By Rob Farber, contributing writer
Stencils are a fundamental computational pattern in many parallel distributed HPC algorithms, notably grid-based and finite element methods. Succinctly, stencils define the geometric arrangement of a set of points around a point of interest for computations such as a numerical approximation routine. They are ubiquitous in scientific simulations that solve partial differential equations and hence are a core part of HPC and exascale supercomputing applications. Figure 1 illustrates example 1D, 2D, and 3D stencils and how they can impact HPC application performance. [i]

Figure 1: Example 1D, 2D, and 3D stencils where the colored blocks provide a visual aid to distinguish point distance from the central point of interest. (Source: https://www.nitrd.gov/nitrdgroups/images/2/28/FACE-Mary-Hall-082020.pdf)
As part of the PROTEAS-TUNE effort inside the Exascale Computing Project (ECP), University of Utah PhD student Tuowen Zhao, together with his advisor Mary Hall (Director of the School of Computing at the University of Utah) and Lawrence Berkeley National Laboratory collaborators Sam Williams and Hans Johansen, has focused on creating a domain specific language (DSL) that can be used to implement stencil calculations on logically regular grids in a distributed environment using MPI in a performance-portable manner. Hall notes that “the DSL framework is designed to work extremely well in CPU, GPU, and hybrid CPU/GPU environments, which fits with the needs of the ECP HPC and exascale systems. Reducing data movement is not a new idea but can dominate both power consumption and application performance. In conjunction with autotuning, applications can achieve performance portability with this DSL without significant additional human investment.”
The DSL framework is designed to work extremely well in CPU, GPU, and hybrid CPU/GPU environments, which fits with the needs of the ECP HPC and exascale systems. Reducing data movement is not a new idea but can dominate both power consumption and application performance. In conjunction with autotuning, applications can achieve performance portability with this DSL without significant additional human investment. – Mary Hall, Director of the School of Computing at the University of Utah
The primary concept behind the DSL is to eliminate the data movement associated with packing and unpacking subsets of the data during communication. Instead, the DSL uses a construct in the literature for fine-grained data blocking using code generators called bricks[ii] [iii], (and sometimes briquettes[iv]) as illustrated in Figure 2.
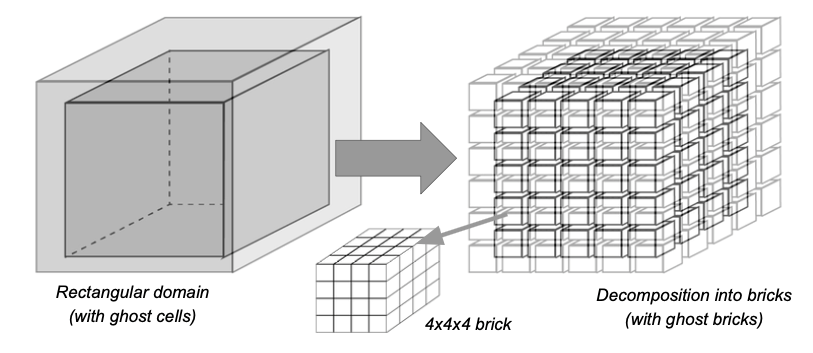
Figure 2: Example of how the DSL views a large block of data, which is decomposed into fixed size bricks. (Source: https://www.nitrd.gov/nitrdgroups/images/2/28/FACE-Mary-Hall-082020.pdf)
Hall’s team observed that there are two types of data movement arising from stencil operations as illustrated in Figure 3.
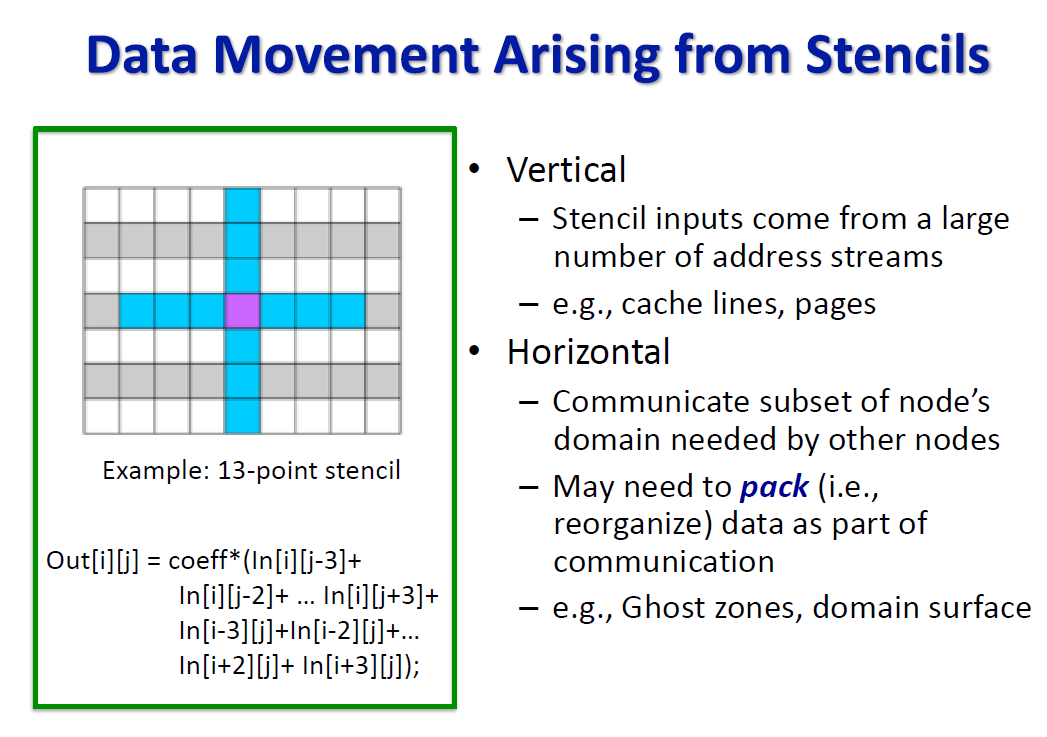
Figure 3: An example of horizontal and vertical data movement that arises in stencil operations. (Source: https://www.nitrd.gov/nitrdgroups/images/2/28/FACE-Mary-Hall-082020.pdf)
Vertical data movement in parallel can limit hardware prefetching effectiveness and cause both cache and TLB (Translation Lookaside Buffer) misses to the detriment of application performance. Horizontal data movement can incur data packing overhead – even inside a computational node – which can be as costly as sending the data over a network interconnect. Hall observes pack and unpack overhead can be a limiting factor for strong scaling behavior.
In contrast, the brick DSL is designed to work in parallel on stencil data layouts using bricks as the core unit of data. The combination provides a flexible organization that speeds computations by providing direct access to the data, which eliminates the overhead of costly pack() and unpack() operations. The end result is faster performance and improvements in scaling behavior plus it reduces the need for data movement both on- and off-node.
Internally the DSL uses a DAG (Directed Acyclic Graph) to generate code that is optimized for the destination machine. Key ideas include: associative reordering, reusing data whenever possible, and adapting the brick size to alleviate register pressure. Registers, especially on GPUs, are a scarce and valuable resource as they are the fastest memory that is closest to the on-chip computational units.
In addition, to maximize memory and communications performance, contiguous and memory mappable memory regions are utilized.
Results
In their August 2020, HPDC20 presentation High Performance is all about Minimizing Data Movement: A Software View, Hall’s team reports single node performance results over a wide range of stencil benchmarks in 2D and 3D across a variety of architectures.
Significant performance improvements are observed due to the benefits of better cache locality, register reuse, and the reduction of TLB pressure as shown in Figure 4.

