By Rob Farber, contributing writer
The recent proliferation of new hardware technologies has galvanized the high-performance computing (HPC) community and created the ability to deliver the nation’s forthcoming exascale-capable supercomputers and data centers. It has also made LLVM-based compiler technology the default gatekeeper to these new systems.
LLVM, an open-source collection of compiler and toolchain technologies, serves as a test bed for proposed parallelization extensions (e.g., the interoperability directive in OpenMP 5.1) and as a vehicle to provide production-quality parallel compiler implementations. Johannes Doerfert, a researcher at Argonne National Laboratory, notes that “LLVM is a vehicle to provide performant implementations of OpenMP across all platforms.[1] In LLVM we always aim to be portable, standard compliant, and complete with regards to the standard. Aside from OpenMP, LLVM can also benefit other pragma-based standards and parallel programming models, such as OpenACC, CUDA, SYCL, and HIP.”
LLVM is a vehicle to provide performant implementations of OpenMP across all platforms. In LLVM we always aim to be portable, standard compliant, and complete with regards to the standard. Aside from OpenMP, LLVM can also benefit other pragma-based standards and parallel programming models, such as OpenACC, CUDA, SYCL, and HIP. — Johannes Doefert, Researcher at Argonne National Laboratory
Virtually every leading computing company is collaborating on LLVM, which is one of the many benefits of using the LLVM compiler infrastructure. “People don’t realize that most HPC vendor compilers are LLVM-based,” Doerfert observes. “Improvements in collaboration as well as improvements to LLVM benefit both vendor products and the overall HPC community.”
People don’t realize that most HPC vendor compilers are LLVM-based. Improvements in collaboration as well as improvements to LLVM benefit both vendor products and the overall HPC community. — Johannes Doerfert, Researcher at Argonne National Laboratory
Direct Benefits to HPC
