By Rob Farber, contributing writer
Climate simulation has already proven to be an invaluable tool for identifying and quantifying the impacts of climate change, but even greater accuracy is required at all levels to make better and more precise forecasts of our climate. Accurate forecasts tell us about the climate we are creating for our descendants and the world they will experience many decades into the future.
Even with the performance of the forthcoming generation of exascale supercomputers, multidecadal, cloud-resolving simulations of Earth’s water cycle require a middle ground approach in which some atmospheric components such as convection are modeled at a cloud-resolving high resolution. Owing to the extreme computational cost, these high-resolution calculations are usually performed on limited domains to shorten the run time. Lower resolution climate models must then be used to further process the high-resolution results at a global scale. This contrasts the current high-accuracy approaches in which researchers run ultrahigh-resolution cloud-resolving simulations—just not for decadal-scale simulations. Alternatively, other researchers routinely accept more approximate results when they run multi-century low-resolution simulations of the Earth’s water cycle. Although the run time benefits of a middle ground approach are clear, correctly merging the results of high- and low-resolution models is a tricky endeavor.
To address long-term climate science questions, the Energy Exascale Earth System Model (E3SM) project recognizes that new approaches are required to leverage the computational throughput needed to enable more accurate multidecadal simulations.[1] These climate science questions are codified in a series of stepwise grand simulation campaigns (Figure 1) designed to accurately model the coupled human-Earth system far into the future.
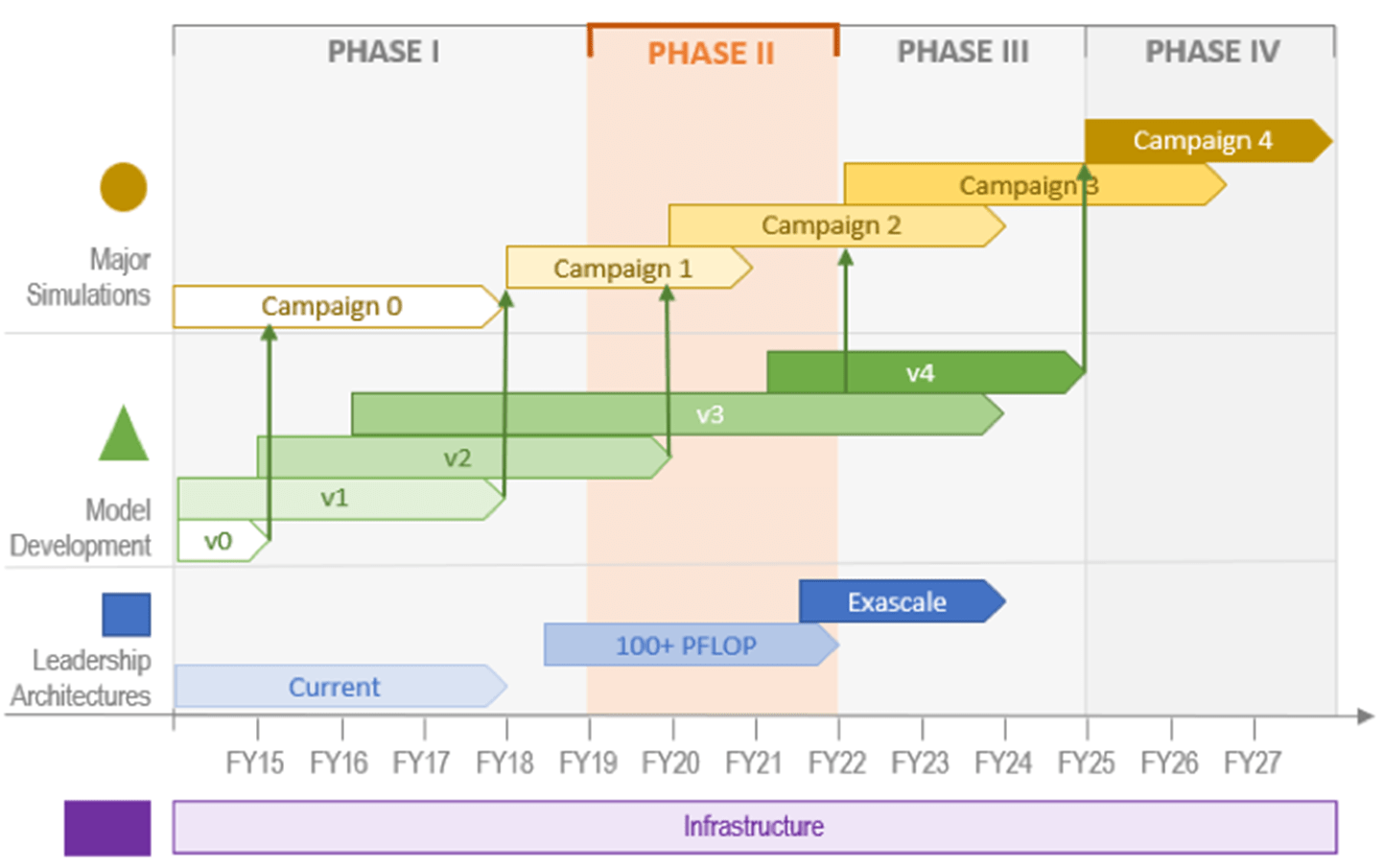
Figure 1. E3SM major science campaigns. This figure was originally designed in FY18, when the future dates were estimates (Source: https://e3sm.org/research/science-campaigns/).
