By Rob Farber, contributing writer
Performance, portability, and broad functionality are all key features of the AMReX software framework, which was developed by researchers at Lawrence Berkeley National Laboratory (Berkeley Lab), the National Renewable Energy Laboratory, and Argonne National Laboratory as part of the US Department of Energy’s (DOE’s) Exascale Computing Project (ECP) AMReX Co-Design Center.[1],[2]
The ECP AMReX Co-Design Center ensures that this popular and heavily utilized software framework for massively parallel, block-structured adaptive mesh refinement (AMR) applications can run efficiently on DOE supercomputers. Numerous ECP applications utilize AMReX to model a broad range of different applications, including accelerator design, astrophysics, combustion, cosmology, multiphase flow, and wind energy.[3]
To address such a broad range of physical phenomena, the software must support a wide range of algorithmic requirements. As noted in “A Survey of Software Implementations Used by Application Codes in the Exascale Computing Project,” AMReX achieves this platform portability through its APIs. Other ECP co-design centers such as the Center for Efficient Exascale Discretizations (CEED) and Co-design Center for Particle Applications also utilize this same approach to deliver performance portability.[4]
From CPUs to Heterogeneous Architectures
AMReX was originally based on the earlier BoxLib framework, which was used to develop AMR applications.[5] John Bell (Figure 1), principal investigator of the AMReX Co-Design Center and a senior scientist in the Applied Mathematics and Computational Research division at Berkeley Lab, explained, “ECP funding allowed us to completely redesign BoxLib, which was designed for CPU-only systems, to create AMReX, which provides a performance-portable framework that supports both multicore CPUs and a number of different GPU accelerators. AMReX is currently used by a diverse set of applications on many different systems.” For those application codes that were already based on BoxLib, the AMReX team documented how to migrate their codes from BoxLib to AMReX. (This documentation is available in the AMReX repository at Docs/Migration.[6])

Figure 1. John Bell
Along with GPU acceleration, Bell noted, “One of the key design features of AMReX is that it separates the basic data structures and core operations on those data structures from the algorithms used by a particular application, providing developers a lot more flexibility in how to solve their problems.”
ECP funding allowed us to completely redesign BoxLib, which was designed for CPU-only systems, to create AMReX, which provides a performance-portable framework that supports both multicore CPUs and a number of different GPU accelerators. AMReX is currently used by a diverse set of applications on many different systems. One of the key design features of AMReX is that it separates the basic data structures and core operations on those data structures from the algorithms used by a particular application, providing developers a lot more flexibility in how to solve their problems. — John Bell
Technology Introduction
Scientists use block-structured AMR as a “numerical microscope” for solving systems of partial differential equations (PDEs). AMReX provides a framework for developing algorithms to solve these systems, targeting machines ranging from laptops to exascale architectures both with and without GPU acceleration.
Scientists describe a wide range of physical phenomena using PDEs, which are relationships between derivatives of different quantities describing the system. The wind flowing over a mountain range, the vibration of a bridge during an earthquake, and the burning inside a supernova are all described by PDEs. Solving PDEs allows scientists to gain insight into the behavior of complex systems. However, in most cases, no easy mathematical solution to a system of PDEs exists. Instead, they must be solved using a computer. Central to solving PDEs on a computer is how the scientist represents the system. One common approach is to define the state of the system in terms of its values on a finite mesh of points. In this type of mesh-based approach, the finer the mesh (i.e., the more points it contains), the better the representation of the solution. AMR algorithms dynamically control the number and location of mesh points to minimize the computational cost while solving the problem with sufficient accuracy.