Building production compilers on top of LLVM gives the HPC community the ability to provide extensions and bug fixes. This allows the HPC community to focus on HPC needs for their compilers by using LLVM as a vehicle to build custom tooling for program analysis tools, debuggers, and profilers. LLVM is a significant part of the US Department of Energy’s (DOE’s) Exascale Computing Project (ECP), as illustrated in Figure 1, which shows the key role that LLVM plays in all associated projects.
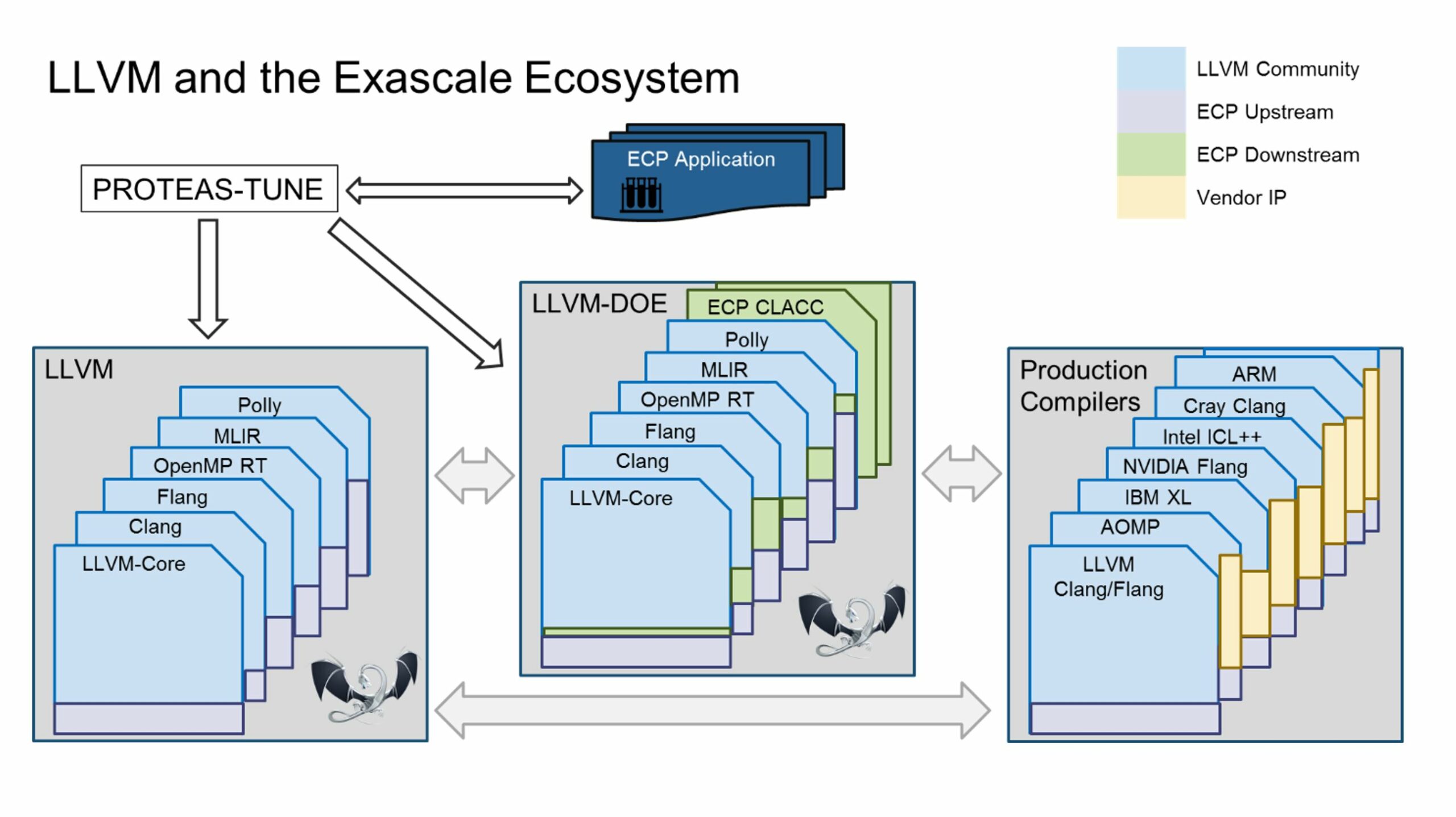
Figure 1. LLVM plays an important role in the Exascale software ecosystem.
LLVM Gives HPC the Ability to Focus Compilers on HPC Needs
The permissive terms of LLVM licensing mean that the HPC community can safely dedicate significant resources to build and release open source software using the LLVM compiler infrastructure. This includes profilers, parallel compilers, debuggers, Domain-Specific Languages (DSLs), and new programming models. It also means that the HPC community is not required to go through the process of filing a bug with the vendor and waiting for a bug fix. Instead, HPC developers can find and submit fixes to the open-source code base.
Fortran for HPC
The ECP Flang project is one example in which the HPC community can focus on a critical need, namely the development of a parallelizing, GPU-enabled Fortran compiler.
Flang is a Fortran front end that can transfer the job of parallelization and binary generation to the LLVM infrastructure to generate binaries for different HPC architectures. Such a compiler is needed to run Fortran applications on new, power-efficient, many-core, massively parallel hardware platforms that are the foundation of modern HPC systems and data centers. Flang is important because there is not a huge commercial emphasis on Fortran, but there is a huge HPC need for an effective parallelizing and GPU-enabled Fortran compiler. GPUs from several vendors are significant architectural components in the forthcoming exascale systems. Figure 2 shows how Flang’s design relies on LLVM.
