By Rob Farber, contributing writer
STRUMPACK (STRUctured Matrix PACKage) is a portable software library for sparse and dense rank-structured linear systems that runs well on both many-core processors and GPUs. Key to the benefits of STRUMPACK is its focus on efficiently performing dense linear algebra on relatively small matrices, but it should also be noted that AMD GPU support is still in early development.
The algorithm is described in detail in the STRUMPACK project references.
At a high level, the sparse solver follows the following algorithmic phases.
The first two phases are illustrated in Figure 1:
- Parallel maximum matching for pivoting, which is performed in collaboration with the Department of Energy Exascale Computing Project (ECP) ExaGraph More specifically, STRUMPACK (and the related SuperLU solver) use a static pivoting strategy in which the matrix is permuted beforehand, so that the largest elements of the input matrix are placed on the diagonal, instead of swapping at runtime. [i] In addition, ExaGraph is working with the factorization-based sparse solvers team on a nested-dissection-based sparse matrix ordering capability and a parallel symbolic sparse matrix factorization algorithm using GraphBLAS primitives that can run on GPUs.
- Fill-reducing ordering using a Metis partitioner, which can reduce computation on off-diagonal block ranks. In addition, the team is investigating using spectral partitioning, which is well suited to GPUs and accelerators.[ii]
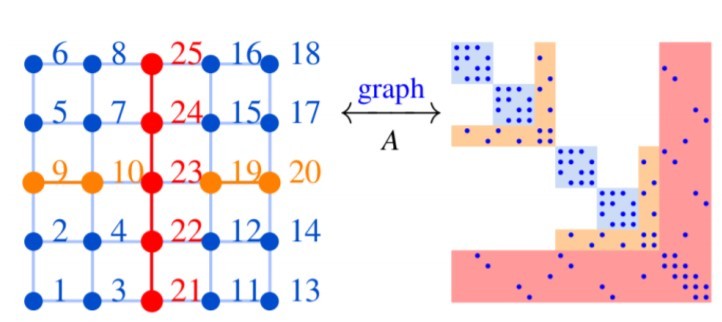
Figure 1: Conversion to a graph as discussed in the previous two bullets (source: https://ecpannualmeeting.com/assets/overview/posters/ECP2020_STRUMPACK_ButterflyPACK.pdf)
Figure 2 illustrates the remaining step.
- The dense frontal matrices making up the sparse triangular factors are stored in a binary tree, referred to as the assembly tree or supernodal tree, as illustrated in Figure 2. Numerical factorization requires a bottom-up traversal of this tree with at each node a dense (partial) LU factorization and Schur complement computation. In the original code, this traversal is done recursively using OpenMP tasking. The STRUMPACK team has modified this traversal to a level-by-level traversal that permits parallel batched BLAS (and LAPACK) operations.
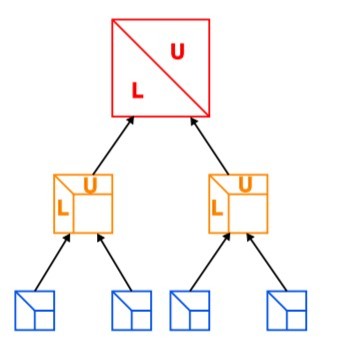
Figure 2: Creation of the supernodal/separator tree (source: https://ecpannualmeeting.com/assets/overview/posters/ECP2020_STRUMPACK_ButterflyPACK.pdf)
The STRUMPACK team has replaced the xGETRF, xLASWP, xGETRS, xTRSM (2x), and xGEMM calls in the numerical factorization with equivalent calls to cuBLAS and cuSOLVER routines. The logic is modified slightly.
To increase the overlap between memory transfers and GPU kernels, the cuBLAS and cuSOLVER routines are called from different CUDA streams.
Profiling with nvprof showed that the overhead of the kernel launch is prohibitively costly for smaller frontal matrices. A drastic performance improvement was obtained by only calling the cuBLAS/SOLVER routines for matrices larger than a certain threshold.
A custom kernel was created to handle matrices smaller than the threshold. Initially this was a CUDA kernel, which was later ported to OpenMP during the NERSC OpenMP hackathon, which was held August 17–20, 2019. Unfortunately, the latest versions of CUDA no longer allow cuBLAS/cuSOLVER routines to be called from the device (from within a kernel). Hence, the current manual implementation of this kernel is rather naive but will be replaced in the future by functionality provided by the SLATE or MAGMA projects.
The team used the variable-sized batched xGEMM and xTRSM routines from the MAGMA library to handle all xGEMM/xTRSM calls on a given level with a single kernel launch. Unfortunately, no variable-sized batched xGETRF or xGETRS is currently available. This means the code still relies on a manual kernel for the small matrices and a loop of individual calls to MAGMA xGETRF. It is possible MAGMA may support variable-sized batched xGETRF in the future, but this might be challenging due to the pivoting issues. For future portability, the team plans to rely as much as possible on libraries such as MAGMA and SLATE (a modern GPU-aware ScaLAPACK alternative) as well as OpenMP with offload capability instead of CUDA. Initial tests show this to be a viable option.
Summary
STRUMPACK is an E4S project that provides robust and scalable factorization-based methods for the ill-conditioned and indefinite systems of equations that arise in high-fidelity, large-scale multiphysics and multiscale models.
Look to E4S.io for more information on using the tested and verified versions of STRUMPACK via the E4S containers or turnkey E4S build cache. A variety of processors, GPUs, and Linux operating system versions are supported. Users can also build the library via the E4S build from-source or directly from github.
Rob Farber is a global technology consultant and author with an extensive background in HPC and machine learning technology development that he applies at national labs and commercial organizations. Rob can be reached at [email protected].
[i] “Exagraph Collaboration with STRUMPACK/SUPERLU: Factorization-Based Sparse Solvers and Preconditioners for Exascale,” https://www.exascaleproject.org/exagraph-with-strumpack-superlu/
[ii] Slide 5 of https://ecpannualmeeting.com/assets/overview/sessions/ECP2020-ExaGraph-Boman.pdf