As noted in “AMReX: Block-Structured Adaptive Mesh Refinement for Multiphysics Applications,” block-structured AMR algorithms utilize a hierarchical representation of the solution at multiple levels of resolution (Figure 2). At each level, the solution is defined on the union of data containers at that resolution, each of which represents the solution over a logically rectangular subregion of the domain. This representation can be data defined on a mesh, particle data, or combinations of both. For mesh-based algorithms, AMReX supports a wide range of spatial and temporal discretizations. Support for solving linear systems includes native geometric multigrid solvers and the ability to link to external linear algebra software. For problems that include stiff systems of ordinary differential equations that represent single-point processes such as chemical kinetics or nucleosynthesis, AMReX provides an interface to ordinary differential equation solvers provided by SUNDIALS. AMReX also supports embedded boundary (cut cell) representations of complex geometries.
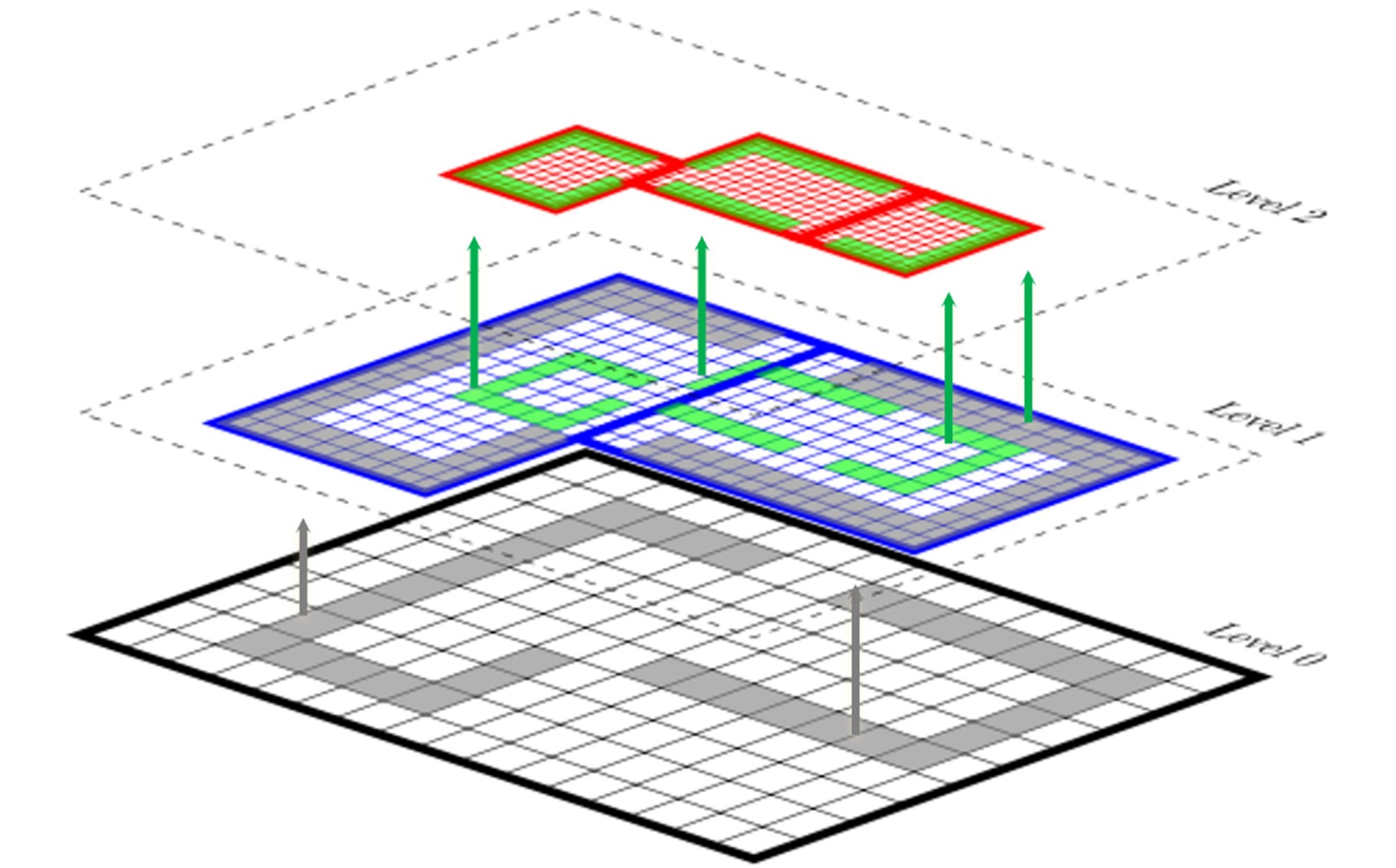
Figure 2. AMReX utilizes a hierarchical representation of the solution at multiple levels of resolution.