The Exascale Computing Project-Funded Multiscale Modeling Framework
The Exascale Computing Project (ECP)-funded Multiscale Modeling Framework (E3SM-MMF) effort is exploring one of these new approaches through the addition of a multiscale modeling framework (MMF). As indicated by the addition of “-MMF” to the E3SM name, the task of the E3SM-MMF team is to add a high-resolution cloud resolving model (CRM) to improve the representation of moist convection in E3SM global climate models.
Mark Taylor (Figure 2), PI of the E3SM-MMF project, chief computational scientist for the E3SM project, and Sandia National Laboratories staff member, notes, “In E3SM-MMF, we replaced E3SM’s conventional coarse approximations to moist convection with a CRM that runs on a high-resolution 1 km grid. Our ECP MMF project has contributed the algorithmic work needed to couple these CRMs with the traditional 28 km grid spacing E3SM climate model. Scientifically, this delivers significant value, as moist convection is one of the dominant sources of uncertainty in climate projections.”[2] Overall, the E3SM project combines five components (atmosphere, ocean, land surface, land ice, and sea ice) needed to study the Earth’s water cycle, biogeochemistry interactions, and changes in the cryosphere, [3] and the E3SM-MMF configuration focuses on improving the model’s ability to model the Earth’s water cycle.
In E3SM-MMF, we replaced E3SM’s conventional coarse approximations to moist convection with a CRM that runs on a high-resolution 1 km grid. Our ECP MMF project has contributed the algorithmic work needed to couple these CRMs with the traditional 28 km grid spacing E3SM climate model. Scientifically, this delivers significant value, as moist convection is one of the dominant sources of uncertainty in climate projections. – Mark Taylor
Science Drivers
With extensive input from both DOE scientists and external experts, the initial E3SM project focus was “narrowed at the project’s outset to three critically important Earth-system science drivers that strongly influence, and are influenced by, the energy system: the water cycle, biogeochemistry, and the cryosphere system.”[4]
These science drivers integrate the understanding of Earth system processes that are foundational to Earth system prediction. Recognizing that the desired ultrahigh-resolution challenge simulations of the coupled human-Earth system are not yet possible with current models and computing capabilities, the project team adopted a stepwise scientific and software approach. Scientifically, each campaign goal is designed to refine the science questions and develop new testable hypotheses to be addressed with subsequent versions of the modeling system. Concurrently, the modeling software is being refactored and improved for the challenge campaigns that will use current and future leadership computing architectures. To this end, portability, performance, and scalability on new and upcoming architectures must be considered in the design choices being made right now.
The development of ECP E3SM-MMF makes use of GPU acceleration and various physics improvements to improve simulation capabilities for water cycle experiments that will run on exascale supercomputers. Early analysis of E3SM-MMF indicates that it reproduces the results of previous MMF studies, which gives the team confidence that the new model is behaving as expected. Additional physics improvements were motivated by the discovery of a subtle and surprising new bias that produces a grid artifact reminiscent of a checkerboard pattern, which was later connected to an unrepresented scale interaction process in the model. The team is also developing several more physics upgrades that target improvements in the parameterizations of cloud particles and turbulent mixing.
