By Rob Farber, contributing writer
Matrix Algebra on GPU and Multicore Architectures (MAGMA) is a well-known and performant choice for those who desire Basic Linear Algebra Subroutines (BLAS) and Linear Algebra Package (LAPACK) functionality that runs on CPUs, GPUs from various vendors, and across multiple GPUs in a single node. MAGMA also has solvers to exploit hardware mixed-precision arithmetic to potentially increase application capability and performance while also protecting against precision issues. Jack Dongarra observes that, “People are using it. People seem to like it. Matlab, for example, uses MAGMA.”
People are using it. People seem to like it. Matlab, for example uses MAGMA. — Jack Dongarra, Industry Luminary and American University Distinguished Professor of computer science in the Electrical Engineering and Computer Science Department at the University of Tennessee
The Exascale Computing Project (ECP) provides a plethora of tested and verified builds of MAGMA. Stan Tomov notes that “MAGMA has a large set of test suites that stresses both easy and hard problems, accuracy, and multi-GPU configurations.” ECP brings that level of tested and verified support to the exascale community through a variety of Extreme-Scale Scientific Software Stack containers (e.g., Docker, Singularity). Numerous Spack builds for various CPU and operating system types can be quickly accessed via the binary cache. Users can download and build from source using Makefiles, CMake, or Spack. Figure 1 details MAGMA’s features and support.
MAGMA has a large set of test suites that stress both easy and challenging problems, accuracy, plus multi-GPU configurations. — Stan Tomov, Research Director in the Innovative Computing Laboratory at the University of Tennessee

Figure 1: MAGMA features and support. (Source https://www.icl.utk.edu/files/print/2020/magma-sc20.pdf.)
Portable, Performant, Cross-Platform Numerical Linear Algebra is Difficult
A workhorse of high-performance computing (HPC), the advent of new approaches and architectures has made it difficult to support even a standardized BLAS application programming interface (API) for various matrix sizes across the current crop of HPC computational and memory architectures.[1] Figure 2 illustrates these challenges.
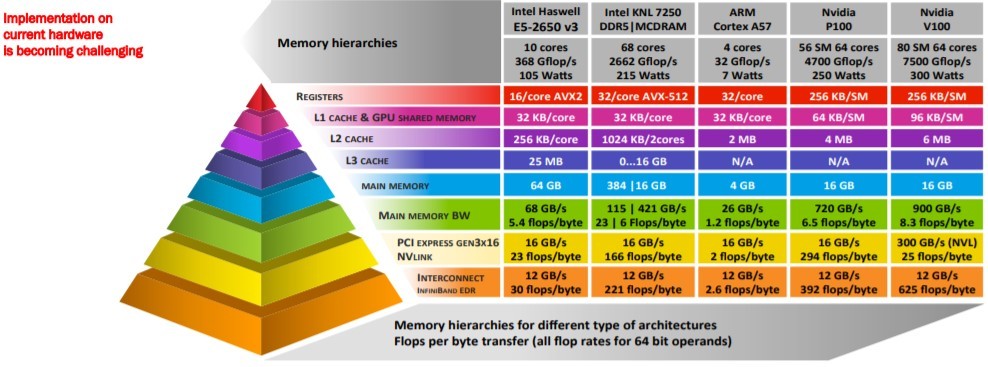
Figure 2: Challenges in supporting even basic BLAS operations. (Source: https://ecpannualmeeting.com/assets/overview/sessions/2020-MAGMA-heffte-tutorial.pdf.)
As part of their work in the ECP and the ECP SLATE (Software for Linear Algebra Targeting Exascale) project, the MAGMA team investigates new APIs and approaches while providing a robust and performant numerical library for existing HPC applications. Figure 3 the progression of these investigations over time.
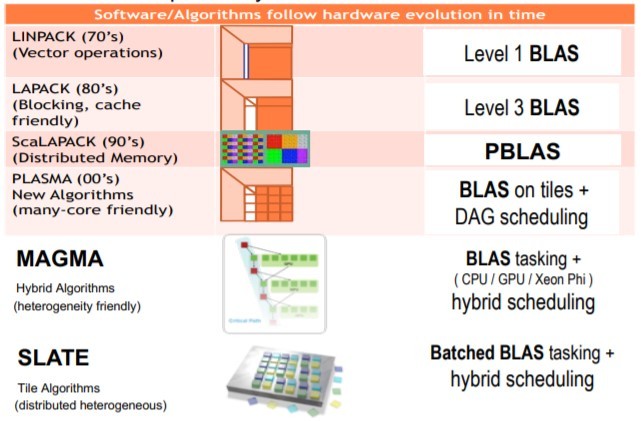
Figure 3: A progression of linear algebra libraries. (Source: https://www.olcf.ornl.gov/wp-content/uploads/2018/10/tomov_2019OLCFUserMeeting.pdf.)