The Rationale for Block-Structured AMR Codes
Bell observed, “AMR differs from approaches such as the multigrid method that use a hierarchy of coarser grids to develop efficient algorithms to solve a problem at a fixed fine resolution. AMR represents the solution using a different resolution in different parts of the domain to focus computational effort where it is needed, such as at a shock wave or flame front.” The adaptive simulation of a burning dimethyl ether flame illustrates the ability to use finer resolution only where it is most needed (Figure 3).

Figure 3. Detailed adaptive simulation of a burning dimethyl ether jet. (Source: https://amrex-codes.github.io/amrex/gallery_images/DME_Jet.png)
{kind=link}
The code determines when and where more resolution is required based on user-provided criteria, which means that the mesh can be dynamically adapted during the simulation. The AMReX compressible gas dynamics tutorial illustrates how an embedded boundary representation can dynamically adapt the mesh resolution over both space and time (Figure 4). This and more complex 2D and 3D examples can be viewed at https://amrex-codes.github.io/amrex/gallery.html, which includes several animations shared with the AMReX team by researchers using AMReX-based codes to study a variety of phenomena.
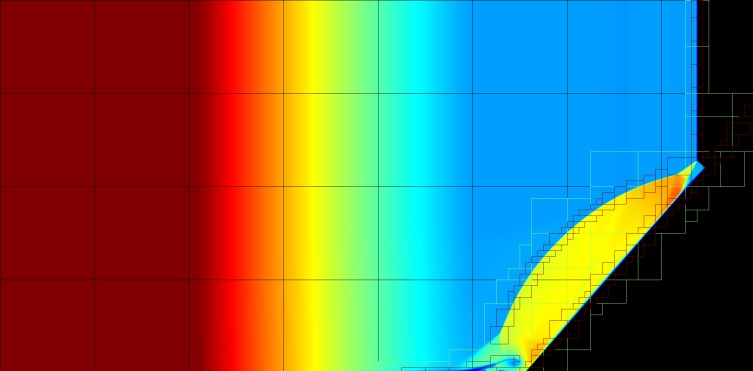
Figure 4. Compressible gas dynamics shock reflection using an embedded boundary representation of the ramp. The colors represent the density field. There are three total levels of refinement. (Source: https://amrex-codes.github.io/amrex/gallery_images/shockReflect.gif)
{kind=link}
GPU Acceleration
DOE exascale supercomputers are large, distributed architectures that rely on GPUs to achieve high performance. Bell observed, “Block-structured AMR algorithms have a natural hierarchical parallelism that makes them ideally suited to GPU-accelerated supercomputers. In an AMR algorithm, the representation of the solution is broken into large patches that can be distributed across the nodes of the machine. The operations on each patch occur on a large block of data that can be performed efficiently on a GPU.”
Operations on patches form the numerical core of AMR algorithms; however, efficient execution of supercomputers involves other considerations. Operating independently on patches does not lead to a full solution to the problem. The results on patches must be stitched together to form a complete solution. When advancing the solution for a single time step, each patch needs data from neighboring patches to move forward. After the solution on all the patches is advanced, the new solution on all the patches must be synchronized. Bell noted, “Synchronization operations reflect the underlying physical processes. For applications solving a relatively simple set of equations, the synchronization is fairly simple, but for large complex multiphysics applications, synchronization can be a complex multistage process.”