The CRM embedded in E3SM-MMF allows for an explicit representation of clouds across the globe (Figure 3) and is adapted from the System for Atmospheric Modeling (SAM), which has been used extensively on CPU systems. Taylor notes that the ECP project first rewrote SAM in C++ for optimal GPU performance and is now developing the Portable Atmosphere Model (PAM), which will include new algorithms for evolving the momentum and thermodynamic fields that are specifically designed for efficient GPU performance. PAM is slated to replace SAM in the next year.
Technical Introduction
The E3SM project is not intended to make local weather forecasts like those we see on the web or television. Taylor explains, “Think of our software like a weather forecast model but one that models the weather over long periods of time so that we can then compute climate statistics. We are not trying to predict individual storms but rather correctly model the long-term climatology.”
Think of our software like a weather forecast model but one that models the weather over long periods of time so that we can then compute climate statistics. We are not trying to predict individual storms but rather correctly model the long-term climatology. – Mark Taylor

Figure 2. Mark Taylor
A simulation campaign consists of select large-scale simulations used by the E3SM team to address the science questions of each science driver. Every campaign is designed to inform the next effort, and the successive versions of the modeling system will lead to the simulations that fully address the science questions. As noted by E3SM, each successive version of the modeling system must focus on software improvements that will maximize the throughput of the model, which is typically measured in Simulated Years Per wall clock Day (SYPD).[5]
To realize the computational throughput needed to meet the current project goals, the team ported the E3SM-MMF CRM code to work with GPU accelerators. The ported software leveragesthe massively parallel capabilities of these GPUs, which are found in many modern high-performance computing systems, including exascale supercomputers. Exposing the parallelism in a code base of nearly 2 million lines of Fortran also required significant refactoring of the software.
GPU acceleration of climate models is particularly challenging because these models typically exhibit a flat execution profile across all aspects of the computation. The traditional components of the E3SM model are no exception. Given that there are no optimization hot spots or single computational kernels that dominate the run time, nearly every kernel must be optimized to provide a big application performance boost. Incorporating a CRM that processes more data at each grid point with the E3SM-MMF approach changes this paradigm and provides an excellent optimization target. Profiling shows that the CRM code comprises roughly 10,000 lines of code yet consumes a vast majority of the E3SM-MMF’s run time. This made the CRM code an ideal target for GPU acceleration. As mentioned above, E3SM-MMF’s use of the CRM with 1 km grid resolution is scientifically important because it helps reduce a dominant source of uncertainty in the model’s results.[6]
To date, simulations performed on the GPU-accelerated Summit supercomputer at the Oak Ridge Leadership Computing Facility (OLCF) show an unprecedented cloud-resolving physics atmospheric climate simulation.[7] Taylor notes, “GPU acceleration provides a significant increase in throughput of the CRM, which in combination with other modifications brings the E3SM-MMF performance more in line with traditional parameterized global models, even though it is resolving many aspects of moist convection with the CRM’s 1 km as opposed to traditional approximations on a 100 km grid.”[8] These preliminary results indicate that the team has successfully refactored the code so it can be used to address future scientific questions on GPU-accelerated exascale supercomputers.