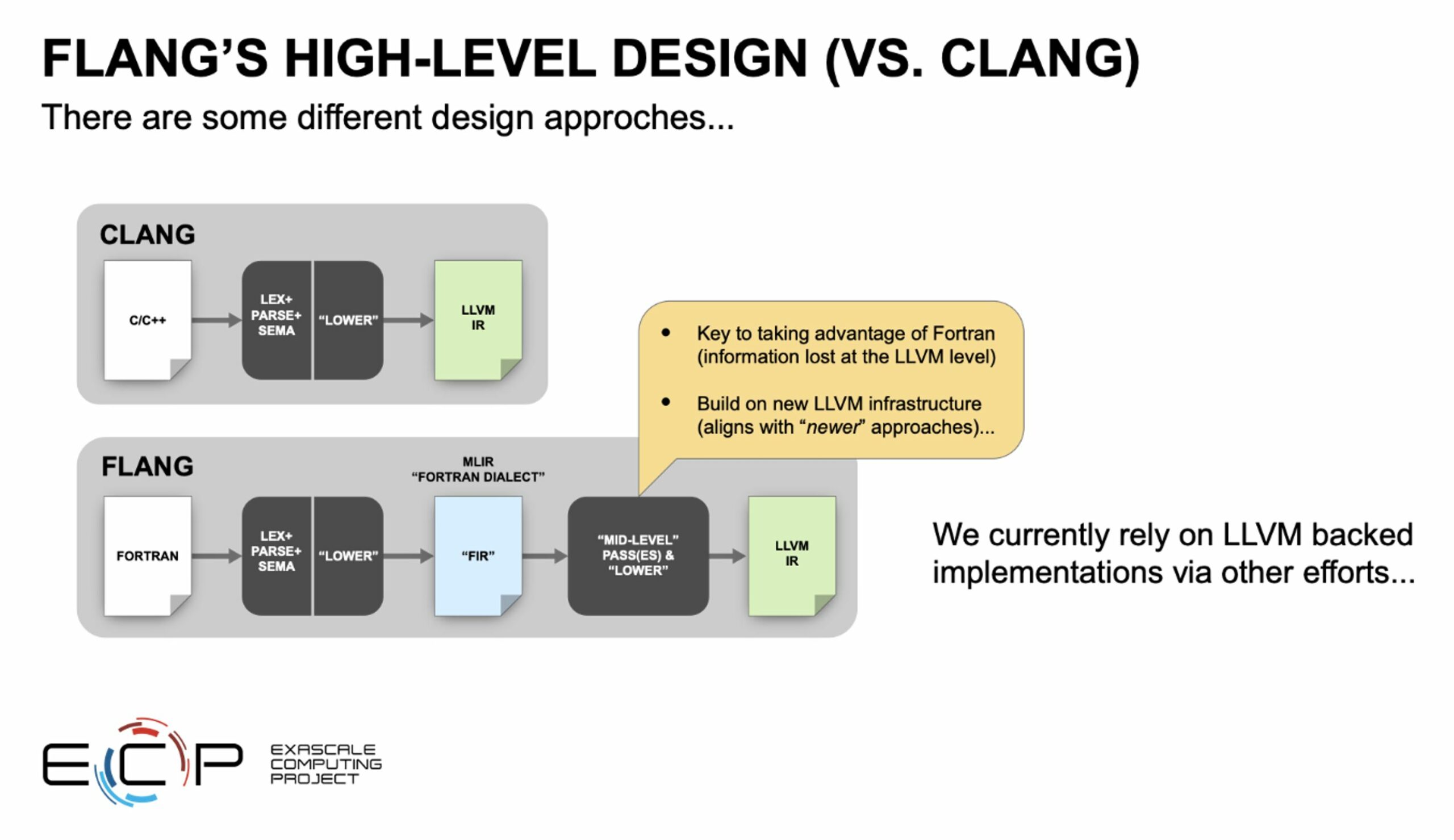
Figure 2. Flang’s design relies on LLVM.
Many Parallelization and Cross Platform Benefits
Parallelization is difficult, and performant cross-platform parallelization is even more difficult. LLVM provides the compiler infrastructure to create parallelizing compilers beyond parallelizing C/C++ and Fortran compilers. The LLVM parallelization capabilities mean that DSLs can provide generality and performance across LLVM-supported platforms.
