By Rob Farber, contributing writer
“The storage world has changed,” observed Rob Ross (Figure 1), principal investigator of the DataLib project, senior computer scientist, and R&D leader at Argonne National Laboratory. “In recognition of this, the Exascale Computing Project’s (ECP’s) DataLib effort was created to develop software to help scientists use storage and very large volumes of data as part of their activities.” The impact is significant explained Ross, “The DataLib group members are responsible for some of the most successful storage and I/O software in the [US Department of Energy (DOE)] complex because they decided to think beyond traditional checkpoint and restart and consider storage as a service that extends beyond a traditional file system. Storage is a pillar of [high-performance computing (HPC)]. This new way of thinking is reflected in the many ECP dependencies on DataLib.” DataLib encompasses three groups of users: applications, facilities, and software teams.
The storage world has changed. In recognition of this, ECP’s DataLib effort was created to develop software to help scientists use storage and very large volumes of data as part of their activities. The DataLib group members are responsible for some of the most successful storage and I/O software in the DOE complex because they decided to think beyond traditional checkpoint and restart and consider storage as a service that extends beyond a traditional file system. Storage is a pillar of HPC. This new way of thinking is reflected in the many ECP dependencies on DataLib. — Rob Ross

Figure 1. Rob Ross.
The team’s excellent track record includes the Darshan project, which is a lightweight characterization tool for observing application I/O patterns, and the Mochi tool suite, which is a toolkit for building high-performance distributed data services for HPC platforms. Darshan won an R&D 100 award in 2018, and Mochi won an R&D 100 award in 2021. The team also works on Parallel NetCDF (PnetCDF), which is heavily utilized in climate and weather applications.
“The forward-thinking approach taken by the group,” Ross reflected, “had a significant impact on the success of these storage and I/O software projects and the benefits they deliver to the HPC and national security communities.” The impacts include the following:[1]
- supporting and extending packages that scientists can use to access and share data across all the different platforms on which they work;
- employing tools that reveal how scientists are using their data, thereby providing information to troubleshoot problems at facilities and to better configure future systems; and
- enabling researchers within the DOE’s Advanced Scientific Computing Research (ASCR) programs through DataLib tools to build entirely new specialized data services to replace tools that are either too difficult to use or too slow.
The Evolution of Storage as a Data Service
“When we were proposing the DataLib work back in 2015,” Ross recalled, “we noticed our work was focused on parallel file systems and I/O middleware, which meant we were mainly acting on user requests about storage and I/O. Our team recognized we could broaden our approach by addressing storage issues as a data service, which an organization can then use to manage a variety of different types of data as desired and often with a particular purpose in mind.”
He continued, “Storage is intimately tied to data utilization and hardware, both of which are becoming increasingly complicated. To meet this need, we realized we had to raise awareness of how applications interact with storage systems and how users can efficiently use existing tools. In the face of rising complexity, we have to make it easier for users to develop new tools that can do a better job meeting their application needs and can better map to hardware. A data service can adapt to meet current and future needs.”
The Community Model for Infrastructure
Consulting and research go hand in hand. Ross noted that the team has been working in this space and tracking applications for a long time, since 2000. He observed, “We are constantly working with research teams, understanding their problems (both to help them and us), and using those interactions to drive future research and software efforts. One example is Mochi, which was motivated by the recognition of a need for new data services and a tool set to help develop those services.” According to Ross, “Traditionally, it has taken too long to create these services. The HPC community cannot wait a decade for the next Lustre.“
We are constantly working with research teams, understanding their problems (both to help them and us), and using those interactions to drive future research and software efforts. One example is Mochi, which was motivated by the recognition of a need for new data services and a tool set to help develop those services. Traditionally, it has taken too long to create these services. The HPC community cannot wait a decade for the next Lustre. — Rob Ross
Outreach is extremely important. The DataLib team leverages the community model to make all their accumulated knowledge available to vendors, facilities, and users. “The community model complements our efforts” Ross observed. “For our research teams to be effective, they need to have one foot in the deployment and application and the other in the applied research and development. This provides significant benefits to DOE, the Office of Science, and the open HPC community—both academic and commercial. Very simply, you cannot compute fast if you cannot access data from storage.” Ross also pointed out the significant security benefits that can be realized through the community model, a need that is becoming ever more urgent given the ubiquity of global internet access. This approach is reflected in other key infrastructure efforts, as described in the article, “The PETSc Community is the Infrastructure.”