Your Architecture is Likely Supported
The MAGMA library capabilities are extraordinary, as illustrated by the set of tri-nested loops in Figure 4 that describe the architectures, precisions, and sparse, dense, batched, and artificial intelligence (AI) interfaces supported by MAGMA.[2] Given the library’s expansiveness, the test suites are an essential part of MAGMA that ensures functionality and correctness across the breadth of the supported interfaces and architectures. Tomov notes that running all the tests is time-consuming and can take more than 24 hours.

Figure 4: MAGMA provides an extraordinary vehicle for linear algebra. (Source: https://www.olcf.ornl.gov/wp-content/uploads/2018/10/tomov_2019OLCFUserMeeting.pdf.)
The Performance and Capabilities Motivation
Batched, mixed precision, and other capabilities make MAGMA a compelling choice for linear algebra applications. MAGMA also supports preconditioning operations, which are not discussed in this article.
Work with Big Matrices and/or Batches of Small Numerical Linear Algebra Problems
Many scientific computations require solving both large numerical linear algebra problems (e.g., BLAS, convolutions, SVD linear system solvers) and batches of many concurrent smaller problems that can be solved in parallel. MAGMA includes a well-established large matrix capability and support for smaller matrix computations that occur in AI and , High-Performance Data Analytics (HPDA) (HPDA), High-order FEM, graph analysis, neuroscience, quantum chemistry, signal processing, and many other problem domains.
For example, within the ECP CEED Project, MAGMA batched methods are used to split the computation on many small high-intensity GEMMs grouped (e.g., batched) for efficient execution. Other applications include high-order Finite Element Methods (FEM). [3]
Benchmarks show that MAGMA-batched computations can deliver sizable speedups, depending on the underlying hardware’s memory and parallelism. The MAGMA team provided some illustrative benchmark results on an NVIDIA V100 GPU for matrices ranging from size 50–1,000.[4]
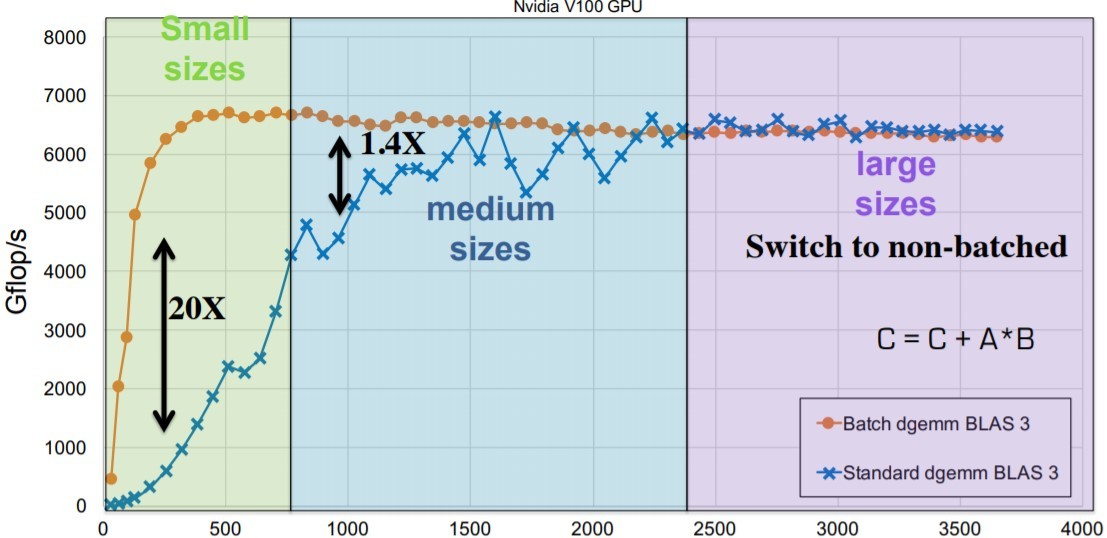
Figure 5: MAGMA-batched computations. (Source: https://ecpannualmeeting.com/assets/overview/sessions/2020-MAGMA-heffte-tutorial.pdf.)
Mixed-Precision Linear Algebra
Hardware support for reduced-precision arithmetic has also generated new approaches to mixed-precision linear algebra library support. The idea behind mixed-precision matrix operations shown in Figure 6 is to compute the expensive flop/s (LU O(n3)) matrix operations in reduced-precision and then iteratively refine the solution to match the accuracy of 64-bit arithmetic approaches. [5] [6]

Figure 6: The idea behind mixed-precision Ax = b. (Source: https://www.olcf.ornl.gov/wp-content/uploads/2018/10/tomov_2019OLCFUserMeeting.pdf.)
