Researchers funded by the Exascale Computing Project have demonstrated an alternative to MPI, the de facto communication standard for high-performance computing (HPC), using NVIDIA’s library NVSHMEM to overcome the semantic mismatch between MPI and GPU asynchronous computation to enable the compute power needed for exascale computing. The team implemented their design in PetscSF, the communication module in the Portable, Extensible Toolkit for Scientific Computation (PETSc) library, and implemented a fully asynchronous CG solver in PETSc. Their work was published online in the May 2021 issue of IEEE Transactions on Parallel and Distributed Systems.
Programmers typically write computations in the form of kernels and launch them on CPUs for execution on GPU streams. To hide high launch costs and therefore maximize cost-effectiveness, one kernel’s launch on a CPU is best overlapped with another kernel’s execution on a GPU. However, with MPI, this is frequently not achievable. HPC programmers heavily rely on MPI to coordinate work, distribute data, manage data dependencies, and balance workloads. But MPI has not yet fully adjusted to heterogeneous architectures. For example, upon sending data with MPI, one currently must synchronize the GPU to make sure data, which is likely the output of a kernel on a certain stream, is ready for sending. The synchronization stalls kernel launch pipelines and hurts efficiency. NVSHMEM improves on MPI’s synchronization with GPUs and the resulting cost inefficiencies because it is asynchronous-computation-aware (i.e., stream-aware). It can pipeline communication requests from CPUs to GPUs on the same stream where kernels are queued for execution, eliminating the need for synchronization.
The team’s design is the first work to leverage GPUs for both communication and computation tasks, and their fully asynchronous solver is the first on GPUs. The research opens new GPU optimization opportunities for exascale computing. Future work includes exploring ways to achieve kernel fusion for even greater performance boosts and to automate the process of testing solver convergence and kernel launches.
Junchao Zhang, Jed Brown, Satish Balay, Jacob Faibussowitsch, Matthew Knepley, Oana Marin, Richard Tran Mills, Todd Munson, Barry F. Smith, Stefano Zampini. “The PetscSF Scalable Communication Layer.” 2022. IEEE Transactions on Parallel and Distributed Systems (April).
https://doi.org/10.1109/TPDS.2021.3084070
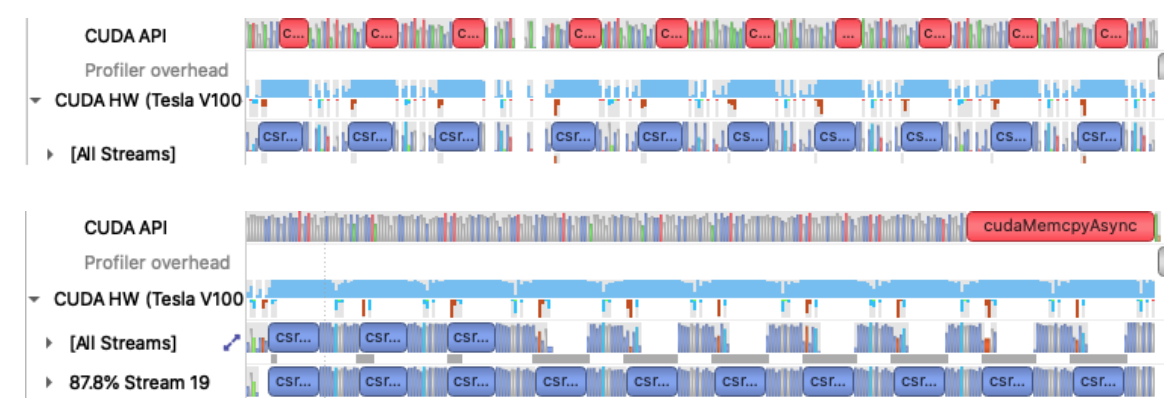
Timeline of CG (top) and CGAsync (bottom) on rank 2. Each ran 10 iterations. The blue csr… bars are csrMV (i.e., SpMV) kernels in cuSPARSE, and the red c… bars are cudaMemcpyAsync() copying data
from device to host.