Additionally, the team surveys their users, holds quarterly meetings for Mochi, runs sessions at the ECP Annual Meeting, and organizes full-day events at the Argonne Training Program on Extreme-Scale Computing and at the International Conference for High Performance Computing, Networking, Storage, and Analysis to share their expertise on the DataLib tools and on the broader subject of I/O in HPC. Furthermore, the team also meets one-on-one with users when needed, such as with E3SM.
Understanding DataLib through Exemplar Use Cases
The DataLib forward-thinking projects can be roughly categorized by use case, including file systems, alternative data models, in-situ data analysis, data monitoring to understand workflow performance (e.g., Darshan), and toolkits to build distributed data services (e.g., Mochi). For example, the team methodically assesses the use of HDF5 (Hierarchical Data Format version 5) in ECP and is building new internal HDF5 back ends that target key use cases.
User-Level File Systems
File systems are generally the first thing that most people talk about when thinking about storage. Extraordinary performance benefits are being realized by eliminating POSIX file system bottlenecks that can serialize storage access and user space.
One of the highest profile efforts is the Distributed Asynchronous Object Store (DAOS) software that will be used as the primary storage mechanism on the Aurora exascale supercomputer. While the DataLib team hasn’t played a central role in the development of DAOS, the team is working to integrate and work with DAOS (Figure 2), which is an extensive open-source project with many collaborators.
Owing to the efforts of this open-source project, the DAOS software has already delivered record-setting performance on HPC hardware.
The DataLib team is looking at the DAOS software, which can be accessed in two ways:
- DAOS supports direct access to storage from the application via the (libdfs) user space library. Key HPC tools such as HDF5, MPI-IO, and TensorFlow leverage this capability. Results reported at the 2022 ISC High Performance conference, for example,show that DAOS outperforms Lustre when loading a large AI dataset into TensorFlow.[2]