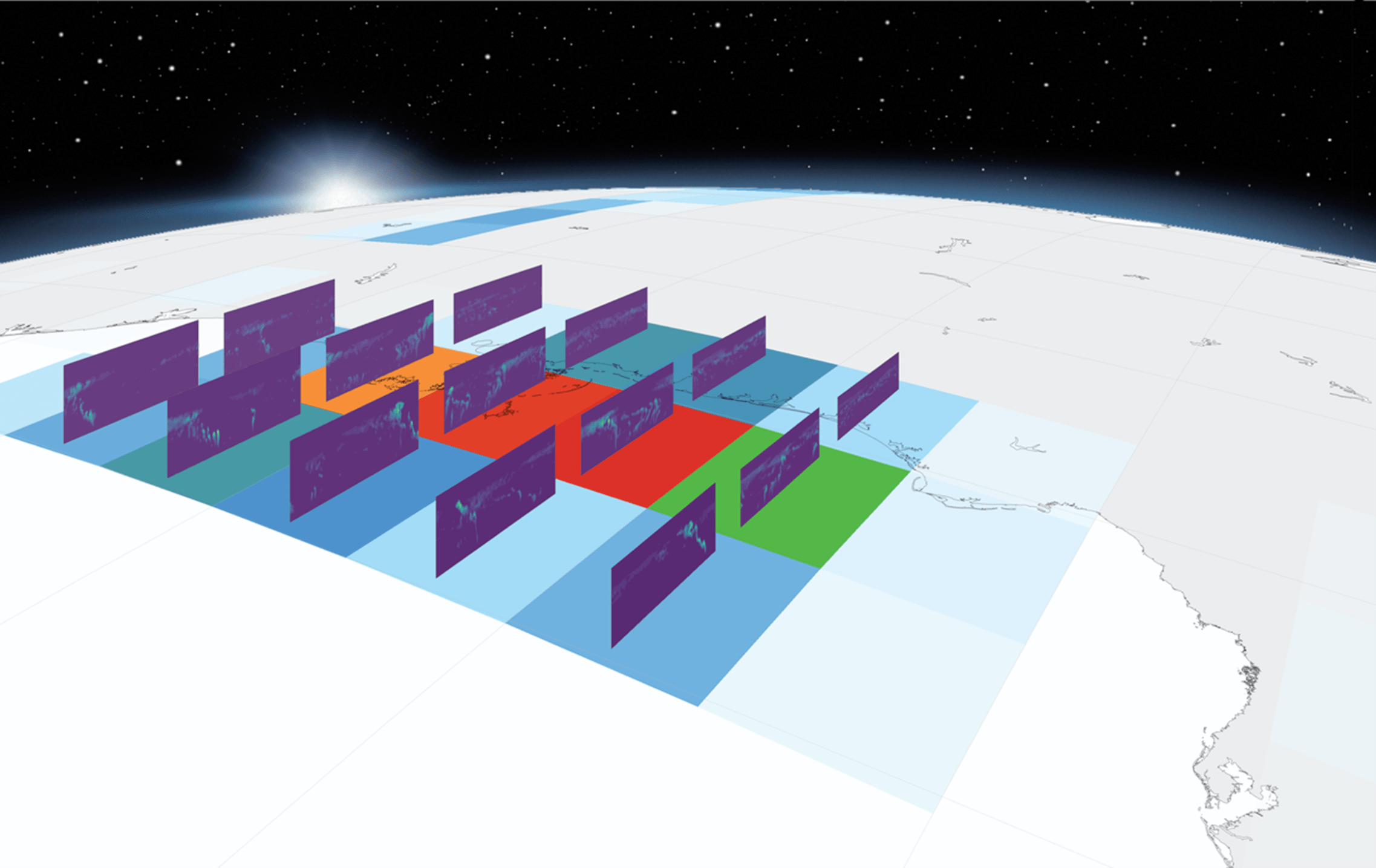
Figure 3. In E3SM-MMF, a 2D CRM represents cloud-scale processes within each cell of a 3D global atmospheric model. The CRM does not fill the entire parent cell of global grid, and thus represents a sample of how the convective-scale processes are responding to the large-scale conditions. The two models are tightly coupled through the exchange of heat and moisture tendencies such that their internal states remain consistent. The figure shown above depicts the approximate size and orientation of the CRM instances (rectangles standing on edge) inside each cell of the global grid from a recent E3SM-MMF simulation. Color shading shows a snapshot of precipitation on the surface of the global grid and the corresponding cloud condensate fields within the CRM instances.
Along with the success of the ECP MMF collaboration, the E3SM project also benefits from other US Department of Energy collaborations, including programs in Climate Model Development and Validation, Scientific Discovery through Advanced Computing, and Atmospheric Radiation Measurement.[9]
A Focus on the Code Base and Programming Frameworks
In working with a nearly 2-million-line Fortran code base, the team must consider several constraints when refactoring and developing new code that can meet the simulation campaign’s requirements. In explaining the motivation for transitioning from SAM to PAM, the E3SM team notes that they are refining the code base to provide the ability to simulate as many scenarios and years of simulated time as possible in a reasonable amount of run time on as many leadership-class computers as possible. Importantly, the code must also be understandable so scientists can modify it to address future simulation campaign needs.[10] Taylor notes, “This is not just a software refactoring effort, as algorithms, run-time characteristics, code portability, and code understandability must all be considered.”