Programmatic Assistance in Generating Sane, Deterministic Binaries
To assist with generating production-ready binaries, LLVM allows compiler writers to use sanitizers. Doerfert notes, “In the C++ world, sanitizers provide sanity checks on memory usage and other manifestations of aberrant behavior. Sanitizers can detect such errors during runtime. The result is more robust codes and thorough quick checks that can help ensure correct results and even be used to detect possible intrusions into the supercomputer center.”
Another benefit is detecting race conditions. A race condition occurs when a parallel result depends on the timing of events. The end result causes an application to exhibit unpredictable (i.e. nondeterministic) behavior during runtime. Finding and fixing bugs caused by race conditions can be extremely difficult. LLVM-based race detection can be very useful.
Informative Profilers
Profiling is also important for creating performant parallel codes, especially when codes run across a variety of hardware platforms. Sameer Shende, Director of the Performance Research Lab of the University of Oregon’s Neuroinformatics Center, observes that “The TAU profiler supports all CPUs and GPUs, as well as multi-node profiling with MPI and high-level performance portable libraries, such as Kokkos. It’s one of the few tools that supports all vendor GPUs. The TAU (Tuning and Analysis Utilizes) profiler easily installs via Spack and is distributed in the Extreme-Scale Scientific Software Stack (E4S). Just install TAU with the target back-end CUDA, ROCm, or L0 for OneAPI.” This makes TAU and the LLVM-based profiling application programming interfaces (APIs) important tools for creating performant, cross-platform HPC applications. Figure 3 outlines the TAU profiling system.
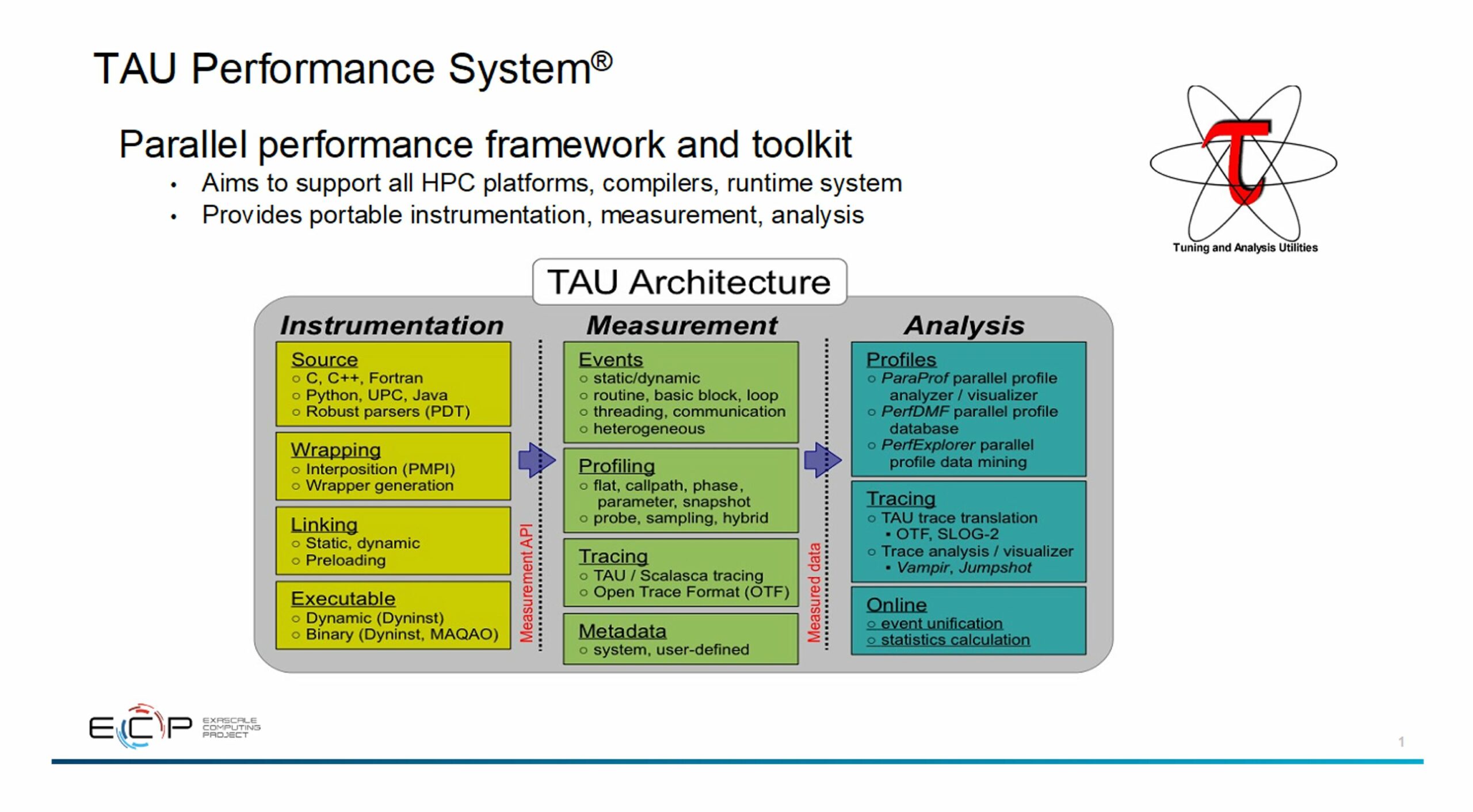
Figure 3. The TAU profiling system. (Source: https://www.alcf.anl.gov/sites/default/files/2020-05/CompWorkshop_TAU_2020.pdf.)
A “Swiss army knife” of profiling, TAU relies on LLVM trace and instrumentation capabilities to generate profile information. Significant amounts of profile information can be collected from LLVM. The TAU team creates meaningful displays to help people find performance issues in parallel distributed codes. Example views generated by the ParaProf analysis tool can be seen in Figure 4. In particular, ParaProf can display profile information about MPI communication calls. A standard in HPC, the MPI library handles the communications that dictate the scaling and performance of many HPC applications. Shende notes that with TAU, “you can see the code regions of interest, where you should study your application performance, and where you should focus your optimization efforts.”
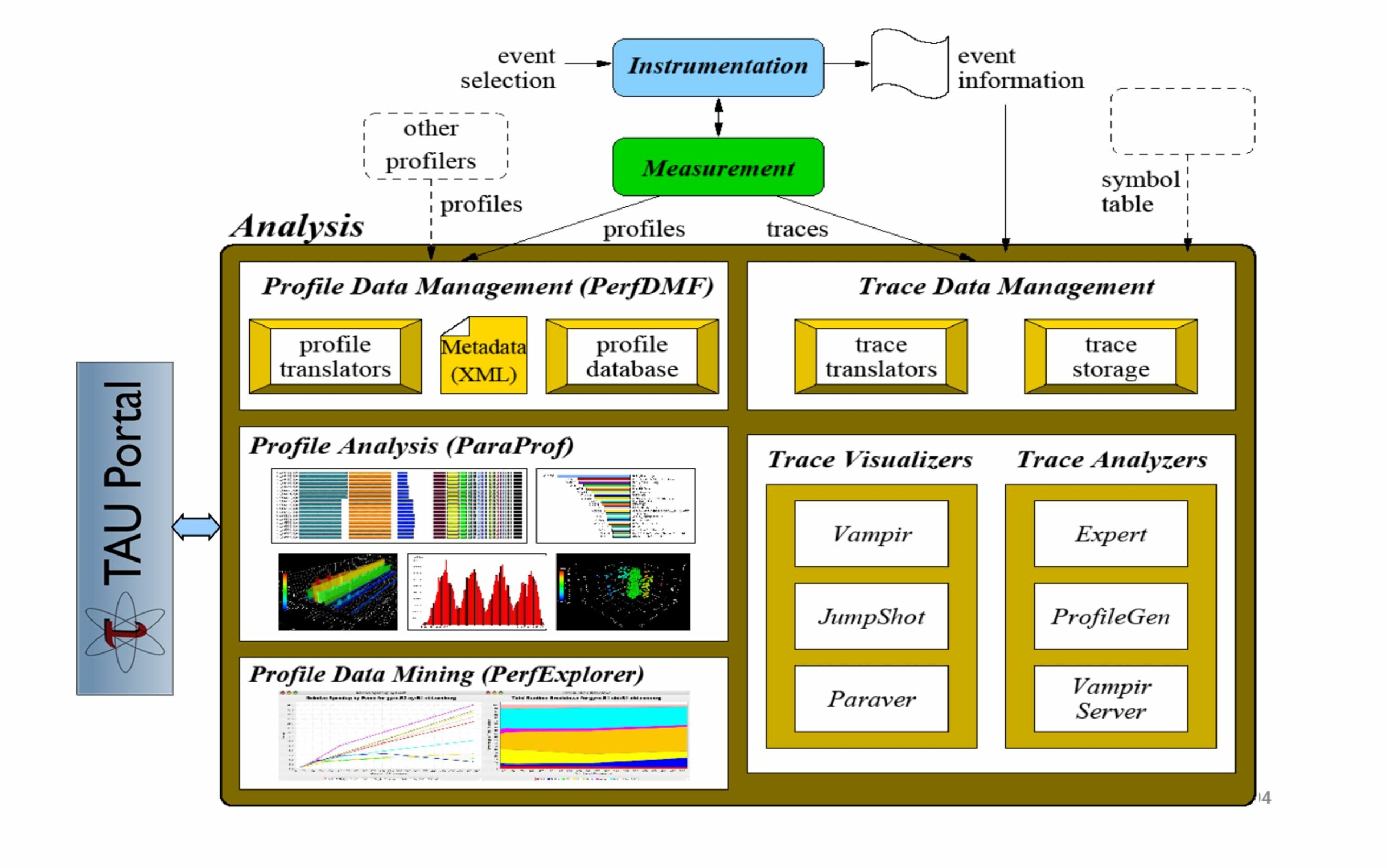
Figure 4. TAU Analysis with example ParaProf views.
Synopsys of What TAU Supports
- OpenMP
- OpenMP Tools Interface (OMPT) tools interface to track salient OpenMP runtime events
- Opari source rewriter