- DAOS also supports traditional HPC workloads that access data through a user space file system mount point, and this is enabled via an interception library. Running the file system in user space eliminates significant operating system overhead, including the unavoidable context-switch overhead of a kernel system call plus the internal operating system overhead that is required to manage the internal kernel file system and block caches.[3]
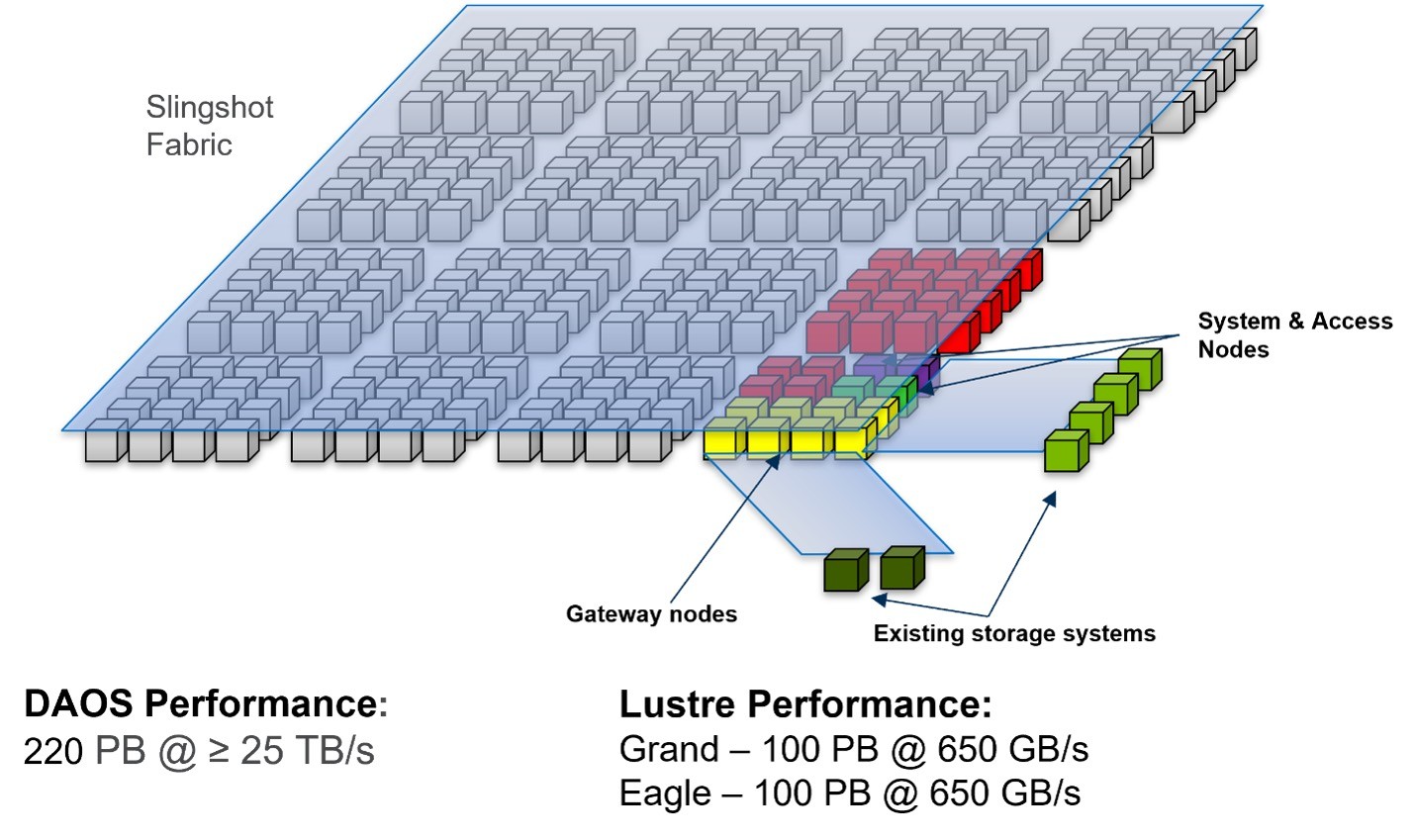
Figure 2. Aurora DAOS Overview.
Deviating from POSIX, DAOS implements an alternative relaxed consistency model in both data and metadata that permits HPC codes to exploit the available concurrency. This concurrency is implemented in hardware through node-local and embedded storage devices. Internally, DAOS uses a key-value architecture that avoids many POSIX limitations and differentiates DAOS from other storage solutions with its low-latency, built-in data protections, and end-to-end data integrity while delivering increased single-client performance.
Importantly, the key-value architecture makes DAOS fully distributed, with no single-point metadata bottleneck, and gives the node full control per dataset over how the metadata is updated. This highly scalable approach particularly benefits workloads in which small file, small I/O, and/or metadata operations per second (IOP/s) performance is critical. The key-value approach also maps nicely to the cloud, which means application codes can readily move to new platforms—including HPC applications that run in the cloud—and be applied to a wide range of different problems.
The DataLib team also works with other filesystems such as GekkoFS a burst-buffer temporary file system, and UnifyFS as they use DataLib components to build their products. The team is working to make improvements to ROMIO to speed MPI-IO and HDF5 support on the Frontier burst buffer hardware, which uses UnifyFS.
Use Case: In-Situ Analysis
Visualization and analysis on any HPC system faces a last-mile problem in which the potential of the resource can only be realized when people have the tools to examine and interpret the data created on these powerful machines. In-situ analysis and visualization can enable access to simulation data on the supercomputer while the simulation is still running (Figure 3). This approach addresses the compute vs. storage dichotomy that exists on current HPC systems, a dichotomy that will become progressively worse on more powerful supercomputers. For example, the new exascale systems will increase computational concurrency by roughly 5–6 orders of magnitude, while system memory and I/O bandwidth will only grow by 1–2 orders of magnitude.[4] The ECP is addressing this last-mile problem and the compute-to-storage dichotomy with tools such as Cinema that provide an in-situ infrastructure.[5]