This is not just a software refactoring effort, as algorithms, run-time characteristics, code portability, and code understandability must all be considered. – Mark Taylor
As expressed in the paper, “SAM++: Porting the E3SM-MMF cloud resolving model using a C++ portability library,” a big advantage of focusing on the CRMs is that “they [CRMs] do not directly communicate with one another but rather communicate through the global model. On modern architectures, data movement issues dominate and slow performance far more than floating-point performance. During a global model time step, the column-average of the CRM is forced by its corresponding global model column’s data. At the end of the time step, the CRM gives the global model moist convective tendencies over the time step. In this way, CRMs are coupled tightly with their corresponding global model column.”[11]
Putting this into context, Taylor notes, “The team efficiently targeted a performance-critical component in a nearly 2-million-line Fortran code base to realize the performance capabilities of GPUs while addressing a scientific need because the decoupled nature of the CRM computation eliminates communication and aids parallelism. The greater parallelism gave scientists the ability to increase the resolution of the CRM model while still maintaining reasonable model run times, thereby meeting the need to reduce the uncertainty of the model’s results.”
The team efficiently targeted a performance-critical component in a nearly 2-million line Fortran code base to realize the performance capabilities of GPUs while addressing a scientific need because the decoupled nature of the CRM computation eliminates communication and aids parallelism. The greater parallelism gave scientists the ability to increase the resolution of the CRM model while still maintaining reasonable model run times, thereby meeting the need to reduce the uncertainty of the model’s results. – Mark Taylor
The paper also details the analysis and the team’s programming approach for creating a single code base that is understandable and can run efficiently on GPUs. Specifically, they considered the following:
- Compiler directives (e.g., OpenACC and OpenMP offload): This approach was discarded because it “often interact[s] poorly with modern Fortran constructs such as classes, pointers, and type-bound procedures. Behavior in the presence of modern Fortran constructs is highly compiler dependent and often not well-addressed by directives standards.”[12]
- Domain-specific languages (DSLs): DSLs are a promising approach, but today’s DSLs are typically not general enough to handle any arbitrary calculation or algorithm. Typically, they are tied to a specific method, grid, and/or computational motif.[13]
- Portability libraries: The team adopted a portability library approach because the “advantage of using a C++ portability library is that the porting process results in a single-source code that can run on various architectures and can more easily and quickly be extended to new computing architectures by developers without relying on compiler implementation or having to edit multiple source codes.”[14]
GPU-Accelerated Exascale Fortran Codes via the C++ YAKL Library
Based on this analysis, the E3SM-MMF team used the Yet Another Kernel Library (YAKL), which is a simplified C++ portability library that specializes in Fortran porting. The primary reason for selecting a C++ portability approach is cited as such: “Because C++ can encapsulate code as an object, it can then send the same code object to different launchers for different hardware back ends. In Fortran, the developer must rely on compilers to do all of this, but in C++, it’s fairly easy to code different hardware launchers that can accept any code.”[15]
For porting, the team targeted the workhorse sections of the Fortran codes. These sections are tightly nested loops expressed to YAKL as parallel_for constructs and described in the C++ code via functors, which are wrapped by the programmer as lambda functions. A functor is a C++ class with an overloaded operator() function. Lambda functions are a convenient way to define and pass anonymous functions to boilerplate functions that—when designed correctly—only need to be written once. This locality of definition facilitates code readability and maintainability across many hardware platforms because everything can be nicely organized in once place. The generality of passing anonymous functions to boilerplate code facilitates portability because the programmer must only meet the requirements of the boilerplate code. The result is a Fortran-callable parallel_for method that can launch the appropriate lambda functions across different hardware platforms.
YAKL also includes features such as a pooled memory allocator, which reduces the cost of repeated allocate and free operations (common when using dynamic memory inside a function), and Fortran iso_c bindings, which are used in YAKL to share memory between the two languages. The team notes, “In addition to the aforementioned features, C++ portability libraries also consist of constructs for handling data races. Data races are situations in which one parallel thread can potentially write to a data location that is read from or written to simultaneously by another thread.”[16]
Please consult the SAM++ paper for a detailed description of how and why the portability library approach was chosen to port the code and to support systematic result reproduction and correctness testing. The paper also includes a detailed explanation of why a gradual porting process was utilized. In essence, a gradual porting approach avoids the need for a labor-intensive and potentially error-prone code rewrite.