Many HPC applications have to solve Ax = b. Figure 7 shows the observed speedups on the SuiteSparse Collection when solving dense matrices in radar designs.
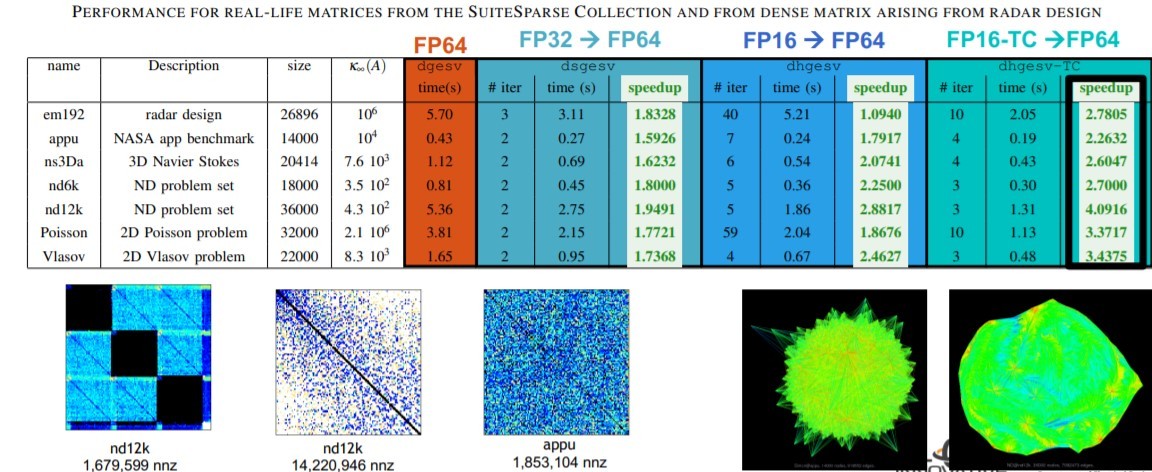
Figure 7: Performance for real-life matrices from the SuiteSparse Collection and dense matrix operations arising from radar design. (Source: https://www.olcf.ornl.gov/wp-content/uploads/2018/10/tomov_2019OLCFUserMeeting.pdf.)
Other real-world application performance gains are compelling. Using the NVIDIA Tensor Cores, MAGMA delivered a 3.5× performance speedup in an ASGarD adaptive stream sparse grid discretization simulation to help scientists better understand what is happening inside a fusion reactor.
Sparse Matrix Support
MAGMA also supports various sparse data formats, including CSR, ELL, SELL-P, SDR5, and HYB. The current focus is on GPU hardware. As seen in the benchmark results in Figure 8, performance is competitive against the cuSPARSE 8.0 release of the NVIDIA sparse matrix library.
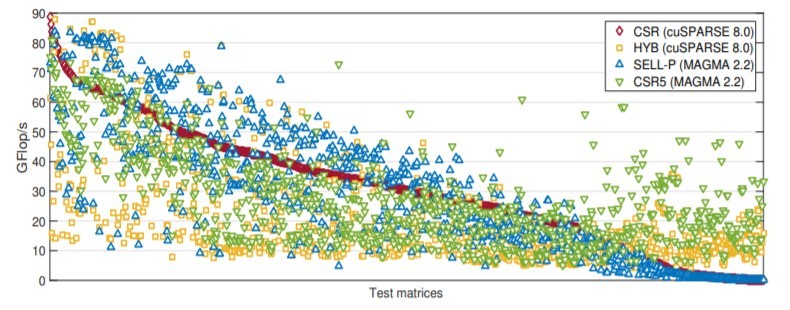
Figure 8: SpVM double precision performance on matrices from the SuiteSarse Matrix Collection on and NVIDIA P100. (Source: https://ecpannualmeeting.com/assets/overview/sessions/2020-magma-heffte-tutorial.pdf.)
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national laboratories and commercial organizations. Rob can be reached at [email protected]
[1] https://ecpannualmeeting.com/assets/overview/sessions/2020-MAGMA-heffte-tutorial.pdf.
[2] The MAGMA heFFT package is described in another article.
[3] V. Dobrev, T. Kolev, R. Rieben, “High Order Curvilinear Finite Element Methods for Lagrangian
Hydrodynamics,” SIAM J.Sci.Comp.34, no. 5, B606–B641.
[4] https://ecpannualmeeting.com/assets/overview/sessions/2020-MAGMA-heffte-tutorial.pdf.
[5] https://www.icl.utk.edu/publications/investigating-half-precision-arithmetic-accelerate-dense-linear-system-solvers.
[6] A. Haidar, S. Tomov, J. Dongarra, “Leveraging Half Precision in HPC,” in preparation for Association for Computing Machinery Transactions on Mathematical Software.