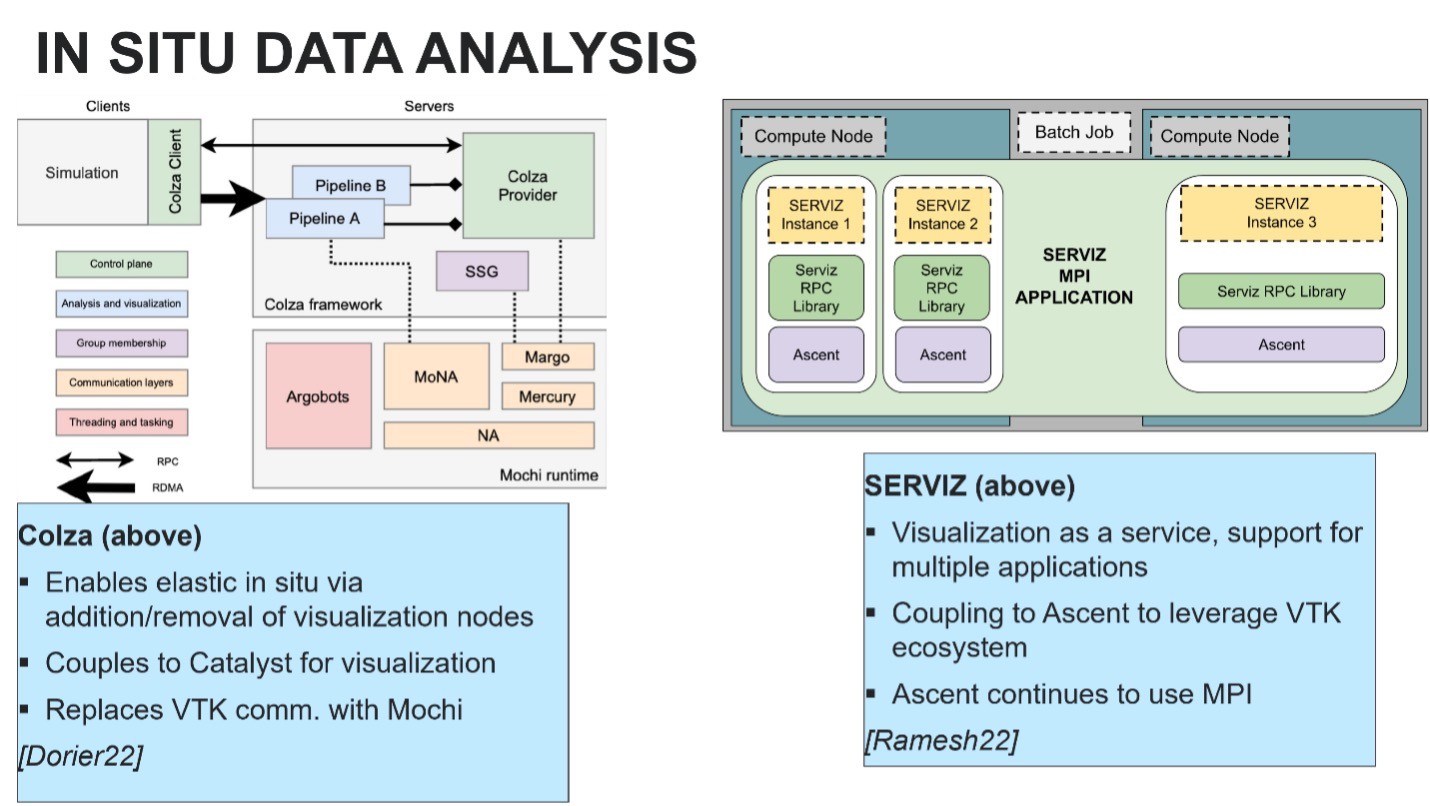
Figure 3. In-situ data analysis overview.[6]
Use Case: Data Monitoring
The complexity of modern storage usage requires an ability to characterize and understand application I/O behavior. This is critical to ensuring efficient use of the evolving and increasingly complex HPC I/O stack. Without such information, the application developer can only make educated guesses. More precisely, I/O analysis tools are invaluable in helping the developer navigate the complexity of the many layers of the I/O stack and new-to-HPC storage paradigms such as object storage and burst buffers.
The Darshan I/O characterization tool was created to capture concise views of an HPC workload’s I/O behavior. It does not require any code changes to instrument a code and has a negligible run time impact, so Darshan is generally “just left on”, which explains why it is widely deployed at HPC datacenters.
A winner of a 2018 R&D 100 award, Darshan enables users and system managers to characterize the I/O behavior of individual jobs so users can make better tuning decisions by characterizing job populations to better understand system-wide I/O stack usage and optimize deployments.[7] For more information, consult the Darshan project website (particularly the extensive publications list), the 2021 presentation “Understanding Application I/O Behavior with Darshan,” and the paper, “Understanding and Improving Computational Science Storage Access through Continuous Characterization.”
Use Case: Distributed Data Services
Mochi arose from the recognition that HPC storage and I/O are dominated by parallel file systems. This has created a situation where teams have to adapt their storage usage to the parallel file system model. Mochi allows instantiation of the data services model advocated by the DataLib team.
As Ross explained, “Mochi is designed to change that file system worldview with a model that encourages the development of data services that are tailored to the needs of applications and workflows. An opportunity exists in leveraging the reusability of the Mochi components so there is actually less software development than is typical in adapting a workflow to a parallel file system.”