AMReX does a number of things “under the hood” to orchestrate the execution of AMR algorithms. At the start of a simulation and each time the adaptive algorithm changes the grid layout to reflect changing conditions, the data must be distributed across the nodes of a distributed computing architecture. The distribution must balance the computational work across the nodes while minimizing the cost of communication between nodes. Exchanging data between patches and synchronization operations requires efficient communication algorithms to minimize communication costs.
Using GPUs raises several other issues. Data migration between the GPU and its host CPU can be very expensive in terms of run time. AMReX provides tools to allow applications to manage memory that avoid unnecessary data movement. Additionally, no single programming model for GPUs exists. Each type has its own hardware characteristics and software environment. To address this issue, AMReX provides a lightweight abstraction layer that hides the details of a particular architecture from application code. This layer provides constructs that allow the user to specify the operations they want to perform on a block of data without specifying how those operations are carried out. AMReX then maps those operations onto the specific hardware at compile time so that the hardware is utilized effectively.
From a mathematical and computational perspective, Andrew Myers, computer systems engineer at Berkeley Lab and one of the AMReX lead developers, pointed out that “AMReX preserves many of the nice regular data access patterns as with a regular grid. This improves performance. It also makes the reasoning about the numerical method ‘easier‘ because the algorithm locally computes on a structured grid rather than a completely unstructured grid.”
For a more in-depth explanation, see “AMReX: Block-Structured Adaptive Mesh Refinement for Multiphysics Applications.”
Technology Drivers
Along with supporting the scientific need to model a broad range of physical processes—and the corresponding need for a general software framework that can support a wide range of algorithmic requirements—AMReX provides performance portability that is vendor agnostic and can run on both multicore CPU and GPU-accelerated supercomputers with different types of GPUs.
The Community Model and Cross-Fertilization with Other Projects
Such expansive requirements are too much for a single group, which highlights the benefits of the community model by enabling contributions and feedback from GitHub’s community of open-source developers and users. Cross-fertilization is also beneficial. According to Bell, AMReX developers are also embedded in other applications. Myers, for example, spends 50% of his time working on WarpX. Meyers noted, “AMReX supports numerous ECP and national laboratory applications. While the applications clearly benefit from being able to use AMReX, supporting a wide range of projects improves AMReX itself as well. We find there is significant beneficial cross-fertilization between different applications.”
The community model is integral to other high-profile numerical frameworks. See “The PETSc Community Is the Infrastructure” for another example.
Continuous Integration
AMReX is one package in the Extreme-scale Scientific Software Stack (E4S). E4S accelerates the development, deployment, and use of high-performance computing (HPC) software. This tool lowers the barriers for HPC users by providing containers and turnkey, from-source builds.[7] The E4S software components are tested regularly on a variety of platforms—from Linux clusters to leadership-class platforms. This testing ensures that the ECP software ecosystem at various DOE facilities runs correctly and performs as expected.
AMReX also uses continuous integration (CI), which is the practice of automating the integration of code changes from multiple contributors. CI is the path to the future for HPC because it creates a win-win situation for scientists, users, and systems management teams. Bell explained, “We perform CI on every request to merge new software into the base, which means that testing AMReX is very computationally intensive, especially as CI requires compiling and running a large suite using CUDA, HIP, and oneAPI along with testing compatibility with external libraries such as SENSEI and SUNDIALS.”
By using automation and allocating both people and machine resources, CI provides timely, well-tested, and verified software to users of the DOE Facilities, along with a more uniform and well-tested computing environment.
Documentation and Tutorials
The generality of AMReX can be daunting to the user, which highlights the importance of documentation and tutorials. Myers noted that these resources have been significantly improved with ECP funding. He noted, “Users are able to develop novel science applications using the tutorials without requiring outside assistance. ECP funding gave us the ability to create quality tutorials and documentation, which allows us to further expand the AMReX user community.”