Figure 4: Improvement in cache and TLB locality using the brick data layouts. (Source: https://www.nitrd.gov/nitrdgroups/images/2/28/FACE-Mary-Hall-082020.pdf)
Bricks also reduces the on-node communications between accelerators such as the NVIDIA V100 on Summit as shown in Figure 5.

Figure 5: Improved scaling with bricks through eliminating data marshalling for MPI (packing/unpacking) . (Source: https://www.nitrd.gov/nitrdgroups/images/2/28/FACE-Mary-Hall-082020.pdf)
Summary
DSLs are a power tool that programmers have historically used to create tools that address the widely varying computational requirements of simulations used by scientist’s as they model and analyze their particular application domain.
This PROTEAS-TUNE research demonstrates that stencil DSL and the brick data construct can not only generate code that delivers high application performance, they can also be used to support high performance portable applications for a wide variety of machine architectures. Such performance portable DSLs will certainly play an important role in supporting future HPC and exascale application efforts – especially given the ubiquity of stencils in scientific computing.
Rob Farber is a global technology consultant and author with an extensive background in HPC and in developing machine learning technology that he applies at national laboratories and commercial organizations. Rob can be reached at [email protected]
[i] Tuowen Zhao, Mary Hall, Hans Johansen, and Samuel Williams. 2021. Improving communication by optimizing on-node data movement with data layout. In Proceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming (PPoPP ’21). Association for Computing Machinery, New York, NY, USA, 304–317. DOI:https://doi.org/10.1145/3437801.3441598
[ii]Tuowen Zhao, Protonu Basu, Samuel Williams, Mary Hall, and Hans Johansen. 2019. Exploiting reuse and vectorization in blocked stencil computations on CPUs and GPUs. In <i>Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis (SC ’19). Association for Computing Machinery, New York, NY, USA, Article 52, 1–44. DOI:https://doi.org/10.1145/3295500.3356210
[iii] T. Zhao, S. Williams, M. Hall and H. Johansen, “Delivering Performance-Portable Stencil Computations on CPUs and GPUs Using Bricks,” 2018 IEEE/ACM International Workshop on Performance, Portability and Productivity in HPC (P3HPC), 2018, pp. 59-70, https://doi: 10.1109/P3HPC.2018.00009.
[iv] Chris Ding and Yun He. 2001. A ghost cell expansion method for reducing communications in solving PDE problems. In Proceedings of the 2001 ACM/IEEE conference on Supercomputing (SC ’01). Association for Computing Machinery, New York, NY, USA, 50. DOI:https://doi.org/10.1145/582034.582084