Mochi is designed to change that file system worldview with a model that encourages the development of data services that are tailored to the needs of applications and workflows. An opportunity exists in leveraging the reusability of the Mochi components so there is actually less software development than is typical in adapting a workflow to a parallel file system. – Rob Ross
Ross presented DeltaFS as a 5,000× performance improvement to highlight the value of Mochi. The work was performed by members of Carnegie Mellon University and Los Alamos National Laboratory who used ASCR R&D funding to provide scientists with greater insight to support the Stockpile Stewardship Program. Wired Magazine highlighted this work, including its world record file creation rate, in “This Bomb-Simulating US Supercomputer Broke a World Record.”
DeltaFS was created as a data service to help research teams understand the results from a first-principles, kinetic-plasma vector–particle-in-cell (VPIC) plasma physics code. This simulation code frequently runs at large scale on Advanced Technology Systems[8] such as Trinity (ATS-1). These simulations often model trillions of particles and require months of continuous run time. Ross noted, “By performing in-situ indexing of particle data, particle tracks of interest can be identified 5,000× faster than in their previous workflow.” In situ visualization is used to analyze and visualize the resulting simulation data.
As discussed in the paper, “Mochi: Composing Data Services for High-Performance Computing Environments,” the Mochi framework provides a methodology and tools for communication, data storage, concurrency management, and group membership for rapidly developing distributed data services. Mochi components provide remotely accessible building blocks that have been optimized for modern hardware. Together, these tools enable teams to quickly build new services that cater to the needs of specific applications (Figure 4).
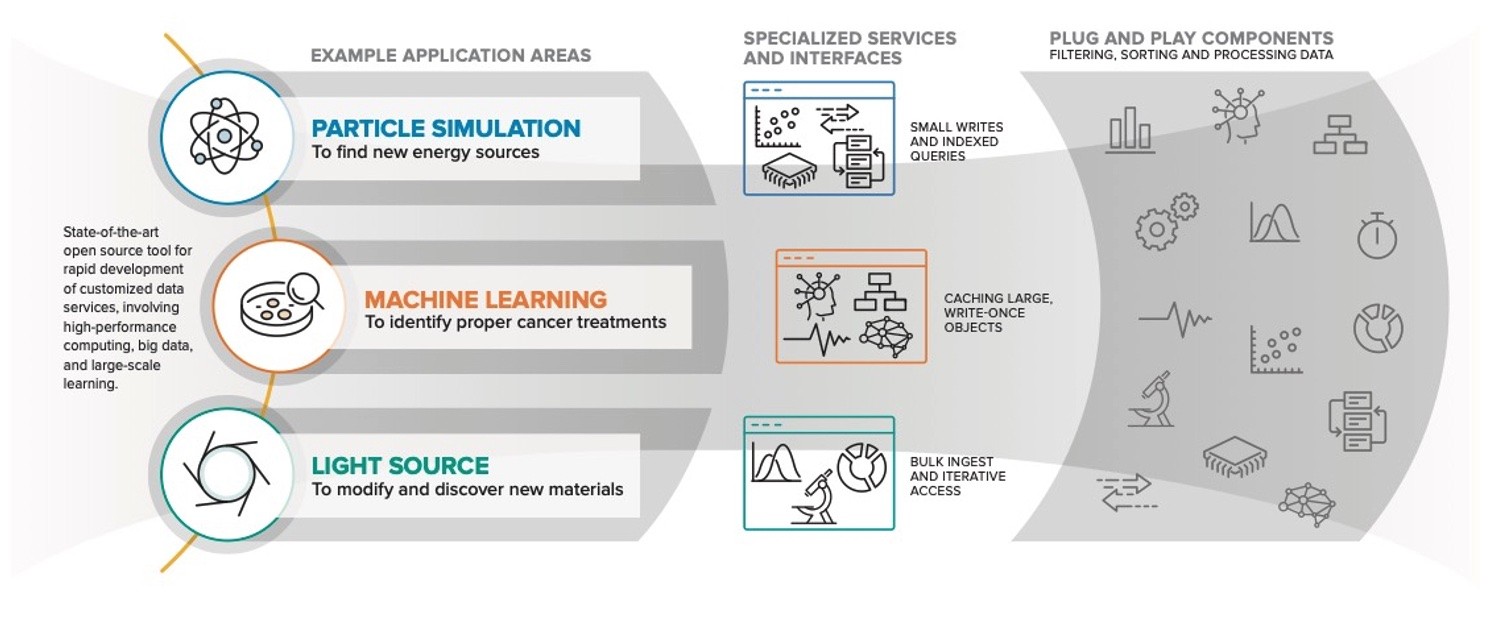
Figure 4. Example Mochi application areas.