Users are able to develop novel science applications using the tutorials without requiring outside assistance. ECP funding gave us the ability to create quality tutorials and documentation, which allows us to further expand the AMReX user community. — Andrew Myers
Investing in documentation and tutorials provides tremendous benefits to the global HPC community. Myers highlighted the Quokka two-moment radiation hydrodynamics code that was written from scratch using AMReX without needing support by the AMReX development team. The ECP CEED co-design center is another good example; its annual user meeting often includes people who leveraged CEED for their application without the CEED team even being aware (Figure 5).

Figure 5. A Kelvin-Helmholtz instability simulated with Quokka on a 512 × 512 uniform grid.
Previously Out-of-Reach Science Is Now Possible with Gordon Bell Prize–Winning Scalability and Performance
A 16-member team drawn from French, Japanese, and US institutions received the 2022 Association for Computing Machinery Gordon Bell Prize for their project, “Pushing the Frontier in the Design of Laser-Based Electron Accelerators with Groundbreaking Mesh-Refined Particle-in-Cell Simulations on Exascale-Class Supercomputers.”[8] To win the award, the team presented a first-of-its-kind mesh-refined (MR) massively parallel particle-in-cell (PIC) code for kinetic plasma simulations optimized on the Frontier, Fugaku, Summit, and Perlmutter supercomputers that was implemented in the WarpX PIC code.[9] The WarpX PIC code is built on the AMReX library.[10]
PIC simulation is a technique used to model the motion of charged particles in a plasma, as demonstrated in the Gordon Bell Prize–winning research. PIC has applications in many areas, including nuclear fusion, accelerators, space physics, and astrophysics.[11] Variations of PIC methods also exist for fluid and solid dynamics (some of which precede the application for plasma physics). One of these methods is the material point method (MPM) used in modeling additive manufacturing (AM) simulations. The ExaAM project is one example.[12] MPM was also used to model snow in the movie Frozen. Disney produced a video, “Practical Guide to Snow Simulation,” that described the use of physics models, solvers, and MPM in movies.
Major innovations implemented in the WarpX PIC code presented in the Gordon Bell Prize–winning paper included (1) a three-level parallelization strategy that demonstrated performance portability and scaling on millions of A64FX cores and tens of thousands of AMD and NVIDIA GPUs (Figure 6), (2) a groundbreaking mesh refinement capability that provided between 1.5× to 4× savings in computing requirements on the science case reported by the team, and (3) an efficient load-balancing strategy between multiple MR levels.[13] Bell noted that the GPU-capable parts of this performance strategy were the result of and optimized with ECP funding.