Fortran Performance Portability with the C++ YAKL Library
Of course, performance becomes paramount once code correctness has been established.
Single-node CPU and GPU performance for the E3SM-MMF model’s CRM component was evaluated on the Summit supercomputer and on Crusher, which is the OLCF’s Frontier testbed, in preparation for running on exascale hardware when it becomes available.
Portability was demonstrated by running the component on two distinct hardware architectures. The Summit supercomputer utilizes IBM POWER9 CPUs and NVIDIA V100 GPUs,[17] and Crusher has identical hardware and similar software to Frontier, which utilizes 3rd-generation AMD EPYC CPUs and AMD Instinct MI250X accelerators.[18]
According to the 59th edition of the TOP500 list, the preproduction Frontier system recently made history as the first true (double precision) exascale machine with a 64-bit High Performance Linpack (HPL) score of 1.102 exaflop/s.[19]
The benchmark data is plotted in Figure 4 as time to solution (wall time) as a function of workload (lower is better). The workload is the number of CRMs running per node on the CPU or per GPU. Two CRM configurations are shown: 1-moment microphysics (denoted by 1mom) and the more expensive 2‑moment microphysics (denoted by P3).
The results demonstrate that the C++/YAKL implementation outperforms the Fortran/OpenACC and Fortran/OpenMP versions. It also obtains good speedup, with a single V100 GPU outperforming a dual-socket POWER9 node and a single GPU of a MI250X card outperforming a single-socket EPYC node. These results demonstrate the accelerated performance of the GPU port. The “SAM++ 1mom” results are C++/YAKL code, whereas the “GPU(P3)” results are C++ with both YAKL and Kokkos subcomponents.
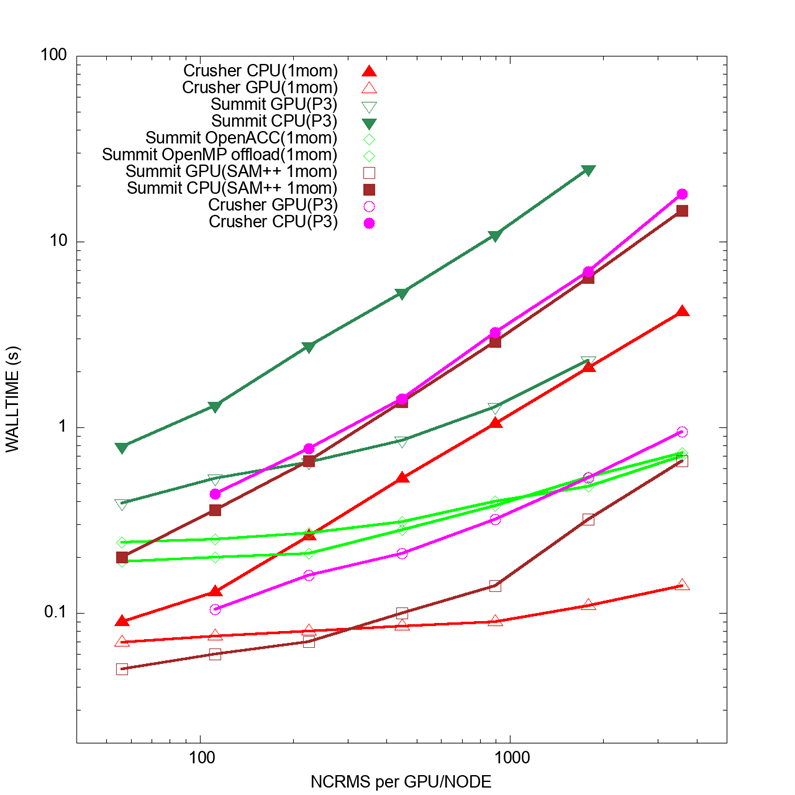
Figure 4. Single-node CPU and single GPU performance for the E3SM-MMF model’s CRM component.
