Computer scientists working with the Exascale Computing Project (ECP) to advance LLVM compiler infrastructure have shown that OpenMP is an effective tool for remote accelerator offloading with more than a single compute node. Their work aims to establish OpenMP as a single performance-portable parallel programming model combining CPU parallelism, accelerator offloading, and distributed computing to reduce complexity and eliminate porting tasks. The team’s paper received the Hans Meuer Award for most outstanding research paper at the ISC High Performance 2022 conference, held in May. Their research was published in the conference proceedings.
The LLVM/Clang compiler, which reflects the scientists’ work, provides an extensive, novel, and production-ready OpenMP runtime system. Remote OpenMP offload enables users to utilize hardware in the cloud or on a compute cluster as if it was local to their machine and delivers improved debugging tools. Users can run their programs wherever the hardware is available while utilizing their own machine’s files and CPU resources. The work also runs offloaded code in a separate process, which can help users identify memory placement issues.
The scientists experimented with scaling up OpenMP to 120 GPUs, revealing limitations that inform future work. Plans include exploring the use of the UCX framework’s active messaging API for more efficient utilization of networking resources and the use of data compression to improve overall performance of remote OpenMP offloading. The team is also working on additional prototype extensions to make OpenMP remote offloading more convenient and efficient.
Atmn Patel and Johannes Doerfert, Remote OpenMP Offloading.”2022. Proceedings of ISC High Performance 2022: High Performance Computing (May).
https://doi.org/10.1007/978-3-031-07312-0_16
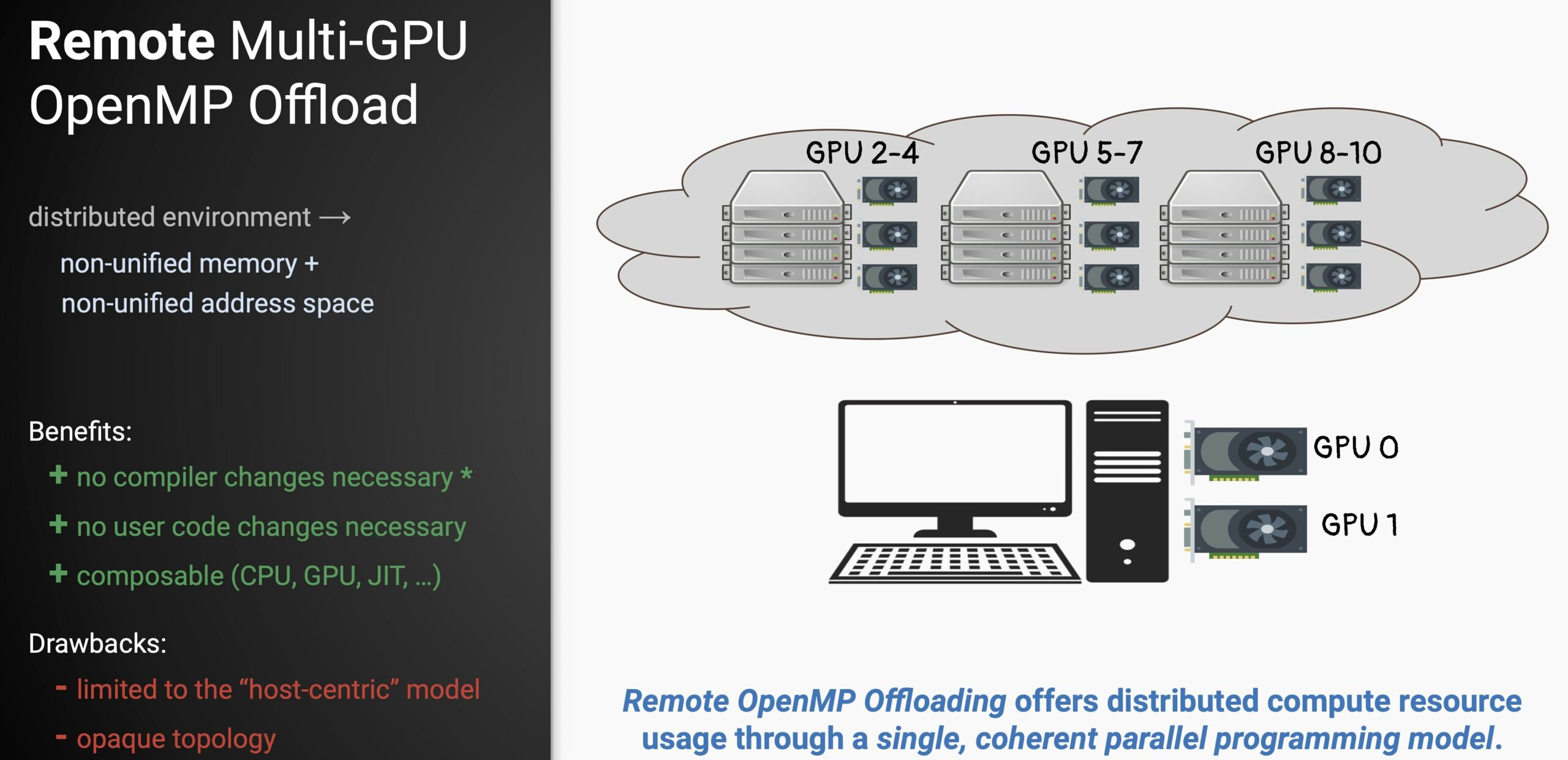
Scientists working with ECP aim to establish OpenMP as a single performance-portable parallel programming model combining CPU parallelism, accelerator offloading, and distributed computing to reduce complexity and eliminate porting tasks.