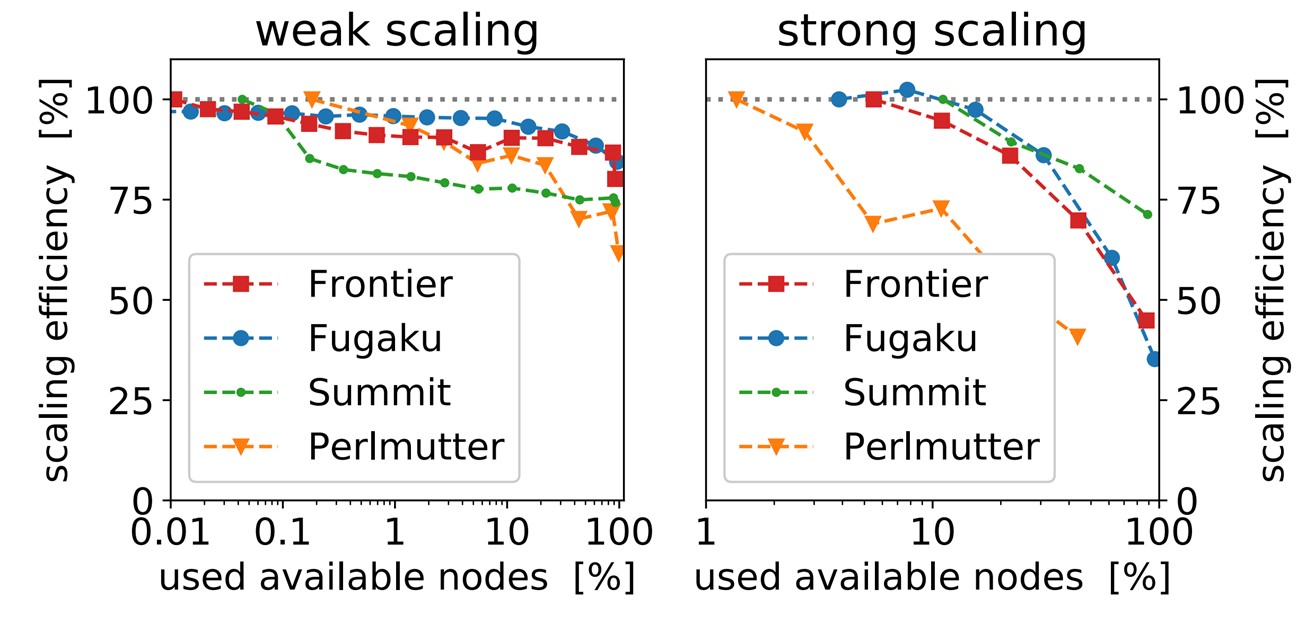
Figure 6. Weak and strong scaling of WarpX. Perfect scaling is the gray dotted line.
The performance and scalability of this PIC simulation code enabled 3D simulations of laser-matter interactions that were previously far outside the reach of standard PIC codes.[14] These simulations helped remove a major limitation of compact laser-based electron accelerators, which are promising candidates for next-generation high-energy physics experiments and ultrahigh dose rate FLASH radiotherapy.[15]
Portability through AMReX That Includes Intel GPUs
Recent performance results of AMReX codes were obtained for Intel GPUs using the Argonne Sunspot test bed. Sunspot is basically a miniature version of the Intel-based Aurora exascale supercomputer.[16] It provides teams a platform to optimize code performance on the actual Aurora hardware. Bell noted, “We finished the development of the AMReX SYCL backend for Intel GPUs and have ported and tested the entire AMReX test suite. It all ran correctly. We also ran WarpX and MFIX. The portability aspect is exciting. This work verified the efficacy of the AMReX performance-portable layer.” Intel adopted SYCL as an alternative to single-vendor proprietary accelerator programming languages. It enables code reuse across hardware targets (e.g., CPU, GPU, field-programmable gate array) and supports custom tuning for a specific platform. SYCL is a Khronos standard that adds data parallelism and heterogeneous programming to familiar and standard ISO C++.[17]
We finished the development of the AMReX SYCL backend for Intel GPUs and have ported and tested the entire AMReX test suite. It all ran correctly. We also ran WarpX and MFIX. The portability aspect is exciting. This work verified the efficacy of the AMReX performance-portable layer. — John Bell
The AMReX portability layer for GPU systems enhances user readability, GPU portability, and performance. This layer targets the native programming model for each GPU architecture: CUDA for NVIDIA, HIP for AMD, and DPC++ for Intel. The layer also gives AMReX immediate access to the newest features and performance gains without adding any additional overhead or dependencies.
In an AMReX case study, the National Energy Research Scientific Computing Center noted that the AMReX portability layer has been effective because it utilizes a flexible system of wrappers designed specifically for its users’ needs. AMReX includes well-designed loop iterators and specialized launch macros to achieve targeted, optimized performance that is maintainable by AMReX developers and understandable to AMReX users.[18] See the paper “AMReX: Block-Structured Adaptive Mesh Refinement for Multiphysics Applications” for more information about the portability layer.