The DeltaFS project used these components to create a distributed file system that runs in user space as a customizable service. Resources dedicated to DeltaFS can be customized by application workflows to provide sufficient metadata performance and in-situ data indexing. The effectiveness of DeltaFS was demonstrated across more than 130,000 CPU cores on Los Alamos National Laboratory’s Trinity supercomputer by using a VPIC code to perform a 2-trillion particle simulation, as discussed in “Scaling Embedded In-Situ Indexing with DeltaFS” and illustrated in Figure 5.
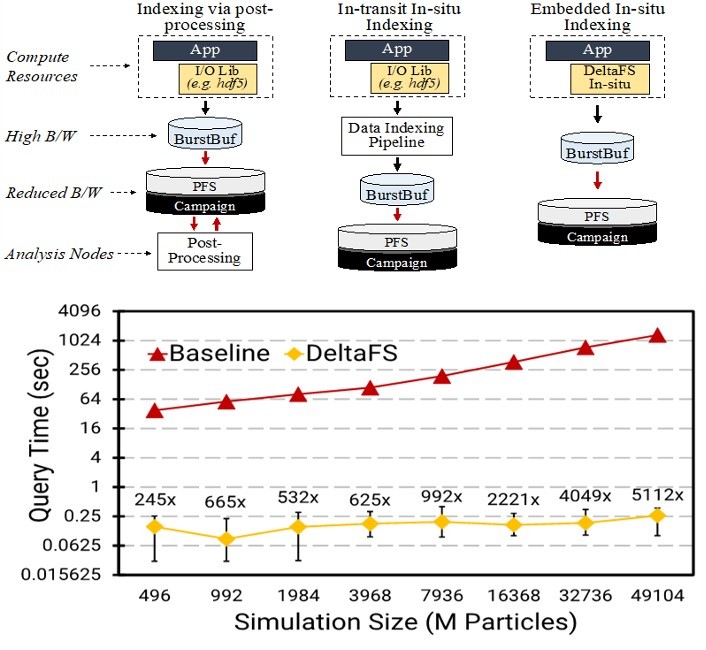
Figure 5. Indexing during post-processing is becoming increasingly time-consuming for exascale applications. Current state-of-the-art methods avoid post-processing but require extra resources to process the data in situ. DeltaFS’s in-situ indexing shifts from using dedicated resources to using spare resources on the computational nodes. The result is a 3+ orders of magnitude improvement in query speed.
The Forces Driving Storage Innovation
So what forces are driving this innovation? As Ross explained, “Think about new applications and external data sources such as ML and AI, hybrid applications such as simulation codes coupled with AI, In situ visualization, etcetera (Figure 6). These are very different from checkpoint/restart, which is well understood and is currently being accelerated with burst buffer hardware. Many technology changes are driving expansions from this legacy storage view. Modern applications require different optimizations and complex data layouts. They expand the range of requirements needed to help HPC.”
He continued, “Overcoming user inertia is important, which means accepting new viewpoints. Education is important as is the community model. People need to understand and apply cloud-based storage model success stories (e.g., object storage, key-value, column store) as the cost models are now very different. Users cannot assume that you can wait while an I/O operation completes, nor can people assume that streaming I/O will be faster than random access.
Ross concluded by noting, “Mochi addresses these issues. A research prototype is a gamble. We understand this and are working to overcome user inertia while leveraging technology innovation. We are also working to identify which teams are amenable to working with a prototype. The big question that needs to be answered is what is the opportunity and how can we exploit it?”

Figure 6. Understanding data services and Mochi.
Expanding beyond the DeltaFS success story, Ross described three ways that Mochi enables data service development for DOE science and computing platforms.
- Scientific Achievement: Mochi has enabled many DOE computer science teams and industry to build new data services more rapidly through a thoughtful design methodology with reusable components.
- Significance and Impact: Data services traditionally took many years to develop and productize. The Mochi project is shortening this development cycle, thereby allowing teams to develop services specialized for their needs while still enabling significant component reuse.
- Technical Approach: Mochi is built using proven remote procedure call, remote direct memory access, and user-level threading. The team has defined a methodology for design of services using common components wherever possible, that provides numerous typical capabilities via reusable components, and enables exploratory approaches to configuration and optimization that can, as demonstrated by DeltaFS, deliver significant benefits in gaining scientific insight on important problems.
