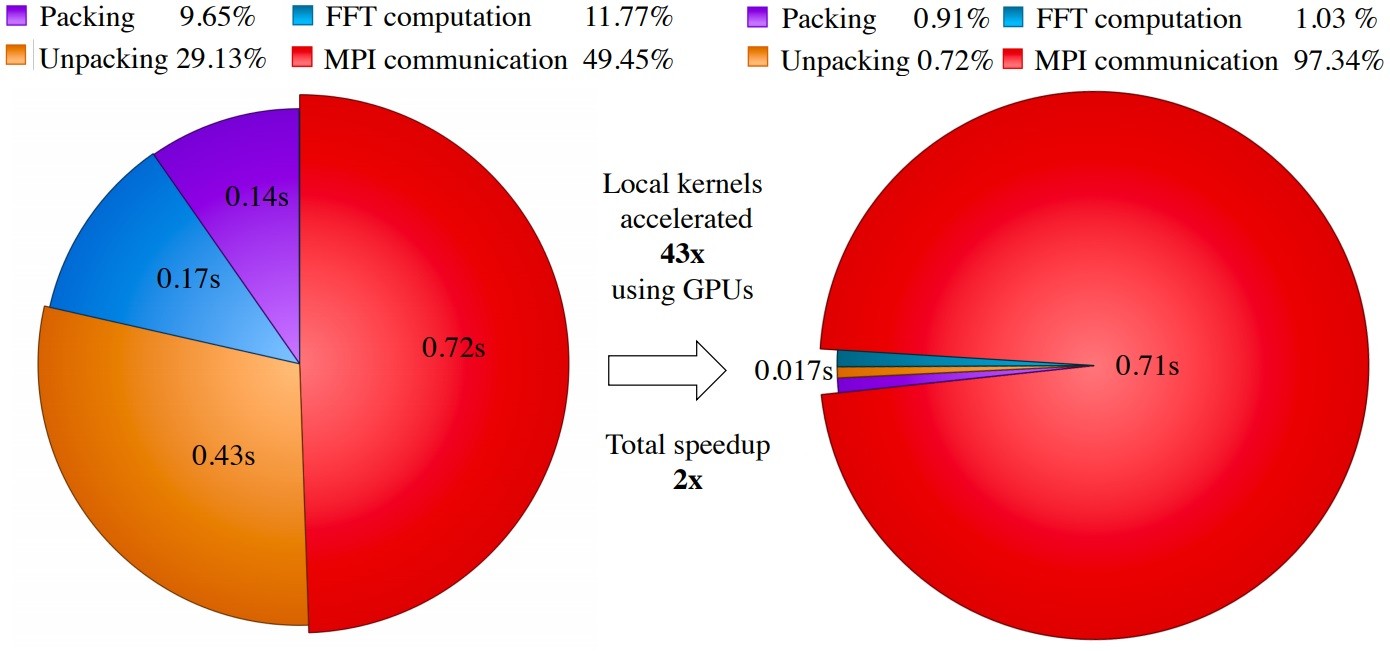
Figure 1: FFT of size 1,024 × 1,024 × 1,024 on four nodes, 32 MPIs per nodes (CPU kernels, left) vs. 24 MPI processes, six MPIs (six Volta100 GPUs) per node (GPU kernels, right). (Source: https://ecpannualmeeting.com/assets/overview/posters/2020_ECP_Meeting_Poster_heFFTe.pdf).
Addressing the Communication Bottleneck
It is well-known that distributed parallel FFT computation is communication-bounded and that hardware limitations significantly impact performance.[3]
To help achieve the highest possible performance, heFFTe gives users control over the processor grid at each stage. Performance tuning is also possible via heffte_alltoall, which can be tuned to perform all-to-all communication, by using nonblocking CUDA-Aware message passing interface (MPI) and IPC CUDA memory handlers.
HeFFTe Exhibits Good Strong and Weak Scalability
In Figure 2, the scalability results (left graph) and weak scalability comparison (right graph) for a 1,024 FFT illustrate the effectively linear scaling behavior on the Summit pre-exascale supercomputer.