Both SYCL and AMD HIP can be cross compiled to run on many different device types. The AMReX overview notes that currently AMReX does not support cross-native language compilation from HIP for non-AMD systems and SYCL for non-Intel systems. The team cautions that although this compilation may work with a given version, the AMReX developers do not track or guarantee such functionality.[19]
AMReX Is Helping the ECP, Industry, and the Global HPC Community
With ECP funding, the AMReX team developed an efficient GPU-capable portability layer. The success of WarpX in winning the 2022 Gordon Bell Prize competition clearly demonstrated the team’s success.
Along with WarpX, the AMReX library supports many other ECP projects (Figure 7).
Figure 7. AMReX has broad applicability.
Outside the ECP, Bell noted that AMReX is used in epidemiology, atmospheric modeling, and more. It represents a valuable resource for the global HPC scientific community. Examples include the following:
- ExaEpi: epidemiology modeling
- ERF (Energy Research and Forecasting): atmospheric modeling[20]
- ARTEMIS (Adaptive mesh Refinement Time-domain ElectrodynaMics Solver): microelectronics
- FHDeX: microfluidics and nanofluidics
- MAESTROeX: low Mach number astrophysics
- ROMS-X: a new version of the ROMS (Regional Ocean Modeling System) that will be performance portable
- BMX (Biological Modeling and interface eXchange): cell modeling
- Emu: neutrino quantum kinetics
- SedonaEX: a version of Sedona—a code base primarily focused on calculating the radiation signatures of supernovae and other transient phenomena in astrophysics—built on top of AMReX
Bell continued, “AMReX is helping industry in many ways. In many cases, industry is able to use the library with little or no help from us. As a consequence, we often don’t need to know what they are doing.” This point also illustrates the quality of the new ECP-funded AMReX documentation and supporting educational materials, as noted by Myers.
Summary
AMReX reflects an ECP success in moving an important numerical library to run on DOE GPU-accelerated supercomputers. The breadth of adoption reflects the importance of the community software development model to create libraries that support many types of science that can run on a variety of hardware platforms from laptops and the cloud to exascale supercomputers. Through the E4S CI framework, the platform generality and performance portability are verified to ensure correctness and performance on a variety of DOE hardware platforms.
This research was supported by the Exascale Computing Project (17-SC-20-SC), a joint project of the U.S. Department of Energy’s Office of Science and National Nuclear Security Administration, responsible for delivering a capable exascale ecosystem, including software, applications, and hardware technology, to support the nation’s exascale computing imperative.
Rob Farber is a global technology consultant and author with an extensive background in HPC machine learning technology.
[1] https://amrex-codes.github.io/amrex/
[2] https://journals.sagepub.com/doi/full/10.1177/10943420211022811
[3] https://journals.sagepub.com/doi/full/10.1177/10943420211022811
[4] https://journals.sagepub.com/doi/pdf/10.1177/10943420211028940
[5] https://performanceportability.org/case_studies/amr/overview/
[6] https://amrex-codes.github.io/amrex/doxygen/
[7] https://e4s-project.github.io/
[8] https://awards.acm.org/bell
[9] https://www.computer.org/csdl/proceedings-article/sc/2022/544400a025/1I0bSKaoECc
[10] https://warpx.readthedocs.io/en/latest/developers/amrex_basics.html
[11] https://awards.acm.org/bell
[12] https://www.youtube.com/watch?v=1ES2Cmbvw5o
[13] https://awards.acm.org/bell
[14] https://www.computer.org/csdl/proceedings-article/sc/2022/544400a025/1I0bSKaoECc
[15] https://www.computer.org/csdl/proceedings-article/sc/2022/544400a025/1I0bSKaoECc
[16] https://www.anl.gov/article/argonnes-new-sunspot-testbed-provides-onramp-for-aurora-exascale-supercomputer
[17] https://www.intel.com/content/www/us/en/developer/tools/oneapi/data-parallel-c-plus-plus.html
[18] https://docs.nersc.gov/performance/case-studies/amrex-gpu/