Recent Work
The DataLib project has been interacting with the ECP ExaHDF team to adapt log-structured filesystem technology to the very popular Hierarchical Data Format version 5 (HDF5). HDF5 is a widely used parallel I/O library at leadership supercomputing facilities and tuning parallel I/O performance benefits a large number of applications.[9] As noted by Byna et al. in “Tuning HDF5 subfiling performance on parallel file systems,” a parallel, log-structured file system remaps application data into a layout of multiple files to provide better performance on a given file system. The DataLib team has also been augmenting Darshan to capture more information on HDF use to benefit HDF performance overall.
Darshan originally focused on MPI-IO and POSIX. Currently, Darshan can be used to insert application I/O instrumentation at link-time (for static and dynamic executables) or at run time by using LD_PRELOAD (for dynamic executables). Starting in version 3.2.0, Darshan supports instrumentation of any dynamically linked executable (MPI or not) by using the LD_PRELOAD method.[10] During run time, Darshan records file access statistics for each process as the application execution. During application shutdown, this data is collected, aggregated, compressed, and written to a log file that Darshan can then analyze.
The HDF5 instrumentation (available since Darshan 3.2.0) can provide informative displays of HDF5 behavior, such as the average time spent in I/O. Figure 7 shows two examples that demonstrate when POSIX and MPI-IO collective behavior dominate the run time in a 60-process (5-node) 3D mesh application running on the Cori supercomputer at the National Energy Research Scientific Computing Center. In this example, Cori wrote roughly 1 GB of cumulative H5D data by using HDF5.
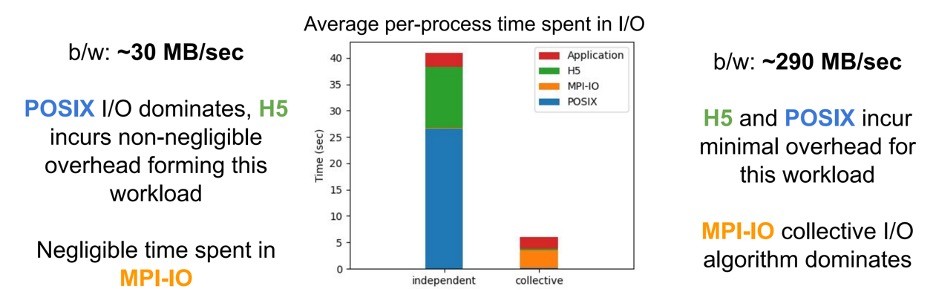
Figure 7. Average I/O example. Measured H5 time includes time spent in the HDF5 file and dataset interfaces. (Source https://www.mcs.anl.gov/research/projects/darshan/wp-content/uploads/sites/54/2021/10/snyder-nersc-data-seminar.pdf).
Using the HDF5 plugin, Darshan can also generate radar plots, which are an excellent way to visualize run-time characteristics of HDF5 dataset accesses (Figure 8). These plots can be used to help set and/or optimize chunking parameters to limit accesses to as few of the chunks as possible.
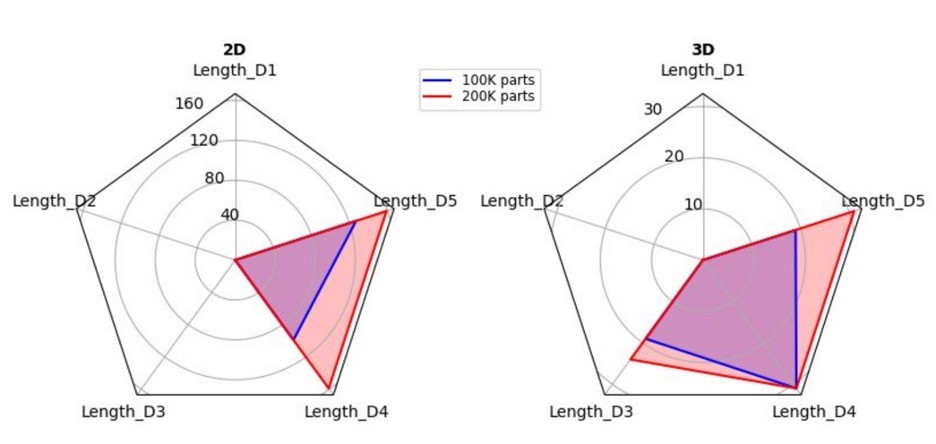
Figure 8. Using the HDF5 plugin, Darshan can generate radar plots. (Source https://www.mcs.anl.gov/research/projects/darshan/wp-content/uploads/sites/54/2021/10/snyder-nersc-data-seminar.pdf).