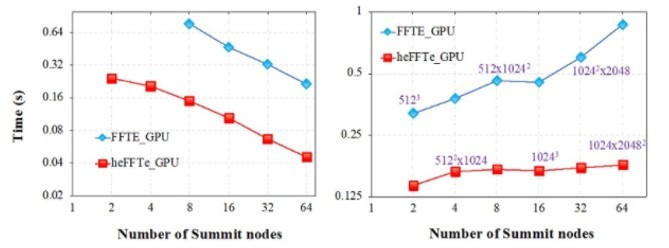
Figure 2: Strong (left) and weak (right) scalability. We use 24 MPIs per node on each case, one MPI per core for heFFTe CPU, and four MPIs per GPU-Volta100 for heFFTe GPU. (Source: https://ecpannualmeeting.com/assets/overview/posters/2020_ECP_Meeting_Poster_heFFTe.pdf.)
The local CPU kernels presented in this benchmark are typical of state-of-the-art parallel FFT libraries. HeFFTe also provides new GPU kernels for these tasks, which deliver an over 40× speedup vs. CPUs.
HeFFTe Has Wide Applicability
By the broad applicability of multidimensional FFTs, heFFTe can be used in many domain applications, including molecular dynamics, spectrum estimation, fast convolution and correlation, signal modulation, and wireless multimedia applications.
Tomov points out that heFFTe is used by many—arguably most—ECP projects. In one survey, the heFFT team found that more than a dozen ECP applications use FFT in their codes.[4] Even with the current wide acceptance, Tomov notes that the heFFTe team is looking forward to integrating with even more projects—both ECP and non-ECP—in the future.
Concrete Use Cases Abound
The block schematic in Figure 3 shows how several ECP applications interface with heFFTe.
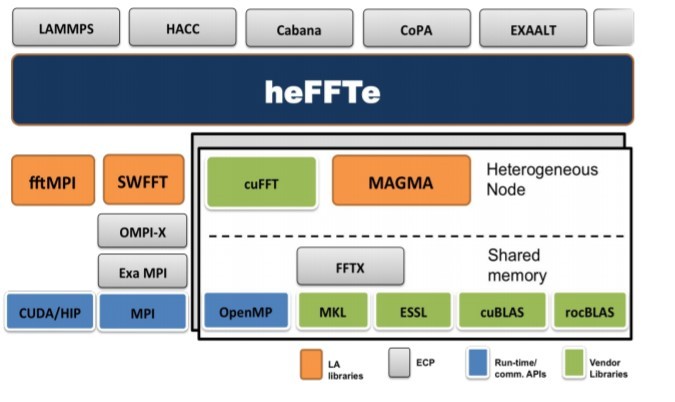
Figure 3: HeFFTe in the ECP software stack. (Source: https://ecpannualmeeting.com/assets/overview/posters/2020_ECP_Meeting_Poster_heFFTe.pdf.)
Unsurprisingly, given the performance dependence on the distributed FFT, applications such as LAMMPS have created their own FFT library (FFTMPI, in this case). To prove its worth, the heFFTe library needs to deliver better performance than the existing FFT implementation.
For LAMMPs, the heFFTe team provided wrappers to directly call heFFTe. Benchmark results on the LAMMPS Rhodopsin protein benchmark (Figure 4) show that heFFTe caused a 1.5× increase in overall LAMMPS performance. In doing so, heFFTe ran 2× faster than the LAMMPS FFT library on a 128 × 128 × 128 FFT grid running across two nodes that used four MPI ranks per node.