Kokkos was evaluated by the team as a possible alternative to YAKL, as noted in the October 2021 SAM++ paper, “Future considerations will also include switching the portability library to Kokkos rather than YAKL to take advantage of the more robust portability framework as well as future improvements.”[20]
Even with a planned transition to Kokkos for the portability library, the YAKL results have so far been sufficiently strong, and Taylor notes, “Currently, the components of the project that are using YAKL are working very well across three different GPU vendors. In addition, at the component level, YAKL and Kokkos have proven to work well together with no interoperability issues so far. We are planning to increase our use of YAKL in other model components. In the future, we expect to continue to have a mix of YAKL and Kokkos components and subcomponents.”
Currently, the components of the project that are using YAKL are working very well across three different GPU vendors. In addition, at the component level, YAKL and Kokkos have proven to work well together with no interoperability issues so far. We are planning to increase our use of YAKL in other model components. In the future, we expect to continue to have a mix of YAKL and Kokkos components and subcomponents. – Mark Taylor
Scalability Test Results
These CRM performance results validate the software approach taken by the team and demonstrate that single-node performance will not be an issue on the forthcoming exascale systems. According to Taylor, “In the MMF concept, we get some aspects of cloud resolving but with the throughput necessary for climate applications. With the traditional approach of uniformly increasing the resolution, the time to solution becomes intractable. With MMF, we can run key components at high resolution for long simulation times while realizing reasonable supercomputer run times.”
The next step is to validate the E3SM-MMF model’s scaling behavior, which dictates how much of the machine can be efficiently used. Exascale systems rely on the efficient interconnection of many computational nodes to achieve high performance in large-scale simulations.
The strong scaling behavior of the E3SM-MMF model was tested with a 1 km resolution CRM convective parameterization running within a 84 km ( 0.75◦) and 28 km (0.25◦) resolution global model. Figure 5 shows SYPD as a function of the number of Summit nodes. The red-dashed curve shows the CPU performance running with 42 MPI (Message Passing Interface) tasks per node. The solid curves show the GPU performance at 84 km (red) and 28 km (blue) resolutions, each running with 6 MPI tasks per node accessing 6 GPUs per node. Perfect strong scaling is denoted by the solid-black line. The solid-red line reflects the scaling of an 84 km global model with the cloud-resolving convective parameterization, which can achieve 10 SYPD with GPU acceleration. This GPU-accelerated performance makes it possible to perform multidecadal climate simulations in a reasonable amount of wall clock time.