- Preloading wrapper OpenMP runtime library when OMPT is not supported
- OpenACC
- OpenACC instrumentation API
- Tracks data transfers between host and device (per variable)
- Tracks time spent in kernels
- OpenCL
- OpenCL profiling interface
- Tracks timings of kernels
- CUDA
- CUDA Profiling Tools Interface
- Tracks data transfers between host and GPU
- Tracks access to uniform shared memory between host and GPU
- ROCm
- Rocprofiler and Roctracer instrumentation interfaces
- HIP LLVM compiler based instrumentation support
- Tracks data transfers and kernel execution between host and GPU
- Intel oneAPI
- Intel compilers with compiler-based instrumentation and Level Zero profiling API
- OpenCL profiling API
Summary
The liberal licensing and strong vendor support make LLVM an excellent vehicle for the HPC community to use in addressing many HPC community needs. This is reflected in the belief by Doug Kothe, Director of DOE’s ECP, that “LLVM compiler technology is becoming the nexus for vendor and community compiler development and evolution.”[2]
LLVM compiler technology is becoming the nexus for vendor and community compiler development and evolution. — Doug Kothe, Director, Exascale Computing Project
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national laboratories and commercial organizations. Rob can be reached at [email protected]
[1] https://www.exascaleproject.org/highlight/sollve-openmp-for-hpc-and-exascale/
[2] https://www.exascaleproject.org/highlight/sollve-openmp-for-hpc-and-exascale/