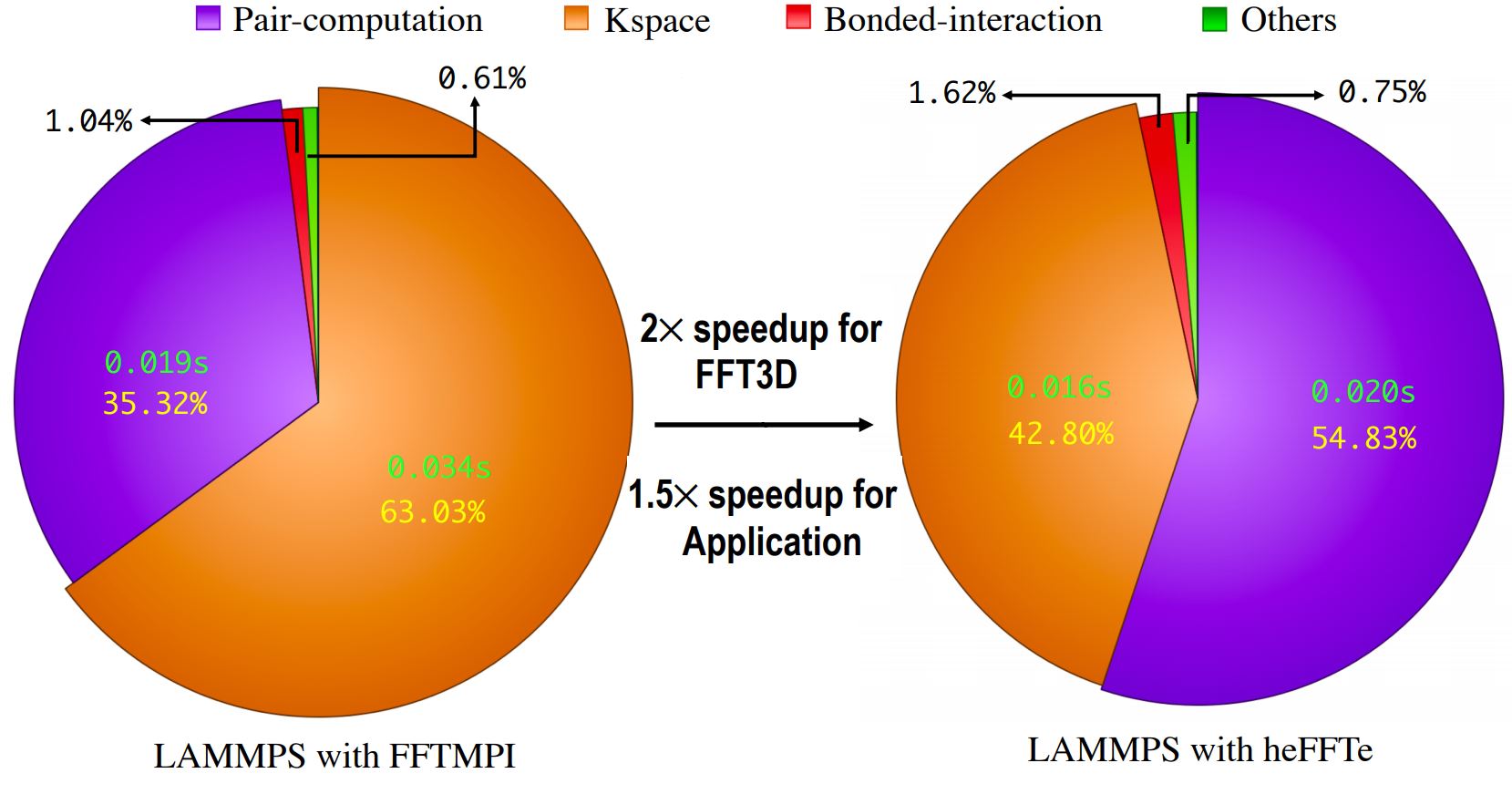
Figure 4: Rhodopsin protein benchmark for the LAMMPS package on two nodes and four MPI ranks per node on a 128 × 128 × 128 FFT grid. The pie chart on the left shows where time was spent using LAMMPS with FFTMP. The pie chart on the right shows the gains in performance in LAMMPS when using the heFFTe wrapper. (Source: https://www.icl.utk.edu/files/publications/2019/icl-utk-1263-2019.pdf.)
Looking to the Future
HeFFTe can be used via a variety of E4S containers (e.g., Docker, Singularity) and numerous SPACK builds for various CPU and operating system types, which can be quickly accessed via the binary cache. Users can download and build from source from bitbucket.
Looking to the future, Tomov notes some topics that are under consideration:
- integrating with more projects, and
- understanding the performance implications of numerical compression and decompression on heFFTe performance. Hardware mixed precision capabilities might also help with compression. For more information, see https://computing.llnl.gov/projects/floating-point-compression and https://www.exascaleproject.org/the-ez-project-focuses-on-providing-fast-effective-exascale-lossy-compression-for-scientific-data/.
Rob Farber is a global technology consultant and author with an extensive background in HPC and developing machine learning technology that he applies at national laboratories and commercial organizations. Rob can be reached at [email protected]
[1] https://ecpannualmeeting.com/assets/overview/posters/2020_ECP_Meeting_Poster_heFFTe.pdf
[3] https://www.icl.utk.edu/publications/impacts-multi-gpu-mpi-collective-communications-large-fft-computation