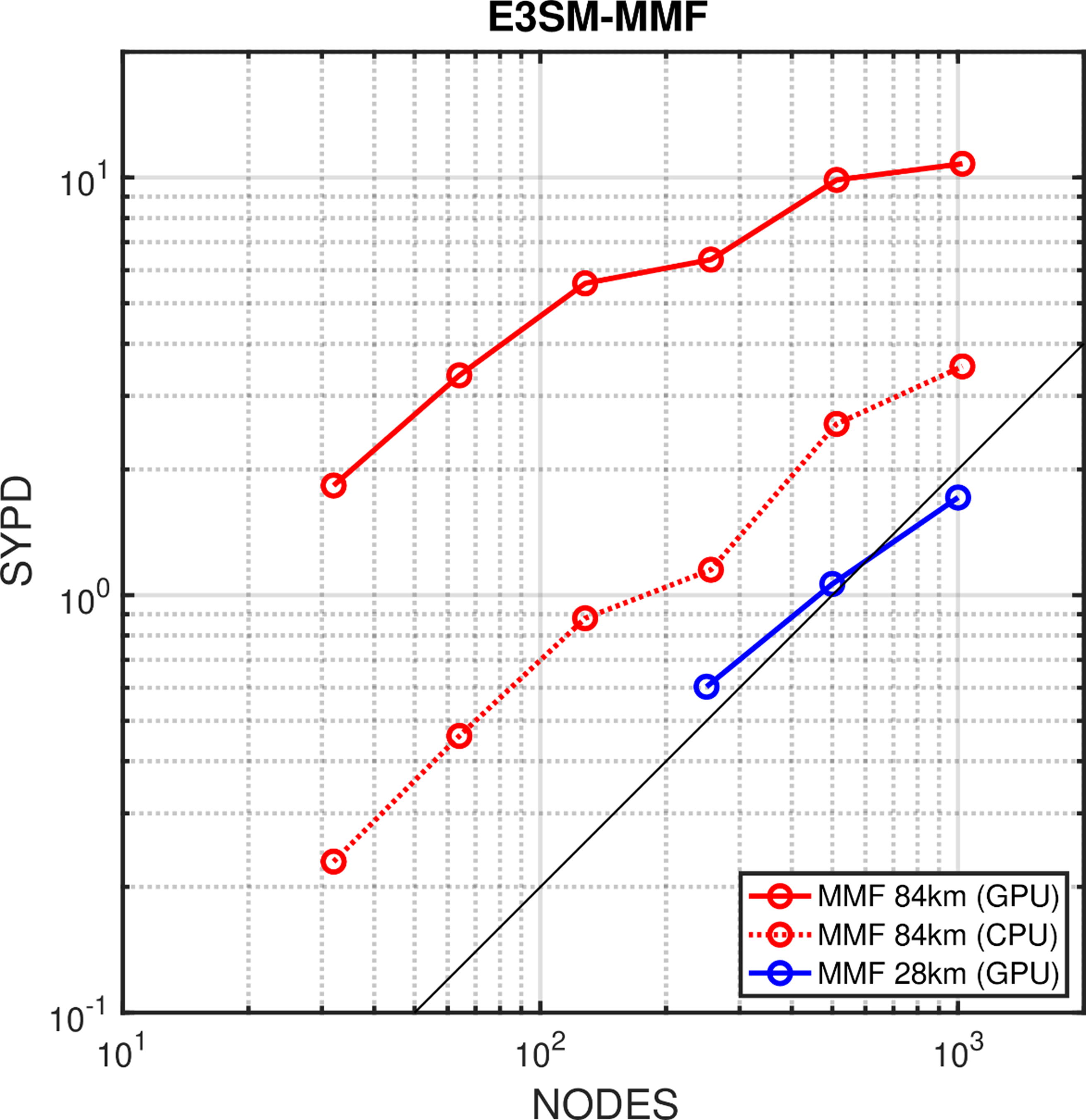
Figure 5. Strong scaling of the E3SM- MMF model with a 1 km resolution CRM convective parameterization running within a 84 km ( 0.75◦) and 28 km (0.25◦) resolution global model, showing simulated-years-per-day (SYPD) as a function of the number of Summit nodes.
Summary
The performance and GPU scaling results demonstrate the efficacy of the E3SM-MMF effort. Utilizing ECP funding, the team
- efficiently targeted a performance-critical component in a multimillion-line code base to realize the performance capabilities of GPUs;
- addressed a scientific need insofar as the decoupled nature of the CRM computation eliminates communication and aids parallelism;
- harnessed the performance potential of GPUs to increase the resolution of the CRM model while maintaining reasonable model run times, thereby reducing the uncertainty of the model results; and
- successfully merged simulation components running at differing resolutions.
This research was supported by the Exascale Computing Project (17-SC-20-SC), a joint project of the US Department of Energy’s Office of Science and National Nuclear Security Administration, responsible for delivering a capable exascale ecosystem, including software, applications, and hardware technology, to support the nation’s exascale computing imperative.
Rob Farber is a global technology consultant and author with an extensive background in high-performance computing and in developing machine learning technology that he applies at national laboratories and commercial organizations.
[1] https://e3sm.org/research/science-campaigns/
[2] Discussed in detail in https://journals.sagepub.com/doi/abs/10.1177/10943420211044495.
[3] https://journals.sagepub.com/doi/abs/10.1177/10943420211044495
[4] https://e3sm.org/research/science-campaigns/
[7] https://journals.sagepub.com/doi/pdf/10.1177/10943420211027539
[8] https://e3sm.org/improving-clouds-in-e3sm-with-a-multi-scale-modeling-framework/
[9] https://newsreleases.sandia.gov/exascale_models/
[10] https://agu.confex.com/agu/fm21/meetingapp.cgi/Paper/938397
[17] https://www.olcf.ornl.gov/wp-content/uploads/2018/05/Intro_Summit_System_Overview.pdf
[18] https://www.amd.com/en/press-releases/2022-05-30-world-s-first-exascale-supercomputer-powered-amd-epyc-processors-and-amd
[19] https://www.top500.org/news/ornls-frontier-first-to-break-the-exaflop-ceiling/