Using output from the Drishti tool developed by Lawrence Berkeley National Laboratory, users can also derive meaningful information from the Darshan logs by detecting root causes of I/O bottlenecks, mapping I/O bottlenecks into actionable items, and guiding the end user to tune I/O performance.
For more information and recommendations on example problems, see Bez et al.’s “Drishti: Guiding End-Users in the I/O Optimization Journey” and the companion presentation by the same name.
Community Response
Overall, Ross noted that “the community response has been outstanding. Mochi uptake in particular is exciting.” The extent of Mochi’s adoption can be seen by the number of institutions listed in Figure 9.
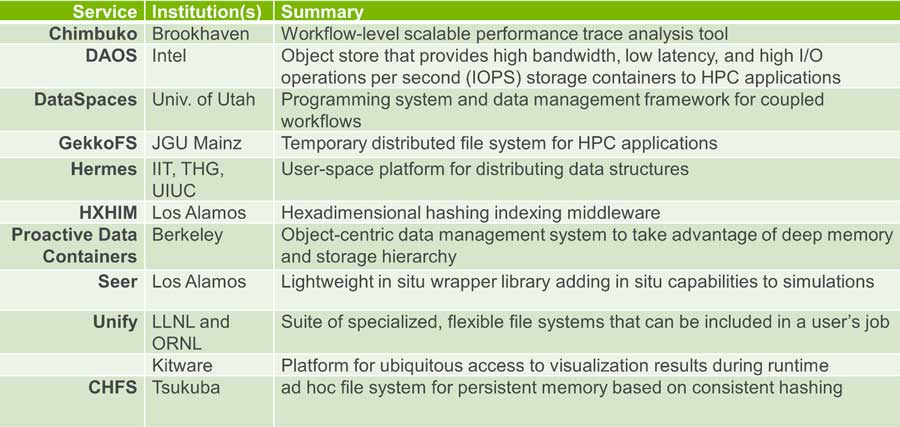
Figure 9. Extent of community uptake.
Summary
As Ross said, “storage is a pillar of HPC,” and this new way of thinking about storage is reflected in the award-winning work by the DataLib team to advance the state of the art in using and understanding I/O in an HPC environment. Furthermore, the team is working with tools such as Drishti (developed by Jean Luca Bez at LBL) to help guide users toward optimized I/O behavior.
This research was supported by the Exascale Computing Project (17-SC-20-SC), a joint project of the US Department of Energy’s Office of Science and National Nuclear Security Administration, responsible for delivering a capable exascale ecosystem, including software, applications, and hardware technology, to support the nation’s exascale computing imperative.
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national laboratories and commercial organizations.
[1] https://www.exascaleproject.org/helping-scientists-create-and-use-very-large-volumes-of-data-in-ecp-activities/
[2] https://www.youtube.com/watch?v=TfJf0ayqNto
[3] https://link.springer.com/chapter/10.1007/978-3-030-48842-0_3
[4] https://www.exascaleproject.org/supporting-scientific-discovery-and-data-analysis-in-the-exascale-era/
[5] https://www.exascaleproject.org/highlight/visualization-and-analysis-with-cinema-in-the-exascale-era/
[6] This is a combination of figures from:
- Dorier, Matthieu, et al. “Colza: Enabling elastic in situ visualization for high-performance computing simulations.” 2022 IEEE International Parallel and Distributed Processing Symposium (IPDPS). IEEE, 2022.
- Ramesh, Srinivasan, Hank Childs, and Allen Malony. “Serviz: A shared in situ visualization service.” 2022 SC22: International Conference for High Performance Computing, Networking, Storage and Analysis (SC). IEEE Computer Society, 2022.
[7] https://www.mcs.anl.gov/research/projects/darshan/wp-content/uploads/sites/54/2021/10/snyder-nersc-data-seminar.pdf
[8] https://www.lanl.gov/projects/trinity/_assets/docs/atcc-policy.pdf
[9] https://escholarship.org/content/qt6fs7s3jb/qt6fs7s3jb.pdf
[10] https://www.mcs.anl.gov/research/projects/darshan/wp-content/uploads/sites/54/2021/10/snyder-nersc-data-seminar.pdf